







一、并行算法程序实现
在GEMM串行程序源码基础上,分别实现基于行列分块并行算法和cannon算法的两种MPI并行程序
代码debug阶段,采用的是M = N = P =4, np =4情况下进行验证,之后换成M = N = P = 16, np = 16再次验证
|| 0 1 2 3 || || 1 0 0 0 ||
|| 4 5 6 7 || || 0 1 0 0 ||
|| 8 9 10 11 || || 0 0 1 0 ||
|| 12 13 14 15 || || 0 0 0 1 ||
1、行列分块算法的程序实现
1.1 阻塞通信版本
- 相当于A分成4行,B分成4列,每个进程得到一个C,最后C拼起来就是答案
- 第一步:初始化AB
- 第二步:确定邻居进程
- 第三步:本地进程AB进行gemm运算
- 第四步:B向上收发子块
- 第五步:继续gemm运算,共迭代np次
- 第六步:收集D子块,打印
// 一维阻塞版本:sendrecv
// 一维阻塞版本:sendrecv
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#include<iostream>
#define np 1
#define M 64
#define N 64
#define P 64
#define SIZE M / np
#define UP 0
#define DOWN 1
#define TT 1
void print_myRows(int, float [][SIZE]);
void print_myRowsA(int , float myRows[][P]);
void print_myRowsB(int , float myRows[][SIZE]);
int main(int argc, char* argv[]){
int myid, size;
float myRowsA[SIZE][P], myRowsB[P][SIZE], myRowsC[SIZE][SIZE];
float myRowsD[SIZE][SIZE * np], tmp[SIZE][SIZE * np], c[M][N];
int nebor[2];
double start, end;
int tag_up = 0;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status status;
// 1. 数据初始化
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = 0;
}
}
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsB[i][j] = 0;
}
}
float cn = myid * SIZE * P;
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = cn ++;
}
}
// sleep(myid);
// print_myRowsA(myid, myRowsA);
int cnt = myid * SIZE;
for (int i = 0; i < SIZE; i ++) myRowsB[cnt + i][i] = 1.0;
// sleep(myid);
// print_myRowsB(myid, myRowsB);
// 2. 确定邻居进程
nebor[UP] = (myid == 0) ? np - 1: myid - 1;
nebor[DOWN] = (myid == np - 1) ? 0: myid + 1;
// 迭代开始,计时启动
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
for (int T = 0; T < np; T ++){
// 3. 本地进程当前子块A和B进行计算
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsC[i][j] = 0;
}
}
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
for (int k = 0; k < P; k ++){
myRowsC[i][j] += myRowsA[i][k] * myRowsB[k][j];
// 将结果放入D中
myRowsD[i][(T +myid) % np * SIZE + j] = myRowsC[i][j];
}
}
}
// sleep(myid);
// print_myRows(myid, myRowsC);
// 4. 发送和接收B子块
MPI_Sendrecv(&myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[UP], tag_up, &myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[DOWN], tag_up, MPI_COMM_WORLD, &status);
// MPI_Send(&myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[UP], tag_up, MPI_COMM_WORLD);
