










1.定义
对mlp的隐藏层增加噪音但不改变期望值,从而提高模型的泛化度,防止过拟合
2.原理
将施加了 dropout 的隐藏层的神经元分成两份,概率分别是第一份 p 和 第二份 1-p,第一份直接置为 0 降低期望,第二份统一除以 1-p 来提高期望,从而达到整体期望值不变的需求

也就是
E [ x i ′ ] = p ∗ 0 + ( 1 − p ) [ x i / ( 1 − p ) ] E[xi'] = p*0 + (1-p)[xi/(1-p)] E[xi′]=p∗0+(1−p)[xi/(1−p)]
E [ x i ′ ] = x i E[xi'] = xi E[xi′]=xi
约掉之后期望值不变,网络变成这个样子
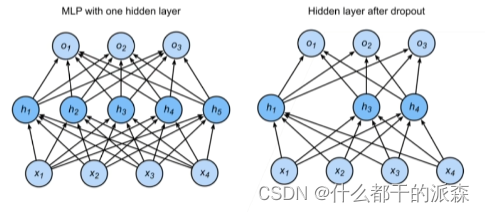
3.实现方式
使用Pytorch的现成方法
from torch import nn
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.3), # 丢弃3成
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.2), # 丢弃2成
nn.Linear(128, 10)
)
或者自己实现
import torch
def dropout(X, rate):
assert 0 <= rate <= 1 # 丢弃概率不在1-0之间直接抛异常
if rate == 1: # 丢弃概率为1时全部丢弃,返回与X同维度的全0张量
return torch.zeros_like(X)
elif rate == 0: # 丢弃概率为0时全部保留,返回X
return X
else: # 0<丢弃概率<1时,根据概率随机丢弃神经元并增加保留神经元的权重
mask = (torch.rand(X.shape) > rate).float()
return mask * X / (1.0 - rate)
if __name__ == '__main__':
# 生成张量
X = torch.rand(size=(3, 5))
print(X)
# tensor([[0.9695, 0.5501, 0.8937, 0.7924, 0.6007],
# [0.2121, 0.4906, 0.5322, 0.9305, 0.6586],
# [0.3558, 0.7379, 0.0585, 0.3683, 0.9134]])
# 不丢弃神经元
X_drop = dropout(X, 0)
print(X_drop)
# tensor([[0.9695, 0.5501, 0.8937, 0.7924, 0.6007],
# [0.2121, 0.4906, 0.5322, 0.9305, 0.6586],
# [0.3558, 0.7379, 0.0585, 0.3683, 0.9134]])
# 丢弃6成神经元
X_drop = dropout(X, 0.6)
print(X_drop)
# tensor([[0.0000, 1.3754, 0.0000, 0.0000, 1.5016],
# [0.5303, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 1.8447, 0.1462, 0.9206, 0.0000]])
# 丢弃全部神经元
X_drop = dropout(X, 1)
print(X_drop)
# tensor([[0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.]])
其中
mask = (torch.rand(X.shape) > rate).float()
return mask * X / (1.0 - rate)
这段代码的解释是
- 原张量
# tensor([[0.9695, 0.5501, 0.8937, 0.7924, 0.6007],
# [0.2121, 0.4906, 0.5322, 0.9305, 0.6586],
# [0.3558, 0.7379, 0.0585, 0.3683, 0.9134]])
- 经过 mask_tf = torch.rand(X.shape) > rate
# tensor([[ True, False, True, False, True],
# [False, False, False, True, True],
# [False, False, True, False, False]])
- 再转为浮点 mask = mask_tf.float()
# tensor([[1., 0., 1., 0., 1.],
# [0., 0., 0., 1., 1.],
# [0., 0., 1., 0., 0.]])
- mask * X 做掩码
# tensor([[0.0000, 0.5501, 0.0000, 0.0000, 0.6007],
# [0.2121, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.7379, 0.0585, 0.3683, 0.0000]])
- 除以(1.0 - rate) 增加权重
# tensor([[0.0000, 1.3754, 0.0000, 0.0000, 1.5016],
# [0.5303, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 1.8447, 0.1462, 0.9206, 0.0000]])
4.注意事项
- dropout 是个正则项,只在训练时生效,在预测时权重不需要发生变化,因此不生效 h = d r o p o u t ( h ) h = dropout(h) h=dropout(h),可以保证预测获得确定性的输出
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常用在mlp隐藏层的输出上
- 丢弃概率是控制模型复杂度的超参数
- dropout 可以提高泛化度防止过拟合
灵魂拷问
Q:那么 dropout 给多少合适呢
A:见过老中医抓药么(狗头)


















 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











