









k8s网络模型
Kubernetes 的网络利用了 Docker 的网络原理,并在此基础上实现了跨 Node 容器间的网络通信。

Kubernetes之POD、容器之间的网络通信
同一节点
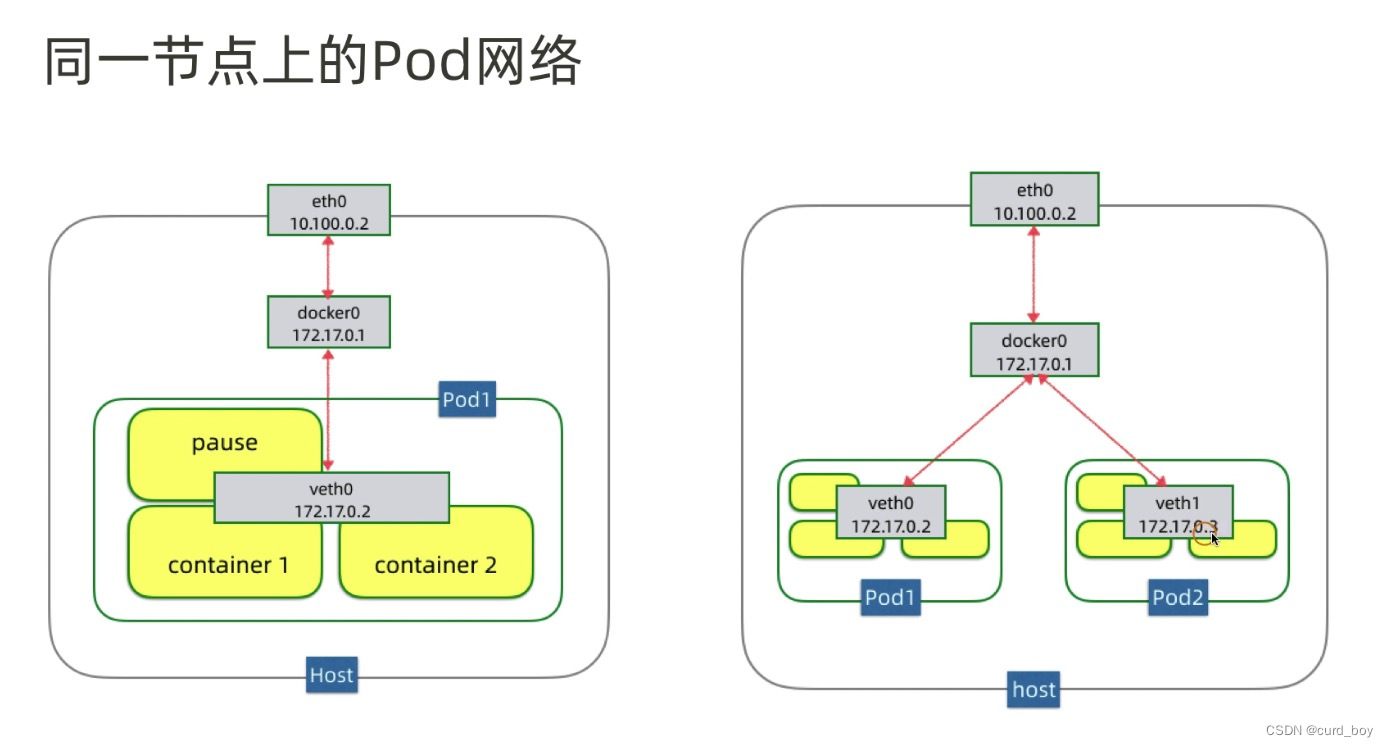
三个网络设备:
eth0: 节点主机网卡
docker0: docker网桥
veth0: 虚拟网卡
同一个POD上Container通信
在k8s中每个Pod容器有一个pause容器有独立的网络命名空间(netns),在Pod内启动Docker容器时候使用 –net=container就可以让当前Docker容器加入到Pod容器拥有的网络命名空间(pause容器)
这里就是为什么k8s在调度pod时,尽量把关系紧密的服务放到一个pod中,这样网络的请求耗时就可以忽略,因为容器之间通信共享了网络空间,就像local本地通信一样。