// MPI_Recv(&myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[DOWN], tag_up, MPI_COMM_WORLD, &status);
}
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
end = MPI_Wtime();
// 5. 收集D子块到tmp中,存放到c中
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE * np; j ++){
tmp[i][j] = myRowsD[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, SIZE * SIZE * np, MPI_FLOAT, c, SIZE * SIZE * np, MPI_FLOAT, 0, MPI_COMM_WORLD);
// 6. 输出汇总后的结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < M; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
printf("Result in process %d, Runtime = %f\n", myid, end-start);
MPI_Finalize();
return 0;
}
// 打印函数
void print_myRows(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsA(int myid, float myRows[][P]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < P; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsB(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < P;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
1.2 非阻塞通信版本
- 使用了
MPI_Isend函数,可以让通信和gemm计算重叠 - 如果是没有引入buff而是使用myRowsB进行传递,那么发送可以在gemm前,而接收必须在gemm后,因为gemm运算需要原始B
- 所以引入了buffB,则在计算gemm之前就可以开启
MPI_Isend``MPI_Irecv,gemm完成后MPI_Waitall接收完成
// 非阻塞通信版本:Isend 加上buff
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#include<iostream>
#define np 1
#define M 64
#define N 64
#define P 64
#define SIZE M / np
#define UP 0
#define DOWN 1
#define TT 1
void print_myRows(int, float [][SIZE]);
void print_myRowsA(int , float myRows[][P]);
void print_myRowsB(int , float myRows[][SIZE]);
int main(int argc, char* argv[]){
int myid, size;
float myRowsA[SIZE][P], myRowsB[P][SIZE], myRowsC[SIZE][SIZE];
float myRowsD[SIZE][SIZE * np], tmp[SIZE][SIZE * np], c[M][N];
int nebor[2];
double start, end;
float buffB[P][SIZE];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// MPI_Status status;
MPI_Status status[2], status1;
MPI_Request request[2];
// 1. 数据初始化
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = 0;
}
}
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsB[i][j] = 0;
}
}
float cn = myid * SIZE * P;
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = cn ++;
}
}
// sleep(myid);
// print_myRowsA(myid, myRowsA);
int cnt = myid * SIZE;
for (int i = 0; i < SIZE; i ++) myRowsB[cnt + i][i] = 1.0;
