







目录
一、缓冲流
-
缓冲流的概述
解析:
1.缓冲流是对4个基本的
FileXxx流的增强,所以也是4个流,按照流操作数据的数据类型分类:1.1字节缓冲流:
BufferedInputStream,BufferedOutputStream1.2字符缓冲流:
BufferedReader,BufferedWriter2.缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
-
字节缓冲流
1.构造方法:
1.public BufferedInputStream(InputStream in):作用 :创建一个 新的字节缓冲输入流。
2.public BufferedOutputStream(OutputStream out):作用: 创建一个新的字节缓冲输出流。
特别注意:缓冲区流是为了高效而设计的,缓冲区流本身仅仅是维护了一个数组。不具备读和写的功能。真正的读写还是要依赖普通的字节流。
使用代码演示:
// 创建字节缓冲输入流
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("D:\\飞思\\File\\144.mp4"));
// 创建字节缓冲输出流
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("D:\\飞思\\File\\aa\\1442.mp4"));2.字节缓冲流效率测试代码
具体代码:
package com.feisi.week6.day4;
import java.io.*;
/**
* @author 14491
* @version 1.0.0
* @description TODO
* @date 2022/8/18 9:37
*/
public class Test {
public static void main(String[] args) {
long start = System.currentTimeMillis();
pu();
long end = System.currentTimeMillis();
System.out.println("普通流的时间为:" + (end - start) + "ms");
System.out.println("-----------");
long start1 = System.currentTimeMillis();
hu();
long end1 = System.currentTimeMillis();
System.out.println("缓冲流的时间为:" + (end1 - start1) + "ms");
}
public static void pu() {
try {
FileInputStream fileInputStream = new FileInputStream("D:\\飞思\\File\\8月17日IO流-AM.mp4");
FileOutputStream fileOutputStream = new FileOutputStream("D:\\飞思\\File\\aa\\8月17日IO流-AM2.mp4");
byte b[] = new byte[1024];
int len = 0;
while ((len = fileInputStream.read(b)) != -1) {
// 把文件写入
fileOutputStream.write(b, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void hu() {
try {
//它也可以追加数据
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("D:\\飞思\\File\\8月17日IO流-AM.mp4"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("D:\\飞思\\File\\aa\\8月17日IO流-AM2.mp4"));
byte b[] = new byte[1024];
int len = 0;
while ((len = bufferedInputStream.read(b)) != -1) {
bufferedOutputStream.write(b, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
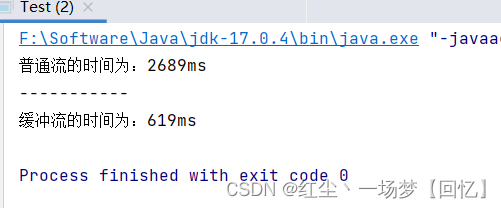