在k8s中每个Pod中管理着一组Docker容器,这些Docker容器共享同一个网络命名空间,Pod中的每个Docker容器拥有与Pod相同的IP和port地址空间,并且由于他们在同一个网络命名空间,他们之间可以通过localhost相互访问。
什么机制让同一个Pod内的多个docker容器相互通信?就是使用Docker的一种网络模型:–net=container
container模式指定新创建的Docker容器和已经存在的一个容器共享一个网络命名空间,而不是和宿主机共享。新创建的Docker容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等
同一个 Node 下 不同Pod 间通信模型:
pod与pod之间的网络:首先pod自身拥有一个IP地址,不同pod之间直接使用IP地址进行通信即可
正常交换路由通信
如容器⽹络模型⼀样,对于同⼀主机上的 pod 之间,通过 docker0 ⽹桥设备直接⼆层(数据链路层)⽹络上通过 MAC 地址直接通信:

veth(虚拟网络设备)
eth0(网卡)
pod1–>pod2(同一台node上),pod1通过自身eth0网卡发送数据,eth0连接着veth0,网桥把veth0和veth1组成了一个以太网,然后数据到达veth0之后,网桥通过转发表,发送给veth1,veth1直接把数据传给pod2的eth0。
不同pod之间的通信,就是使用linux虚拟以太网设备或者说是由两个虚拟接口组成的veth对使不同的网络命名空间链接起来,这些虚拟接口分布在多个网络命名空间上(这里是指多个Pod上)。
通过网桥把veth0和veth1组成为一个以太网,他们直接是可以直接通信的,另外这里通过veth对让pod1的eth0和veth0、pod2的eth0和veth1关联起来,从而让pod1和pod2相互通信。
不同节点
常见k8S容器互通网络方案就是两种,路由模式和覆盖网络overlay 隧道模式
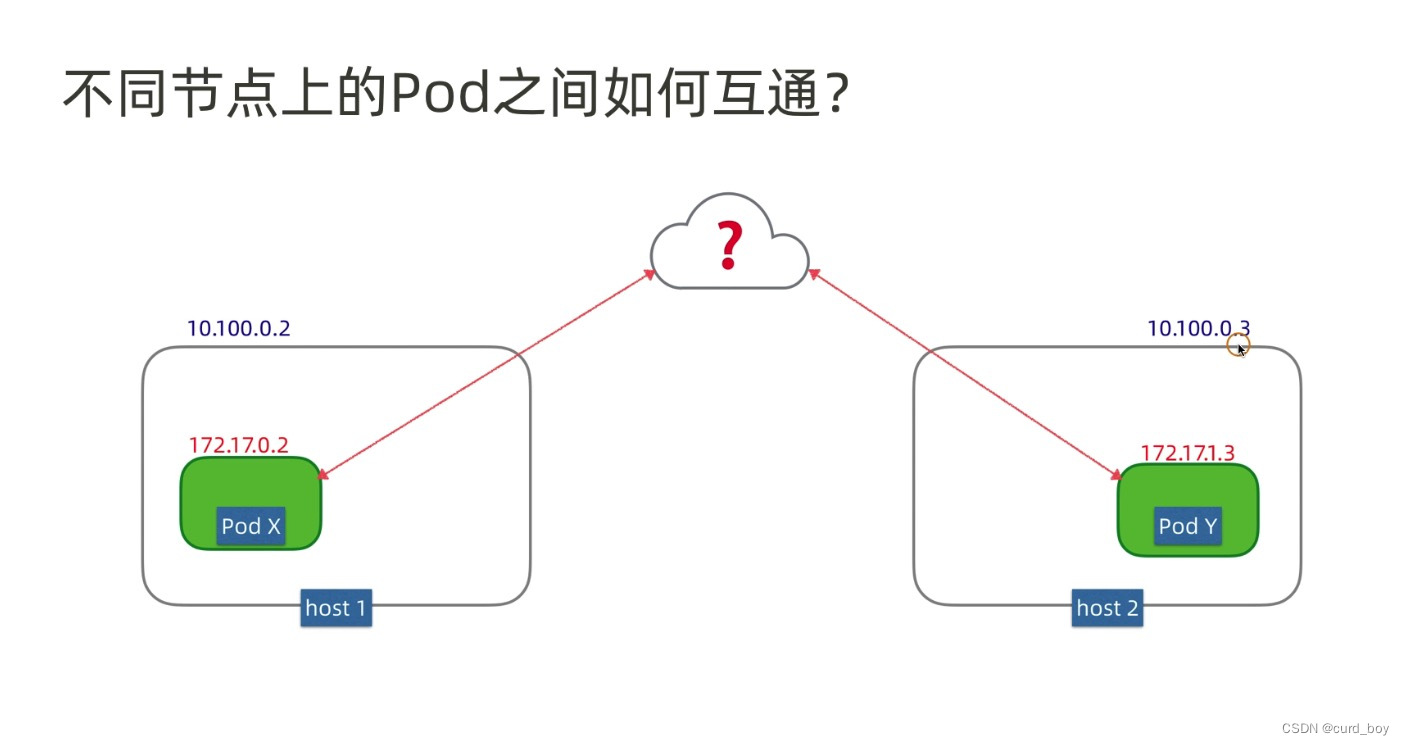
不同node节点上pod和pod通信
vxlan封装一层node ip进行普通路由交换
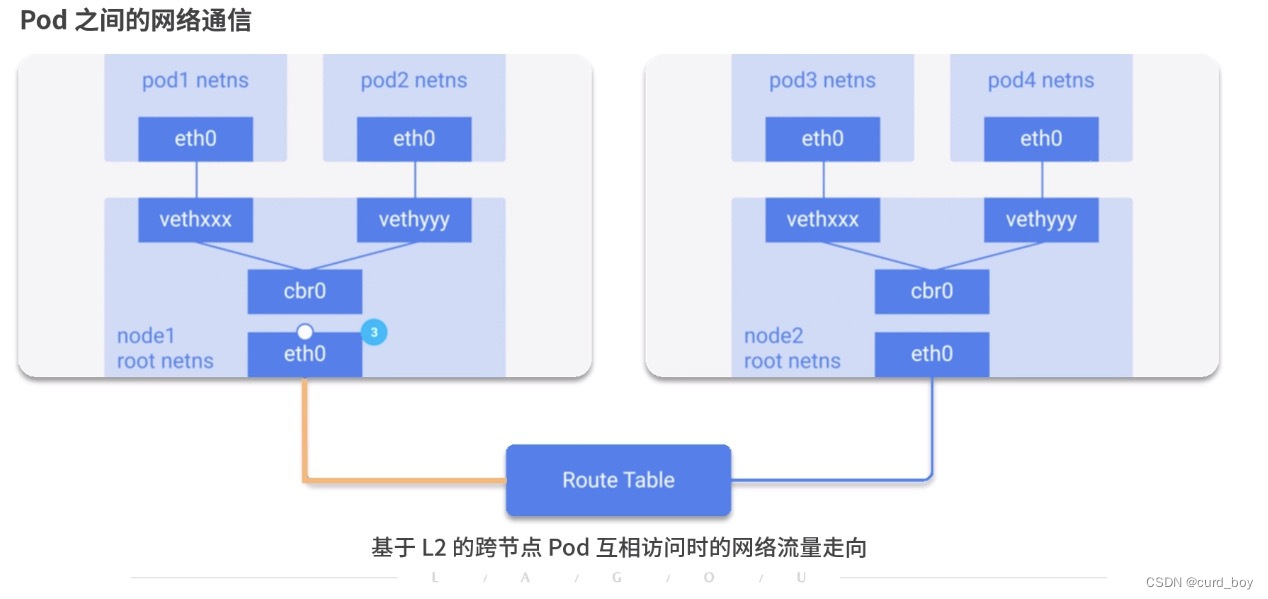
