








zookeeper是一个分布式协调服务,
-
安装zookeeper首先我们要配置zookeeper,我们需要三台或以上虚拟机(单数),
修改配置文件zookeeper的配置文件conf下的配置文件进行修改
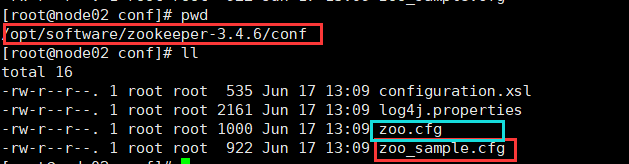
将zoo_sample.cfg复制并更名为zoo.cfg.cp zoo_sample.cfg zoo.cfg -
修改zoo.cfg文件

将标记蓝色的位置自定义路径,并且创建好目录,在目录下创建myid文件在其中输入1或2或3,取决于下面server.2 这个数字,数字对应的是哪个节点,哪个节点就写几

server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888在最后 加入集群的各个节点的信息
2888端口:是对外提供服务的端口号
3888端口:当leader挂掉之后,重新选择leader的时候提供对外通信 -
配置环境变量

export ZOOKERPER_HOME=/opt/software/zookeeper-3.4.6 export PATH=$PATH:$ZOOKERPER_HOME/bin配置完成后记得,让配置文件生效
source /etc/profile
Zookeeper工作机制
- 选举机制leader是根据选举产生的,每个follower进行投票,最后投票多的做为leader
采用的是逻辑时钟的方式进行选举 - 原子广播
1. 当有一个请求发送到集群时,由随机一个follower进行接收
2. flowwer将请求转发给leader
3. leader将请求下发给各个flowwer,进行投票
4. follower将自己的想法发返回给leader
少数服从多数
过半原则:我们的zookeeper结点最好是单数,这样减少重复投票 - zab协议
广播模式:已经选举出来的leader,开始对外提供服务
恢复模式:还没有选好leader(集群刚刚启动时,leader死了新的还没有上来)
1. looking --观望状态
2. following --跟随状态 follower出现了
3. leading --继承人(准备替补leader) leader
4. observing —这个监视leader的家伙出现了 observer - 角色
- leader 领导者,发起一个请求,让follower进行投票
- follower 跟随者,响应leader的请求并发起投票
- observer 监视者 ,监视着leader,并将leader的状态发送给follower
Zookeeper特点
- 最终一致性:为客户端展示同一个视图,这是Zookeeper里面一个非常重要的功能,不管在哪个节点,做包含的内容完全一致。
- 可靠性:如果消息被一台服务器接受,那么他会被所有的服务器接受。
- 实时性:Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sybc()接口。
- 独立性:各个Client之间互不干预。
- 原子性:更新只能成功或者失败,没有运行一半这一说。
- 顺序性:所有Server,同一消息发布顺序一致。















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









