







Go语言字符串(string)
定义和说明
Go语言中,字符串(string类型)是 UTF-8 字符的序列(当字符为 ASCII 码表上的字符时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。
字符串是一个不可改变的字节序列,创建后不能再次修改,因为字符串本质上是用一个定长的字节数组实现的。
字符串的使用
var str1 string = "This is a string"
str2 := "这是一个字符串"
fmt.Println(str1)
fmt.Println(str2)
- 1
- 2
- 3
- 4
————
字符串的比较
字符串可以使用一般的比较运算符进行比较(==,!=,<,<=,>,>=)。
通过在内存中按字节比较来实现比较字符串。
比较的依据是字符串自然编码的顺序。
字符串的长度
使用len()函数,可以求字符串占用的字节长度。
注意是字节长度,如果一个字符串中的元素不全是ASCII表上的字符,那求出的结果和字符串元素的个数就不相同。
见下例:
tip1 = "shining star"
fmt.Println(len(tip1))
tip2 = "闪光的星球"
fmt.Println(len(tip2))
- 1
- 2
- 3
- 4

Go语言的字符串都是utf8格式保存的,采用Uncode编码,如果字符属于ASCII编码内,那么这个字符还是占用1字节,如果是中文,一般使用3个字节表示,因此这里用len求出的结果是15。
如果希望统计习惯上的字符个数,需要使用Go语言中UTF-8包提供的 RuneCountlnString()函数,统计Uncode字符数量。
tip1 := "shining star"
fmt.Println(utf8.RuneCountInString(tip1))
tip2 := "闪光的星球"
fmt.Println(utf8.RuneCountInString(tip2))
- 1
- 2
- 3
- 4
 一般游戏中在登录时都需要输入名字,而名字一般有长度限制。考虑到国人习惯使用中文做名字,就需要检测字符串 UTF-8 格式的长度。
一般游戏中在登录时都需要输入名字,而名字一般有长度限制。考虑到国人习惯使用中文做名字,就需要检测字符串 UTF-8 格式的长度。
————
使用索引获取字符串内容
字符串的内容(纯字节)可以通过标准索引法来获取,在方括号[ ]内写入索引,索引从 0 开始计数:
字符串 str 的第 1 个字节:str[0]
第 i 个字节:str[i - 1]
最后 1 个字节:str[len(str)-1]
需要注意:
- 这种转换方案只对纯 ASCII 码的字符串有效。
- 获取字符串中某个字节的地址属于非法行为,例如 &str[i]。
遍历字符串
遍历字符串有两种写法。
遍历每一个ASCII字符
theme := "闪光的 star"
for i := 0; i < len(theme); i++ {
fmt.Printf("ascii: %c %d\n", theme[i], theme[i])
}
- 1
- 2
- 3
- 4

这种模式下取到的汉字“惨不忍睹”。由于没有使用 Unicode,汉字被显示为乱码。
按Unicode字符遍历字符串
theme := "闪光的 star"
for _, s := range theme {
fmt.Printf("Unicode: %c %d\n", s, s)
}
- 1
- 2
- 3
- 4