上图就是不同node之间的pod通信,Node1中的Pod1如何和Node2的Pod4进行通信的,我们来看看具体流程:
1)首先pod1通过自己的以太网设备eth0把数据包发送到关联到root命名空间的veth0上
2)然后数据包被Node1上的网桥设备(dcoker0)接收到,网桥查找转发表发现找不到pod4的Mac地址,则会把包转发到默认路由(root命名空间的eth0设备)
3)然后数据包经过eth0(主机网卡)就离开了Node1,被发送到网络。
4)数据包到达Node2后,首先会被root命名空间的eth0设备
5)然后通过网桥把数据路由到虚拟设备veth1,最终数据表会被流转到与veth1配对的另外一端(pod4的eth0)
每个Node都知道如何把数据包转发到其内部运行的Pod,当一个数据包到达Node后,其内部数据流就和Node内Pod之间的流转类似了
k8s网络接口 CNI
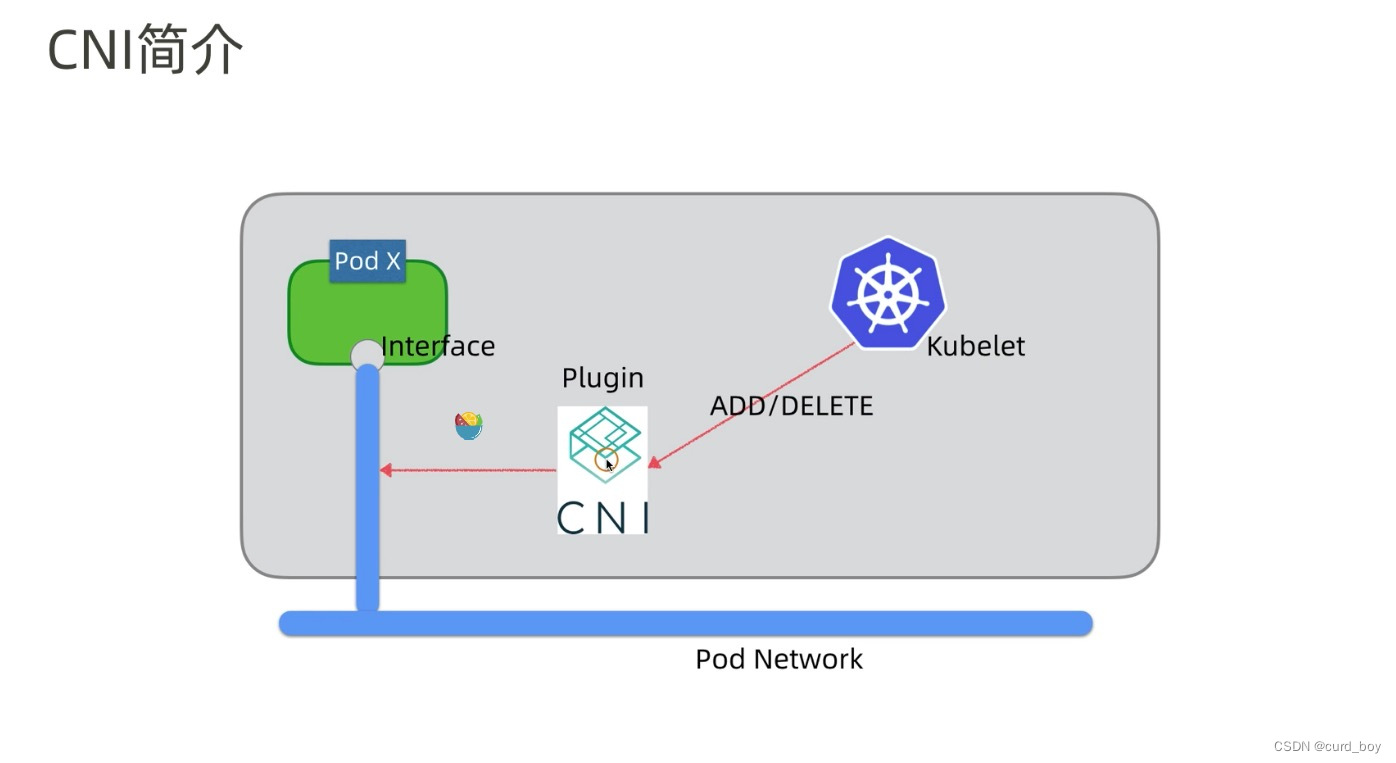
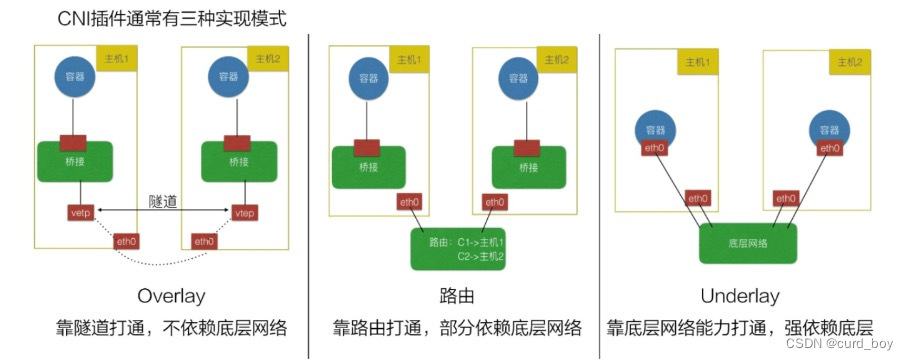