// sleep(myid);
// print_myRowsB(myid, myRowsB);
// 2. 确定邻居进程
nebor[UP] = (myid == 0) ? np - 1: myid - 1;
nebor[DOWN] = (myid == np - 1) ? 0: myid + 1;
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
for (int T = 0; T < np; T ++){
// 4. 发送和接收B子块
int tag_up = 0, tag_down = 1;
MPI_Isend(&myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[UP], tag_up, MPI_COMM_WORLD, &request[0]);
MPI_Irecv(&buffB[0][0], P * SIZE, MPI_FLOAT, nebor[DOWN], tag_up, MPI_COMM_WORLD, &request[1]);
// 3. 本地进程当前子块A和B进行计算
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsC[i][j] = 0;
}
}
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
for (int k = 0; k < P; k ++){
myRowsC[i][j] += myRowsA[i][k] * myRowsB[k][j];
myRowsD[i][(T +myid) % np * SIZE + j] = myRowsC[i][j];
}
}
}
// sleep(myid);
// print_myRows(myid, myRowsC);
MPI_Waitall(2, &request[0], &status[0]);
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsB[i][j] = buffB[i][j];
}
}
}
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
end = MPI_Wtime();
printf("Result in process %d, Runtime = %f\n", myid, end-start);
// 5. 收集D子块到tmp中,存放到c中
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE * np; j ++){
tmp[i][j] = myRowsD[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, SIZE * SIZE * np, MPI_FLOAT, c, SIZE * SIZE * np, MPI_FLOAT, 0, MPI_COMM_WORLD);
// 6. 输出汇总后的结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < M; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsA(int myid, float myRows[][P]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < P; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsB(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < P;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
1.3 重复非阻塞通信版本
- 和上述非阻塞版本类似,只不过把初始化提前,可以共用初始化
代码
// 重复非阻塞通信版本:MPI_Send_Init 加上buff
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#include<iostream>
#define np 4
#define M 16
#define N 16
#define P 16
#define SIZE M / np
#define UP 0
#define DOWN 1
#define TT 4
void print_myRows(int, float [][SIZE]);
void print_myRowsA(int , float myRows[][P]);
void print_myRowsB(int , float myRows[][SIZE]);
int main(int argc, char* argv[]){
int myid, size;
float myRowsA[SIZE][P], myRowsB[P][SIZE], myRowsC[SIZE][SIZE];
float myRowsD[SIZE][SIZE * np], tmp[SIZE][SIZE * np], c[M][N];
