






一,决策树算法
1.什么是决策树算法
决策树(decision tree)是一种基本的分类和回归算法,决策树模型呈现树型结构,在分类问题中,是基于特征对实例进行分类的过程,他相当于是一棵用策略和判断构建起来的树。
2.要想了解决策树,首先要了解一下熵的概念。
(1).熵在化学中表达的是物质的混乱程度,而在决策树中表达的也是一种样本的混乱程度,混乱程度越大,则表示熵越大。
(2).熵的计算公式为:
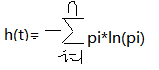
比如说下面这张图片
左边图形的熵为= -(1/3ln(1/3) + 4/9ln(4/9) + 2/9ln(2/9))
右边图形的熵为= -(1/8ln(1/8) + 7/8*ln(7/8))
随后我们发现左边的图形的熵要比右边图形的熵要大。
根据下图我们发现当一个数据中信息越混乱,它的pi越小则它的ln(pi)值越大,熵越大。
(3).再来了解一下信息增益的概念:信息增益表示它直接对应于结果,及y值对应的熵值 减去 它的每个子节点所对应的熵值,计算结果即为信息增益。
ID3: 信息增益
C4.5 信息增益率
CART:表示Gini系数
ID3计算公式:正如下图所表示的富不富直接对应的熵为h1 = -(1/8ln(1/8) + 1/2ln(1/2) + 3/8(3/8))
而当它化为白不白则它对应的的熵为h2 = -(1ln(1) + 3/4ln(3/4)).所以富不富的ID3 = h1 - h2

C4.5计算公式=h1 / h3

评价函数:C(T) =
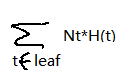
CART:Gini系数
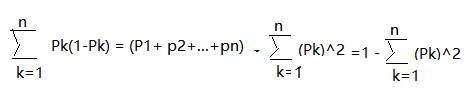
二. 随机森林
主要是由决策树组成,注意两个随机
1.随机从总样本里面抽取样本构成决策树
2.随机从样本里面的特征里面抽取特征
随机森林主要是利用群体决策,利用构成的每一个决策树来进行决策,进而达到提高准确率的目的。
















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