————
字符串拼接符 “+”
两个字符串 s1 和 s2 可以通过 s := s1 + s2 拼接在一起。将 s2 追加到 s1 尾部并生成一个新的字符串 s。
拼接的方式如下:
str := "Beginning of the string " +
"second part of the string"
- 1
- 2
因为编译器会在行尾自动补全分号,所以拼接字符串用的加号“+”必和第一个字符串在同一行。
// 可以使用“+=”来对字符串进行拼接
s := "hel" + "lo,"
s += "world!"
fmt.Println(s) //输出 “hello, world!”
// 直接相加
s1,s2 := “hel” , “lo”
s := s1+s2
fmt.Println(s) //输出 “hello”
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
字符串截取
字符串索引比较常用的有如下几种方法:
- strings.Index:正向搜索子字符串。
- strings.LastIndex:反向搜索子字符串。
- 搜索的起始位置可以通过切片偏移制作。
tracer := "死神来了, 死神bye bye"
comma := strings.Index(tracer, ", ")
pos := strings.Index(tracer[comma:], "死神")
fmt.Println(comma, pos, tracer[comma+pos:])
- 1
- 2
- 3
- 4
程序输出如下:
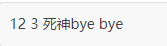
第 2 行尝试在 tracer 的字符串中搜索中文的逗号,返回的位置存在 comma 变量中,类型是 int,表示从 tracer 字符串开始的 ASCII 码位置。由程序输出可知,位置为12.
第3行中,tracer[comma:] 从 tracer 的 comma 位置开始到 tracer 字符串的结尾构造一个子字符串(“死神bye bye”),返回给 string.Index() 进行再索引。得到的 pos 是相对于 tracer[comma:] 的结果。
comma 逗号的位置是 12,而 pos 是相对位置,值为 3。我们为了获得第二个“死神”的位置,也就是逗号后面的字符串,就必须让 comma 加上 pos 的相对偏移,计算出 15 的偏移,然后再通过切片 tracer[comma+pos:] 计算出最终的子串,获得最终的结果:“死神bye bye”。
定义多行字符串
在Go语言中,使用双引号书写字符串的方式是字符串常见表达方式之一,被称为字符串字面量(string literal),这种双引号字面量不能跨行,如果想要在源码中嵌入一个多行字符串时,就必须使用`反引号(键盘上1左边的键),代码如下:
const str = `第一行
第二行
第三行
\r\n
`
fmt.Println(str)
- 1
- 2
- 3
- 4
- 5
- 6
执行结果:

在这种方式下,反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
因为在`间的所有代码均不会被编译器识别,而只是作为字符串的一部分。所以多行字符串一般用于内嵌源码和内嵌数据等。
————————————————————
Go语言字符类型
字符串**string类型中的每一个元素叫做“字符”,在遍历或者单个获取字符串元素时可以获得字符。Go语言有两种字符类型。
Go语言的字符有以下两种:
- 一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- 另一种是 rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型等价于 int32 类型。
uint8(byte)类型
uint8 类型,代表了 ASCII 码的一个字符。
byte 是uint8类型的别名,Go语言中,string类型中的每个字符默认为byte类型。
// 输出字母A
var ch1 byte = 65
var ch2 byte = '\x41'
fmt.Printlf("%c",ch1)
fmt.Printlf("%c",ch2)
- 1
- 2
- 3
- 4
- 5
int32(rune)类型
Go语言支持 Unicode(UTF-8),因此字符同样称为 Unicode 代码点或者 runes,并在内存中使用 int32 来表示。
在文档中,一般使用格式 U+hhhh 来表示,其中 h 表示一个 16 进制数。
在书写 Unicode 字符时,需要在 16 进制数之前加上前缀\u或者\U。
如果需要使用到 4 字节,则使用\u前缀,如果需要使用到 8 个字节,则使用\U前缀。
var ch int = '\u0041'
var ch2 int = '\u03B2'
var ch3 int = '\U00101234'
fmt.Printf("%d - %d - %d\n", ch, ch2, ch3) // integer
fmt.Printf("%c - %c - %c\n", ch, ch2, ch3) // character
fmt.Printf("%X - %X - %X\n", ch, ch2, ch3) // UTF-8 bytes
fmt.Printf("%U - %U - %U", ch, ch2, ch3) // UTF-8 code point
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出
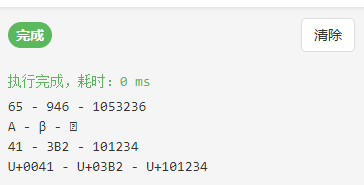
格式化说明符%c用于表示字符,当和字符配合使用时,%v或%d会输出用于表示该字符的整数,%U输出格式为 U+hhhh 的字符串。
————
Unicode 包中内置了一些用于测试字符的函数,这些函数的返回值都是一个布尔值,如下所示(其中 ch 代表字符):
- 判断是否为字母:unicode.IsLetter(ch)
- 判断是否为数字:unicode.IsDigit(ch)
- 判断是否为空白符号:unicode.IsSpace(ch)
参考文章
http://c.biancheng.net/view/17.html















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