int nebor[2];
double start, end;
int buffsize = P * N * sizeof(float);
float buffB[P][SIZE];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// MPI_Status status;
MPI_Status status[2], status1;
MPI_Request request[2];
// 1. 数据初始化
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = 0;
}
}
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsB[i][j] = 0;
}
}
float cn = myid * SIZE * P;
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < P; j ++){
myRowsA[i][j] = cn ++;
}
}
// sleep(myid);
// print_myRowsA(myid, myRowsA);
int cnt = myid * SIZE;
for (int i = 0; i < SIZE; i ++) myRowsB[cnt + i][i] = 1.0;
// sleep(myid);
// print_myRowsB(myid, myRowsB);
// 2. 确定邻居进程
nebor[UP] = (myid == 0) ? np - 1: myid - 1;
nebor[DOWN] = (myid == np - 1) ? 0: myid + 1;
// 5. 初始化B的发送过程
int tag_up = 0;
MPI_Send_init(&myRowsB[0][0], P * SIZE, MPI_FLOAT, nebor[UP], tag_up, MPI_COMM_WORLD, &request[0]);
MPI_Recv_init(&buffB[0][0], P * SIZE, MPI_FLOAT, nebor[DOWN], tag_up, MPI_COMM_WORLD, &request[1]);
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
for (int T = 0; T < np; T ++){
// 4. 发送和接收B子块
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
buffB[i][j] = myRowsB[i][j];
}
}
MPI_Startall(2, &request[0]);
// 3. 本地进程当前子块A和B进行计算
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsC[i][j] = 0;
}
}
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
for (int k = 0; k < P; k ++){
myRowsC[i][j] += myRowsA[i][k] * myRowsB[k][j];
myRowsD[i][(T +myid) % np * SIZE + j] = myRowsC[i][j];
}
}
}
// sleep(myid);
// print_myRows(myid, myRowsC);
MPI_Waitall(2, &request[0], &status[0]);
for (int i = 0; i < P; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsB[i][j] = buffB[i][j];
}
}
// sleep(myid);
// print_myRowsB(myid, myRowsB);
}
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
end = MPI_Wtime();
printf("Result in process %d, Runtime = %f\n", myid, end-start);
// 5. 收集D子块到tmp中,存放到c中
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE * np; j ++){
tmp[i][j] = myRowsD[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, SIZE * SIZE * np, MPI_FLOAT, c, SIZE * SIZE * np, MPI_FLOAT, 0, MPI_COMM_WORLD);
// 6. 输出汇总后的结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < M; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsA(int myid, float myRows[][P]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < P; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