运行结果:根据结果我们可以看出没有使用缓冲流时所花时间巨大,由此我们在处理一些很大的文件时,应使用缓冲流来节省时间。
-
字符缓冲流
1.构造方法:
1.1public BufferedReader(Reader in):作用:创建一个 新的字符缓冲输入流。
1.2public BufferedWriter(Writer out):作用: 创建一个新的字符缓冲输出流。
使用演示:
// 创建字符缓冲输入流
BufferedReader bufferedReader = new BufferedReader(new FileReader("C:\\Users\\14491\\Desktop\\aa.txt"));
// 创建字符缓冲输出流
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("C:\\Users\\14491\\Desktop\\a.txt", true));2.字符缓冲流特有方法:
2.1BufferedReader:public String readLine():作用: 经常使用它读取一行数据。readLine方法可以按照行读取,读取的结束标记’\r’’\n’,返回的结果是读到这一行的所有文字。如果读取到文件的末尾返回 null。
2.2BufferedWriter:public void newLine():作用: 写一行行分隔符。就是换行。
使用字符缓冲流读写操作代码演示:
package com.feisi.week6.day4;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
public class Test1 {
public static void main(String[] args) {
// 使用字符缓冲流
try {
BufferedReader bufferedReader = new BufferedReader(new FileReader("C:\\Users\\14491\\Desktop\\aa.txt"));
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("C:\\Users\\14491\\Desktop\\a.txt", true));
String len = null;
while ((len = bufferedReader.readLine()) != null) {
bufferedWriter.write(len, 0, len.length());
// 换行符
bufferedWriter.newLine();
}
// 关闭资源
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
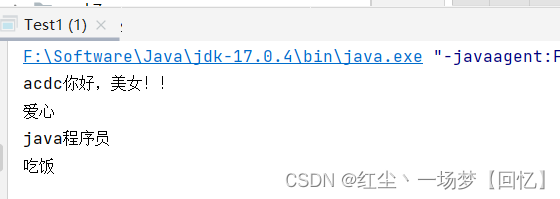
运行结果:
控住台输出读的结果:
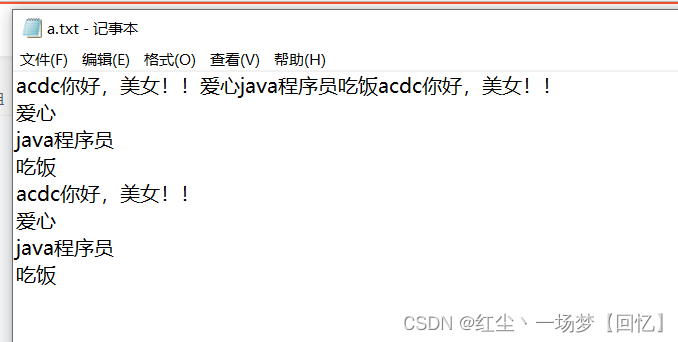
写入a.txt文件的结果:
二、转换流
-
转换流的概述
解析:
1.首先我们得了解一下什么是字符编码与字符集:
字符编码:
就是一套我们人类语言的字符与二进制数之间的对应规则。
字符集:
是一个系统支持的所有字符的集合,包括各国家文字、标点符号、数字等。
特别注意:当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
2.转换流的作用:1.指定读写的码表 2.可以把字节流对象变成字符流对象 3.解决乱码的现象出现。
-
InputStreamReader类
解析:
1.该类是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
1.构造方法:
1.1InputStreamReader(InputStram in):作用: 创建一个使用默认字符集的字符流。
1.2InputStreamReader(InputStram in,String charsetName):作用:创建一个指定字符集的字符流。
构造方法使用演示:
// 创建一个使用默认的字符集的转换流对象 默认使用utf-8
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream("bb.txt"));
// 创建一个使用GBK字符集的转换流对象
InputStreamReader inputStreamReader1 = new InputStreamReader(new FileInputStream("bb.txt"),"GBK");使用代码演示:
