









前言
最近正在忙一个比赛的项目,需要调用到豆瓣的图书API。通过图书的isbn的获取书籍的所有信息(https://api.douban.com/v2/book/isbn/ + 图书isbn)
但是想要做一个模拟真实环境的数据,需要大量的记录信息。然后查看当前的SQL语句是否能够跟得上正常速率。如果跟不上就进行数据库方面的调优。如:构建索引、分库分表、缓存、分布式、静态化技术(刚好最近也学到这方面,苦于没有试验的数据)
那么当需要大量的数据记录时,手动添加记录就不那么现实了。 这个时候就需要用到爬虫技术,正好以前也没有编写过爬虫,就当做一次学习记录了
实现
我使用的是PHP的CURL进行爬虫的编写,所以首先就是CURL的开启了
CURL开启
首先在php.ini中开启curl
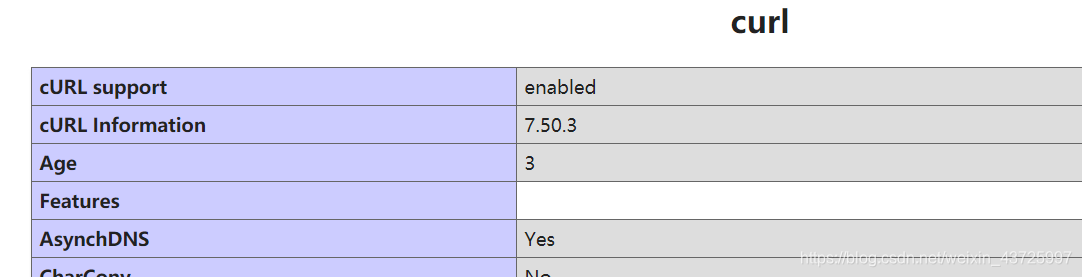
通过phpinfo查看。 开启成功
信息采集
接下来对我们需要爬取的信息做一个采集
https://book.douban.com/tag/文学
最开始,我是想以豆瓣的图书标签分类来进行爬取。但是由于我们调用的豆瓣API需要的是ISBN编号,在标签分类的页面下,并有图书ISBN的信息。所以就需要发送第二次HTTP请求,进入书籍的详细信息页面才能获取到图书的ISBN。
那么,这样一本书就需要两次HTTP请求,再加上分页的请求的。 发送请求的次数将会以指数级的速度上升。 爬虫的爬取的速度将会大大下降(因为豆瓣虽然对爬虫较为友好,但是一次性发送过多的HTTP请求,豆瓣还是会封IP的,所以在两次HTTP请求之间还要设置间断时间。)
所以我就考虑了另一种爬取方式。点击图书的详情页面查看时,可以看到豆瓣自定义了一个图书的编号,只要更改这个编号就可以做到只发送一次HTTP请求就可以获取到图书的ISBN编号,并且不需要进行分页查看。
https://book.douban.com/subject/6082808/
这种方式爬取的优缺点:
优点:一本图书只需要一次HTTP请求。 相比较第一种按图书分类标签爬取,一本图书就可以少去1~2次的请求(包括分页的获取) 爬取效率的提升是很明显的
缺点:图书没有按分类进行获取,排序是杂乱无章的。
根据个人实际需要,及业务需求。我目前是想要快速的获取大量的数据记录,好为数据库调优做准备。 所以暂时选用第二种速度快的爬取方式。 如果忙完后有机会,在对第一种按分类爬取的方式进行详细叙述。
爬虫编写
通过上面信息的采集,我们可以开始进行爬虫的编写了。
// 获取isbn编号
function getISBN($id,$count){
$i=0;
ob_start(); //打开缓冲区
while ($i < $count) {
// 豆瓣图书url地址
$url = "https://book.douban.com/subject/{$id}/";
// 请求初始化
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
curl_setopt($ch, CURLOPT_COOKIE, '{你的cookie信息}');
// 返回的信息
$output = curl_exec($ch);
if($output === false){
echo "CURL错误:".curl_error($ch);
}
// isbn截取
$start = strpos($output,"\"isbn\" :");
$isbn = substr($output, $start+10 , 13)."\r\n";
// 写入文件
$file = fopen("f:\\isbn.txt","a+");
fwrite($file, $isbn);
$id++;
$i++;
echo $id."<br>";
echo str_pad('',4096); //填充输出生成的字符串,字符串长度不达到缓冲区长度无法看到效果
ob_flush(); //刷新php buffer 缓冲
flush(); //刷新缓冲
sleep(2);
}
curl_close($ch); //关闭句柄
ob_end_flush(); //关闭缓冲区
}
$id = 1002720; //开始的id编号
$count = 5; //循环次数
getISBN($id,$count);
通过以上的代码,我们可以在F盘下的isbn.txt文件中看到我们爬取到的图书的ISBN信息了

接下来就是通过ISBN调用豆瓣API往数据库写入文件了。将会另外写一个如何调用,重新封装好的API文章。配合爬虫使用,快速获取大量的记录数














 3141
3141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