void print_myRowsB(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < P;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
2、cannon算法的程序实现
- 第一步:初始化A、B矩阵
- 第二步:建立笛卡尔坐标,确定邻居今称
- 第三步:初始对准,A向左移动i,B向上移动j
- 第四步:计算gemm
- 第五步:累加gemm结果
- 第六步:循环移位,A向左移动1,B向上移动1
- 第七步:重复循环sqrt(np)次
- 第八步:收集C子块
遇到的问题
- 移位的时候,邻居进程判断是正确的,但是有的进程接收或者发送不成功,会出错,因此在初始化的时候把
MPI_Sendrecv换成了MPI_Send``MPI_Recv这样每个都阻塞通信一定能保证初始化没问题 - 收集C子块,MPI_Gather`是按照进程顺序依次排布,和我们想要的二维分块是不一致的,因此采用的是收集是按照每个进程按行排布,然后对矩阵进行重排得到结果
代码
// Cannon版本
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#include<iostream>
#include<math.h>
#define np 16
#define M 16
#define N 16
#define P 16
#define UP 0
#define DOWN 1
#define LEFT 2
#define RIGHT 3
#define TT 4 //sqrt(np)
#define SIZE 4 // N / sqrt(np)
void print_myRows(int, float [][SIZE]);
int main(int argc, char* argv[]){
int myid, size;
float myRowsA[SIZE][SIZE], myRowsB[SIZE][SIZE], myRowsC[SIZE][SIZE];
float tmp[SIZE][SIZE], c[np][SIZE * SIZE], c1[M][N];
int nebor[2];
double start, end;
int buffsize = SIZE * SIZE * sizeof(float);
float buffA[SIZE][SIZE], buffB[SIZE][SIZE], buff[buffsize];
int dims[2] = {TT, TT};
int periods[2] = {0, 0};
int reorder = 0;
int coords[2];
int nbrs[4];
int position;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// MPI_Status status;
MPI_Status status[4], status1;
MPI_Request request[4];
MPI_Comm cartcomm;
// 为笛卡尔拓扑创建一个新的通信子
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, reorder, &cartcomm);
// 获取当前进程在通信子中的秩
MPI_Comm_rank(cartcomm, &myid);
// 笛卡尔转换函数,把秩转换成坐标
MPI_Cart_coords(cartcomm, myid, 2, coords);
// 1. 初始化二维进程网络
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsA[i][j] = myRowsB[i][j] = myRowsC[i][j] = 0;
}
}
int row = coords[0], col = coords[1];
float cn = row * SIZE * P + col * SIZE;
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsA[i][j] = cn + i * P + j;
}
}
if (row == col){
for (int i = 0; i < SIZE; i ++){
myRowsB[i][i] = 1.0;
}
}
// sleep(myid);
// print_myRows(myid, myRowsA);
// sleep(myid);
// print_myRows(myid, myRowsB);
// 2. 确定邻居进程
// 笛卡尔移位操作,获取当前坐标位置的上下位置秩
MPI_Cart_shift(cartcomm, 0, 1, &nbrs[UP], &nbrs[DOWN]);
// 笛卡尔移位操作,获取当前坐标位置的左右位置秩
MPI_Cart_shift(cartcomm, 1, 1, &nbrs[LEFT], &nbrs[RIGHT]);