package com.feisi.week6.day4;
import java.io.*;
public class Test3 {
public static void main(String[] args) {
// 转换流的使用 给定的bb.txt文件编码是GBK
try {
// 创建默认转换流对象 使用utf-8
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream("bb.txt"));
// 创建指定转换流对象 使用GBK
InputStreamReader inputStreamReader1 = new InputStreamReader(new FileInputStream("bb.txt"),"GBK");
char c[] = new char[1024];
int len = 0;
// 使用默认的字符集 导致乱码
while ((len = inputStreamReader.read(c))!=-1){
System.out.println(new String(c,0,len));
}
inputStreamReader.close();
System.out.println("-------------");
// 使用给定的字符集 正常解析
while ((len = inputStreamReader1.read(c))!=-1){
System.out.println(new String(c,0,len));
}
inputStreamReader1.close();
} catch (FileNotFoundException | UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:

-
OutputStreamWriter类
解析:
1.该类是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码转换为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
1.构造方法:
1.1OutputStreamWriter(OutputStream in):作用: 创建一个使用默认字符集的字符流。
1.2OutputStreamWriter(OutputStream in,String charsetName):作用: 创建一个指定字符集的字符流。
使用演示:
// 使用默认的字符集
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream("bb.txt", true));
// 使用给定的字符集
OutputStreamWriter outputStreamWriter1 = new OutputStreamWriter(new FileOutputStream("bb.txt", true), "GBK");
转换流的输出代码演示:
package com.feisi.week6.day4;
import java.io.*;
public class Test4 {
public static void main(String[] args) {
// 转换输出流
try {
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream("bb.txt", true));
OutputStreamWriter outputStreamWriter1 = new OutputStreamWriter(new FileOutputStream("bb.txt", true), "GBK");
// 使用默认的字符集 乱码
outputStreamWriter.write("好好" + System.lineSeparator());
outputStreamWriter.close();
// 使用给定的字符集 正常解析
outputStreamWriter1.write("笑笑");
outputStreamWriter1.close();
} catch (FileNotFoundException | UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:

三、序列化流
-
序列化的概述
解析:
1.Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该
对象的数据、对象的类型和对象中存储的数据等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。2.反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。
对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。3.总之对象序列化与反序列化的作用:就是将内存中对象的信息写入到文件中进行持久化的保存,反序列化则是将文件中的序列化对象重行构造成对象来进行使用。
-
ObjectOutputStream类
解析:
1.该类的作用:将Java对象的原始数据类型写出到文件,实现对象的持久存储。
1.构造方法:public ObjectOutputStream(OutputStream out):作用: 创建一个指定OutputStream的ObjectOutputStream。
使用演示:
// 创建序列化对象流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("bb.txt",true));2.序列化操作:
2.1一个对象要想序列化,必须满足两个条件:
2.1.1该类必须实现java.io.Serializable 接口,Serializable 是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException 。
注意:只要一个类实现了Serializable接口,那么都会给每个实现类分配一个序列版本号作为唯一标识,这也是反序列化的关键所在。
2.1.2该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用transient 关键字修饰。
2.2 写出对象方法:使用public final void writeObject (Object obj) : 作用:将指定的对象写出到文件中。
序列化操作演示:
package com.feisi.week6.day4;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class Test5 {
public static void main(String[] args) {
Student student = new Student("小花",20);
// 序列化操作
try {
// 创建序列化对象流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("bb.txt",true));
// 将学生对象序列化写入文件中持久化保存
objectOutputStream.writeObject(student);
// 关闭资源
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
![]()
-
ObjectInputStream类
解析:
1.该类反序列化流类,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
2.反序列化:可以把序列化后的对象(硬盘上的文件中的对象数据),读取到内存中,然后就可以直接使用对象。这样做的好处是不用再一次创建对象了,直接反序列化就可以了。
1.构造方法:public ObjectInputStream(InputStream in):作用: 创建一个指定InputStream的ObjectInputStream。
使用演示:
// 创建反序列化流对象
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("cc.txt"));2.反序列化操作演示1:
package com.feisi.week6.day4;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class Test6 {
public static void main(String[] args) {
// 反序列化
try {
// 创建反序列化流对象
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("cc.txt"));
// 使用反序列化对象ois调用函数进行读取数据
Student s = (Student) objectInputStream.readObject();