// 3. 起始对准
int tag_left = 0, tag_up = 1;
int leftid = col, upid = row * TT;
int rightid = col, downid = row * TT;
if (row != 0){
leftid = row * TT + (col - row + TT) % TT;
rightid = row * TT + abs(col + row) % TT;
}
sleep(myid);
std::cout << "rank: " << myid << "leftid: " << leftid << "rightid: " << rightid << std::endl;
if (col != 0){
upid = (row - col + TT) % TT * TT + col;
downid = (row + col) % TT * TT + col;
}
sleep(myid);
std::cout << "rank: " << myid << "upid: " << upid << "downid: " << downid << std::endl;
if (row != 0){
MPI_Send(&myRowsA[0][0], SIZE * SIZE, MPI_FLOAT, leftid, tag_left, MPI_COMM_WORLD);
MPI_Recv(&myRowsA[0][0], SIZE * SIZE, MPI_FLOAT, rightid, tag_left, MPI_COMM_WORLD, &status1);
}
// MPI_Sendrecv(&myRowsA[0][0], SIZE * SIZE, MPI_FLOAT, leftid, tag_left, &myRowsA[0][0], SIZE * SIZE, MPI_FLOAT, rightid, tag_left, MPI_COMM_WORLD, &status1);
sleep(myid);
print_myRows(myid, myRowsA);
if (col != 0){
MPI_Send(&myRowsB[0][0], SIZE * SIZE, MPI_FLOAT, upid, tag_up, MPI_COMM_WORLD);
MPI_Recv(&myRowsB[0][0], SIZE * SIZE, MPI_FLOAT, downid, tag_up, MPI_COMM_WORLD, &status1);
}
// MPI_Sendrecv(&myRowsB[0][0], SIZE * SIZE, MPI_FLOAT, upid, tag_up, &myRowsB[0][0], SIZE * SIZE, MPI_FLOAT, downid, tag_up, MPI_COMM_WORLD, &status1);
sleep(myid);
print_myRows(myid, myRowsB);
leftid = (coords[1] == 0) ? (coords[0] + 1) * TT - 1: nbrs[LEFT];
rightid = (coords[1] == TT - 1) ? coords[0] * TT : nbrs[RIGHT];
upid = (coords[0] == 0) ? (TT - 1) * TT + coords[1]: nbrs[UP];
downid = (coords[0] == TT - 1) ? coords[1]: nbrs[DOWN];
MPI_Send_init(&myRowsA[0][0], SIZE * SIZE, MPI_FLOAT, leftid, tag_left, MPI_COMM_WORLD, &request[0]);
MPI_Recv_init(&buffA[0][0], SIZE * SIZE, MPI_FLOAT, rightid, tag_left, MPI_COMM_WORLD, &request[1]);
MPI_Send_init(&myRowsB[0][0], SIZE * SIZE, MPI_FLOAT, upid, tag_up, MPI_COMM_WORLD, &request[2]);
MPI_Recv_init(&buffB[0][0], SIZE * SIZE, MPI_FLOAT, downid, tag_up, MPI_COMM_WORLD, &request[3]);
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
for (int T = 0; T < TT; T ++){
// 4. 本地进程A与B进行gemm运算
MPI_Startall(4, &request[0]);
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
for (int k = 0; k < SIZE; k ++){
myRowsC[i][j] += myRowsA[i][k] * myRowsB[k][j];
}
}
}
// 5. 循环移位 向左1 向上1