// 将对象name属性内容输出
System.out.println(s.name);
// 关闭资源
objectInputStream.close();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
运行结果:
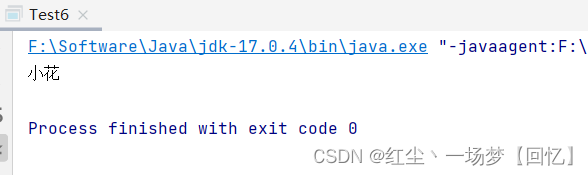
2.反序列化操作演示2:
特别注意:当在反序列化对象之前,我们对Student类做了一些简单的修改,无关紧要的修改。例如给Student类添加一个属性字段或者函数都可以,再次反序列化,就出问题了,报如下图所示的异常: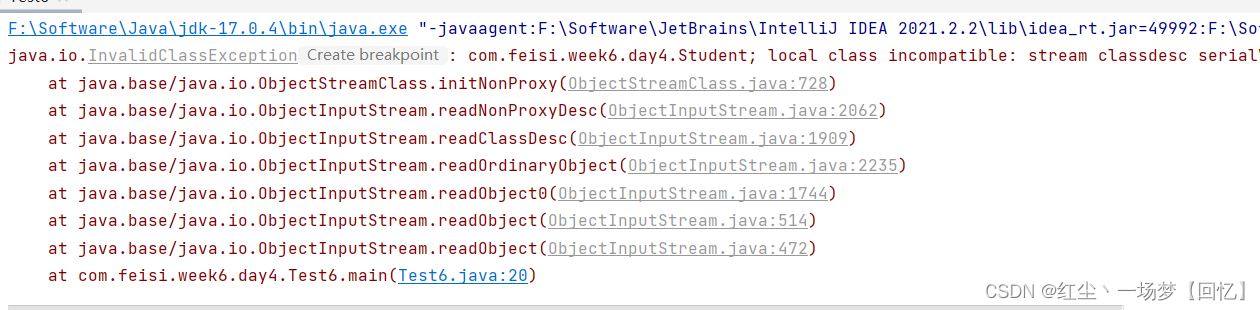
导致上述异常的原因是:我们在对存储文件中的对象进行反序列化之前,对它的类的内容做出了修改,这个时候就会导致该类的版本号与之前序列化对象的版本号有所差异,这才导致了上述的异常。
解决办法是:我们给我们的自定义类加上一个默认的版本号,即给Student类添加标记值也就是版本号serialVersionUID。但是,这样一来,类的安全问题,只能自己来维护。因为已经将类的对象序列化之后,由于类中已经显示定义了版本号,那么反序列化的时候即使修改了Student类,也不会报异常了。
在idea中给自定义类Student添加版本号方法如下所示:
点击File>>Setting然后按下图所示操作
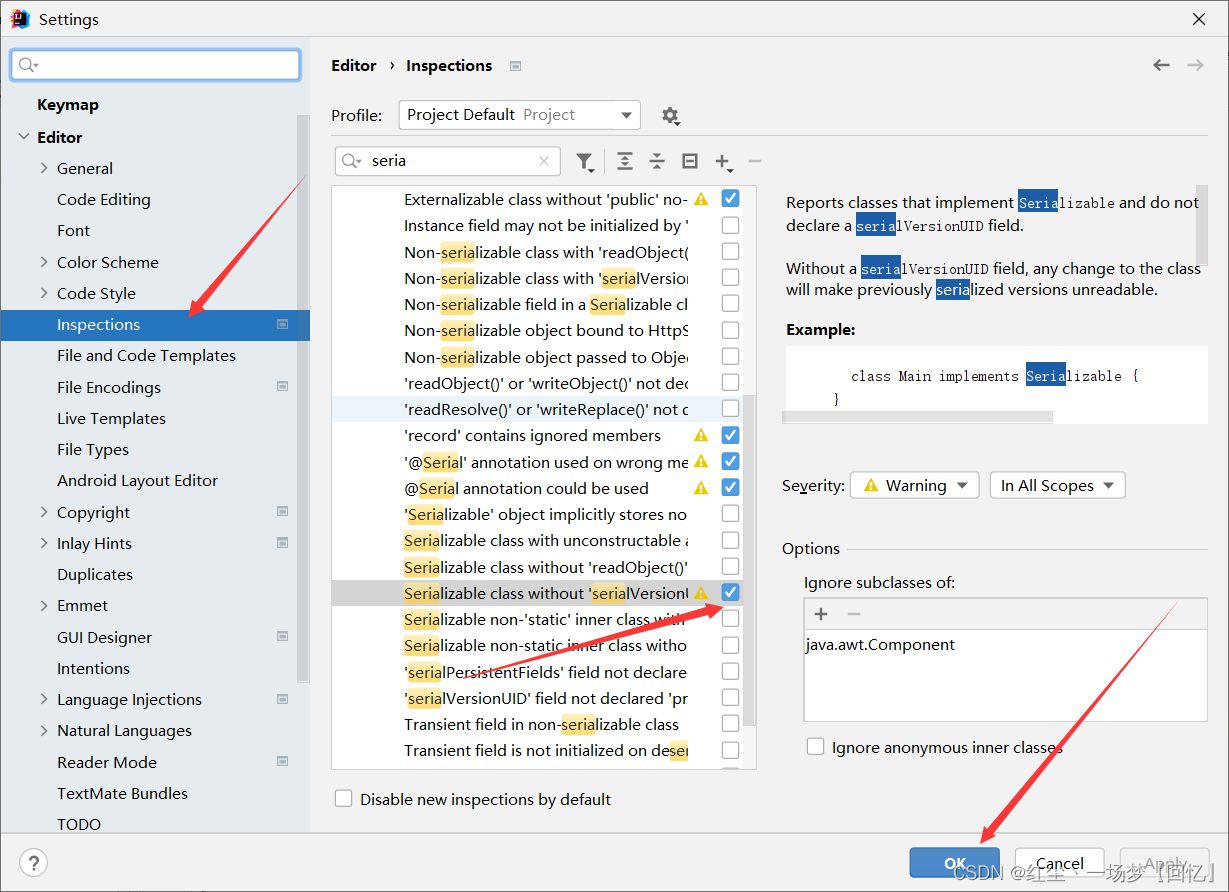
而后将光标停在实体类上按alt+enter键生成默认serialVersionUID号
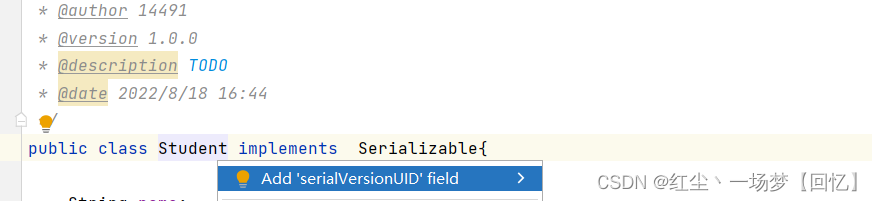 使用序列化总结:
使用序列化总结:
1.当一个对象需要被序列化 或 反序列化的时候对象所属的类需要实现Serializable接口。
2.被序列化的类中需要添加一个serialVersionUID。
3.当一个类可能会在以后做出内容修改时,这时可以生成一个默认的serialVersionUID,以防止修改之后的反序列化的类对象还能正常使用,但是需考虑安全性问题。
四、IO的异常处理
解析:
1.IO的异常处理分为jdk7以前和jdk以后的处理,jdk7以前的就不多说了都过时了,我们需要掌握jdk7以后的异常处理,方便我们以后的学习。
2.简单的来说就是jdk7以后的IO流操作类大部分都实现了AutoCloseable 接口,这个接口的主要作用就是只要IO流实现了这个接口,都可以完成自动释放资源,就不在需要我们在trycatch的时候非要在后面加个finally语句块用来关闭资源的操作,所谓的资源(resource)是指在程序完成后,必须关闭的对象。
3.使用格式:
try (创建流对象语句,如果多个流对象语句,使用';'隔开) {
// 读写数据
} catch (IOException e) {
e.printStackTrace();
}
代码使用演示:
package com.feisi.week6.day4;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
public class Test1 {
public static void main(String[] args) {
// 使用字符缓冲流
try (BufferedReader bufferedReader = new BufferedReader(new FileReader("C:\\Users\\14491\\Desktop\\aa.txt"));
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("C:\\Users\\14491\\Desktop\\a.txt", true))){
String len = null;
while ((len = bufferedReader.readLine()) != null) {
System.out.println(len);
bufferedWriter.write(len, 0, len.length());
// 换行符
bufferedWriter.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行效果:
















 2041
2041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