MPI_Waitall(4, &request[0], &status[0]);
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
myRowsA[i][j] = buffA[i][j];
myRowsB[i][j] = buffB[i][j];
}
}
// sleep(myid);
// print_myRows(myid, myRowsA);
// sleep(myid);
// print_myRows(myid, myRowsB);
}
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
end = MPI_Wtime();
printf("Result in process %d, Runtime = %f\n", myid, end-start);
for (int i = 0; i < 4; i ++) MPI_Request_free(&request[i]);
// sleep(myid);
// print_myRows(myid, myRowsC);
// if (myid == 1) sleep(1);
for (int i = 0; i < SIZE; i ++){
for (int j = 0; j < SIZE; j ++){
tmp[i][j] = myRowsC[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, SIZE * SIZE, MPI_FLOAT, c, SIZE * SIZE, MPI_FLOAT, 0, MPI_COMM_WORLD);
int a, b;
for (int i = 0; i < np; i ++){
for (int j = 0; j < SIZE * SIZE; j ++){
a = i / TT * SIZE + j / SIZE;
b = i % TT * SIZE + j % SIZE;
c1[a][b] = c[i][j];
}
}
// 输出结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < M; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c1[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][SIZE]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE;i ++){
for (j = 0; j < SIZE; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
二、并行性能测试
对各版本算法的并行程序,进行强可拓展性测试,注意计算时间只统计内核gemm计算过程
- 多个并行规模:进程数量由少到多,如NP为1,2,4,8,16,64,100,144等
- 多个问题规模:小矩阵阶数,如M/N/P=512/512/512;大矩阵阶数,如M/N/P=5120/5120/5120,10240/10240/10240
- 不同算法版本之间,对比gemm计算时间及并行效率,分析、理解各类算法、各种通信版本的优势与不足
- 注意每次run的时候-n是不同的,每个节点大概只能算32500个数,大概都是在np的平方取得最优
Canon性能测试(gemm4_2.cpp)
| np\M | 64 | 128 | 256 | 360 | 512 | 720 | 1440 | 1800 | 2160 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.002370 | 0.022207 | |||||||
| 4 | 0.000870 | 0.006461 | 0.045871 | 0.188393 | |||||
| 16 | 0.003997 | 0.004410 | 0.012430 | 0.053079 | 0.095160 | 0.418262 | |||
| 64 | 0.099934 | 0.081955 | 0.076781 | 0.094775 | 1.390502 | ||||
| 100 | 0.421636 | 0.235959 | 0.243859 | 1.087101 | 2.240380 | ||||
| 144 | 0.318240 | 0.376280 | 1.080106 | 2.060123 | 4.015687 |
一维阻塞通信性能测试(gemm1_1.cpp)
| np\M | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|
| 1 | 0.003510 | 0.030969 | 0.300576 | 3.179691 | ||
| 4 | 0.001347 | 0.010547 | 0.060043 | 0.0651834 | ||
| 16 | 0.004510 | 0.002656 | 0.015044 | 0.0139472 | ||
| 64 | 0.115389 | 0.154423 | 0.071652 | 0.076781 | 0.418964 | |
| 100 | 0.908158(0.980470)(1000) | 4.395905(4.443350)(2000) | ||||
| 144 | 1.528170(1.640057)(1152) | 3.819908(3.938976)(2016) |
一维非阻塞通信性能测试(gemm2_2.cpp)
| np\M | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|
| 1 | 0.003787 | 0.03179 | 0.384921 | 4.174103 | ||
| 4 | 0.001299 | 0.008059 | 0.059592 | 0.533799 | 6.151261 | |
| 16 | 0.001653 | 0.002603 | 0.015693 | 0.153179 | 1.32524 | |
| 64 | 0.168553 | 0.448622 | 4.008370 | |||
| 100 | 0.587287(500) | 0.779388(1000) | 5.275981(2000) | |||
| 144 | 1.592765(576) | 1.483951(1152) | 3.939960(2016) |
一维重叠非阻塞通信性能测试(gemm3_1.cpp)
| np\M | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|
| 1 | 0.029649 | 2.2694 | ||||
| 4 | 0.001160 | 0.535309 | 6.455654 | |||
| 16 | 0.002762(0.012021) | 0.132543(0.142638) | 1.221950(1.223053) | 14.979193 | ||
| 64 | 0.084543(0.122887) | 0.522625(0.552587) | 4.068016 | |||
| 100 | 0.0799311(0.895811)(1000) | 5.820327(5.906116)(2000) | ||||
| 144 | 1.472875(1.594119)(1152) | 4.490045(4.620051)(2016) |
👍👍👍总结
- 512以下,Canon < 非阻塞<= 阻塞 < 重叠,这个时候计算比较小,等待通讯的时间比较长,所以
MPI_Waitall并不是很好;同时小进程表现良好,但是随着维数增大会有不断增大的np最优值出现 - 512以上,1000以上,2000一下,大进程有效,一维时间指数增长,阻塞 < 非阻塞 < 重叠;Canon增加缓慢,进程变大后效果比一维好
- 更大进程计算的时间一定大于通讯时间,所以重叠一定会有优势,Canon中也采用的重叠,会有更好的效果
- 由于矩阵太大计算不了,浅浅预估一下,所以并不是非阻塞或者重叠一定好,不同的进程也要匹配不同的矩阵,要根据矩阵大小而定
存在问题
- 一维分割必须得整除,维度和np是要能匹配上的
- 进程数比较小的时候,负载均衡问题比较小
- 负载均衡
一维阻塞
负载均衡问题
16 512

16 64
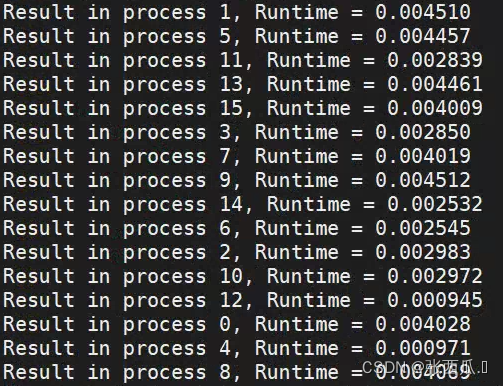
64 512
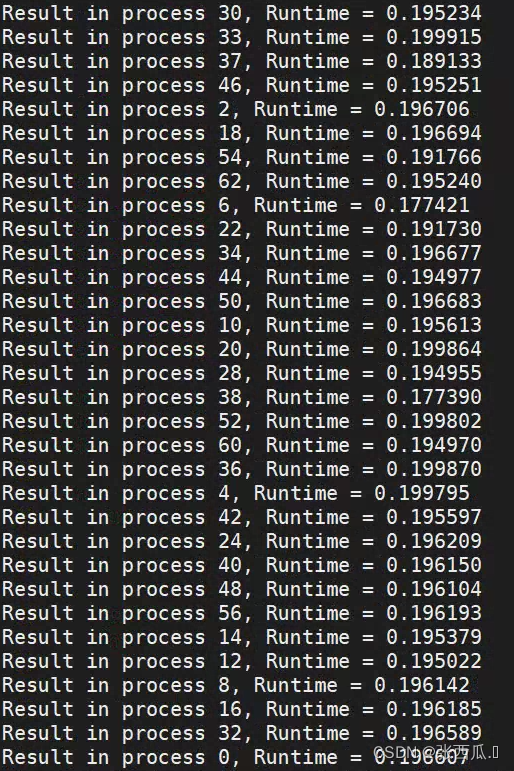
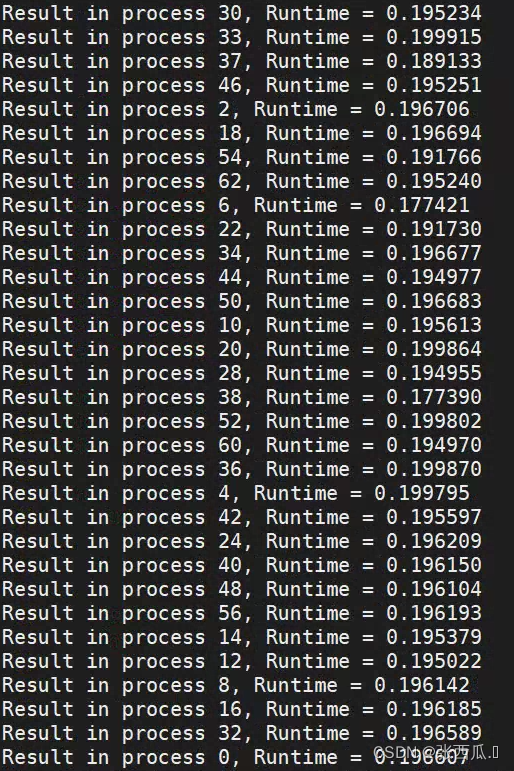
负载均衡在矩阵比较小和矩阵比较大时会出现偏差比较大的情况
GEMM 矩阵乘法
串行算法描述

- 矩阵太大怎么办?计算时间长 节点内存不够用
- 基于矩阵一维分块的行列划分并行算法
- 基于矩阵二维分块的cannon并行算法
行列划分并行算法(矩阵一维分块)
- 数据分块

np为处理器个, 对A和B进行分块,注意每个处理器中不一定是一行,可能是多行,所以得到C的都是subC子块而不是一个数.每个处理器从年初的是一个RowC,包含一行的subC - 计算
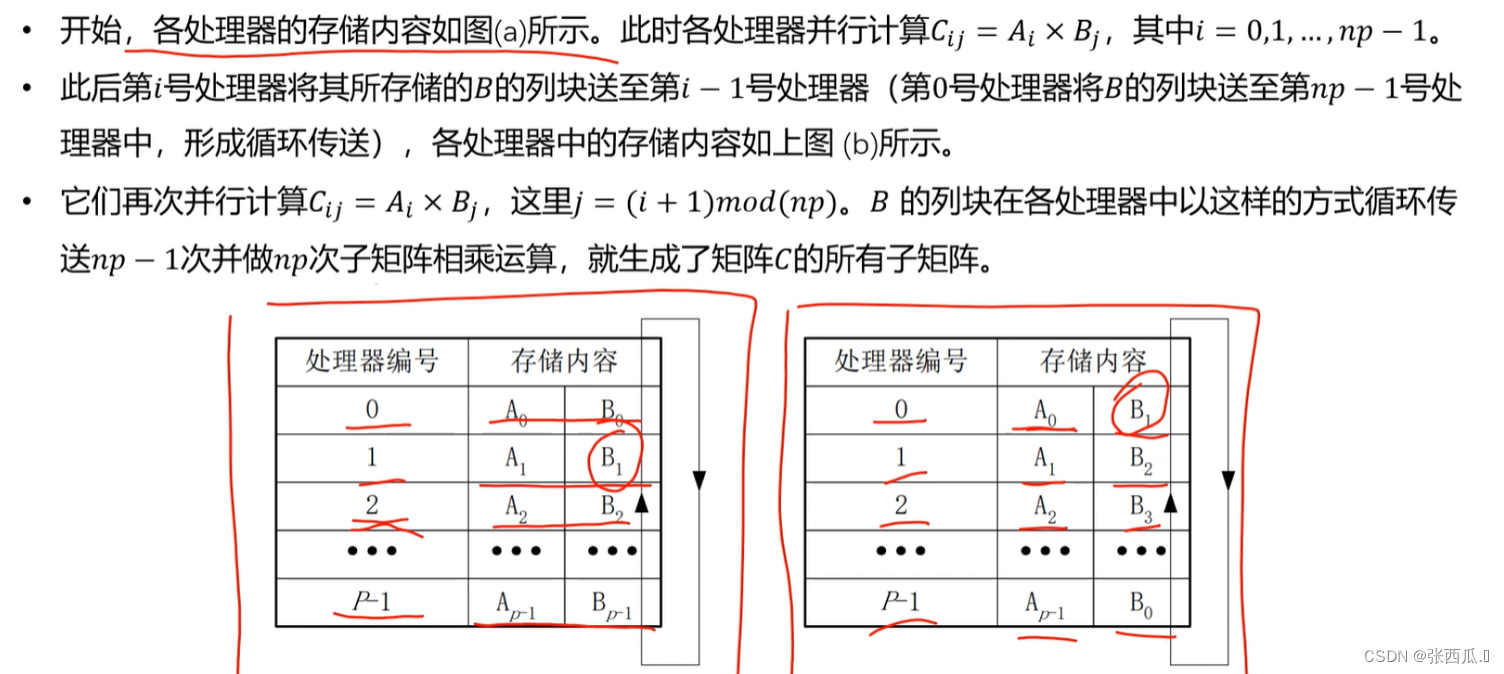
每次计算的是相同处理器的A和B,通过消息传递,能够让处理器内部计算,完成所有A和B的计算.
cannon并行算法(矩阵二维分块)
- 分块方式

相当于是一维的行块或列块,分割成更小的块了 - 思路推导

subA和subB相乘,然后再求和. - 基本思想
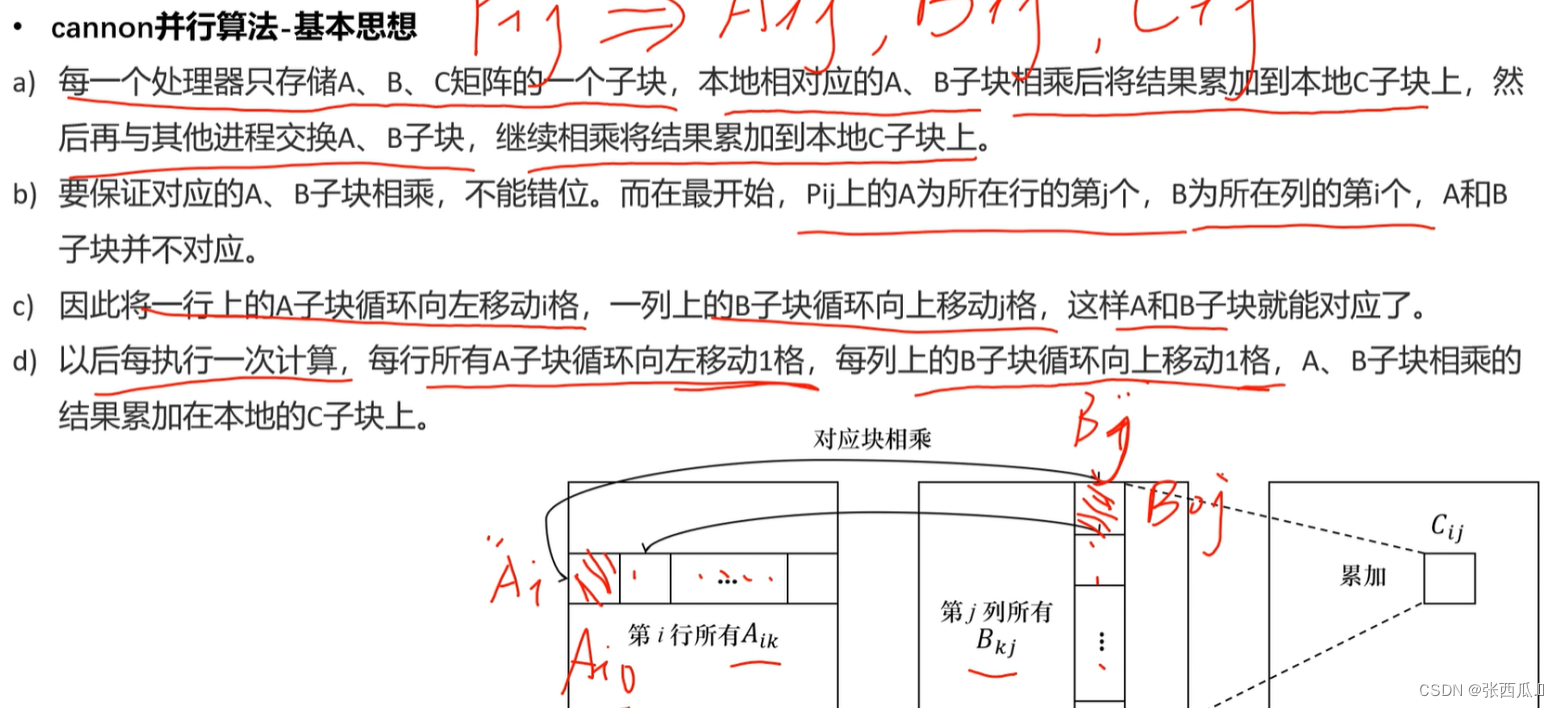
- 流程
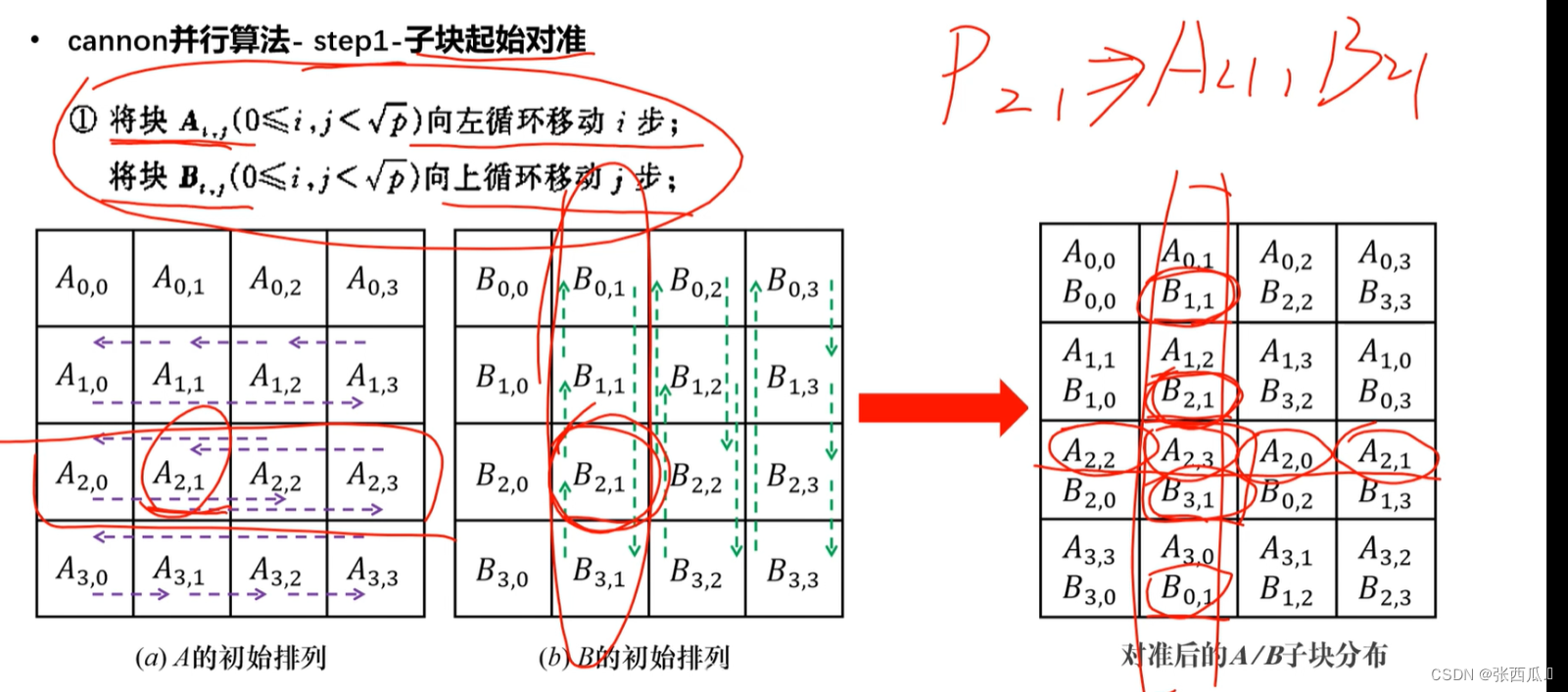
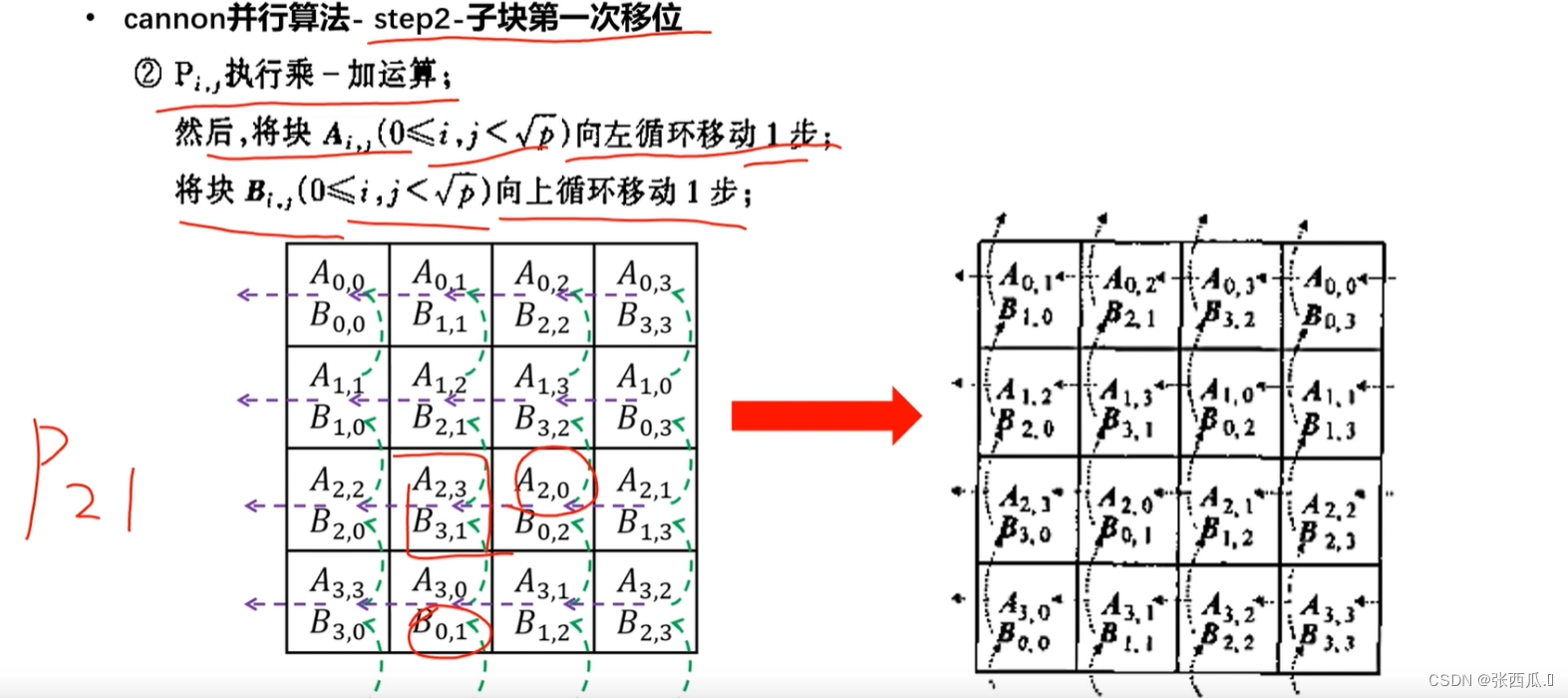

指标

如何提高并行效率

编程步骤
- 行列划分并行算法

- 阻塞接口实现版本


- 非阻塞接口实现版本

- 非阻塞接口——重叠通信和计算
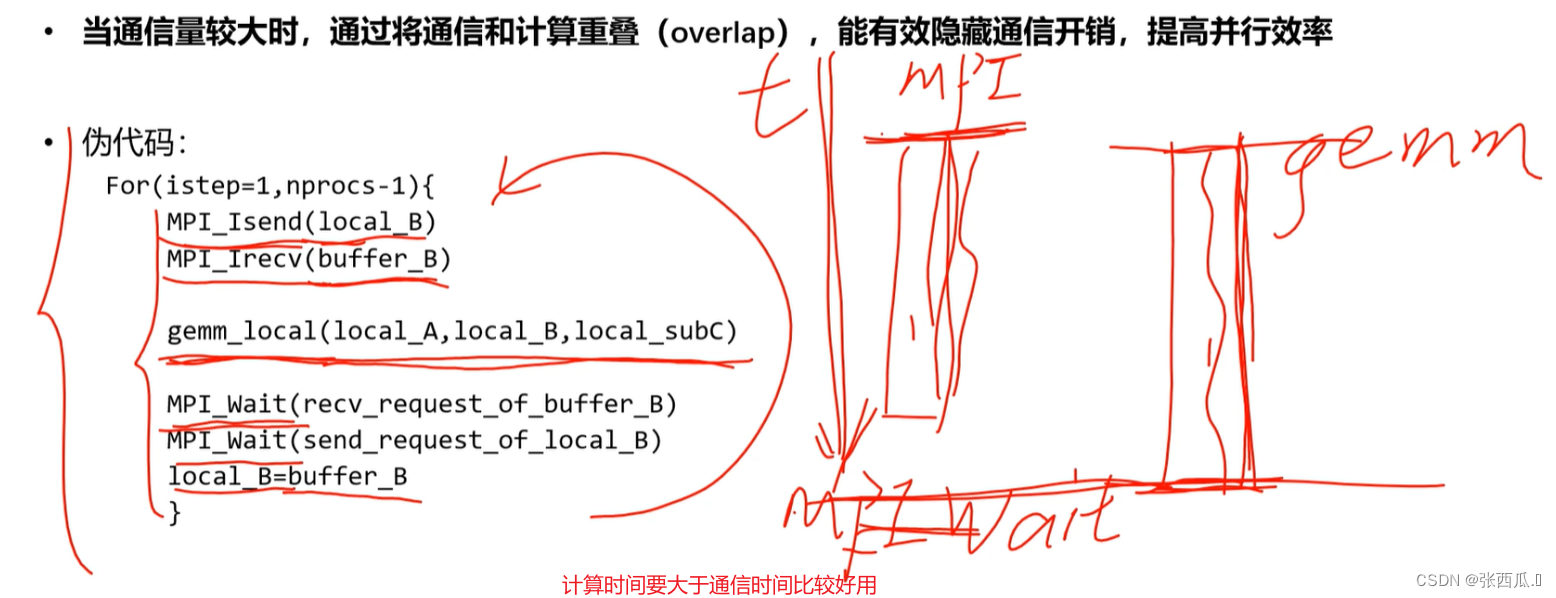
- 非阻塞接口——重复非阻塞通信
通讯的数据、邻居都是相同的等等

- 矩阵二维分块















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