- Overlay 模式的典型特征是容器独⽴于主机的 IP 段,这个 IP 段进⾏跨主机⽹络通信时是通过在主机之间创建隧道的⽅式,将整个容器⽹段的包全都封装成底层的物理⽹络中主机之间的包。该⽅式的好处在于它不依赖于底层⽹络;
- 路由模式中主机和容器也分属不同的⽹段,它与 Overlay 模式的主要区别在于它的跨主机通信是通过路由打通,⽆需在不同主机之间
做⼀个隧道封包。但路由打通就需要部分依赖于底层⽹络,⽐如说要求底层⽹络有⼆层可达的⼀个能⼒; - Underlay 模式中容器和宿主机位于同⼀层⽹络,两者拥有相同的地位。容器之间⽹络的打通主要依靠于底层⽹络。因此该模式是强依赖于底层能⼒的。
路由网络
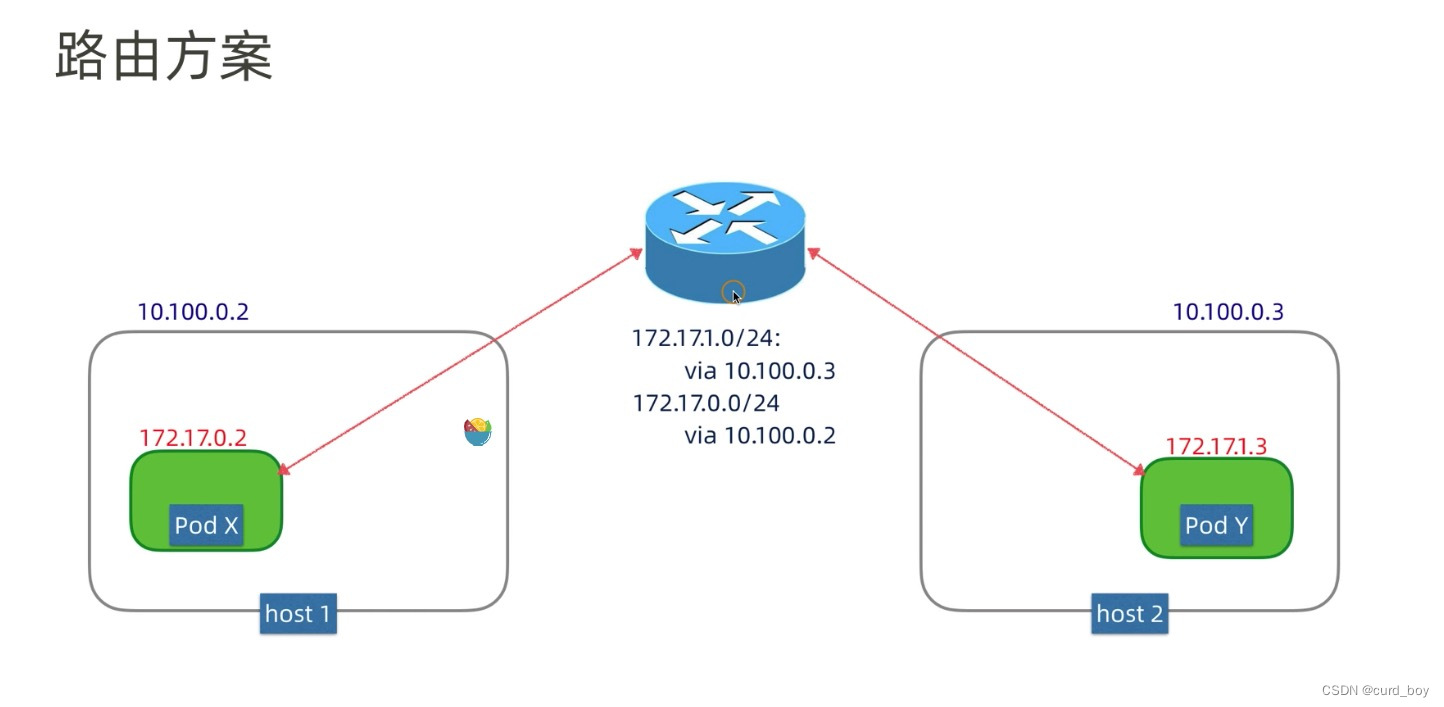
修改主机路由:把容器⽹络加到主机路由表中,把主机⽹络设备当作容器⽹关,通过路由规则转发到指定的主机,实现容器的三层互通。
⽬前通过路由技术实现容器跨主机通信的⽹络如 Flannel host-gw、Calico 等
覆盖网络

隧道传输(overlay):将容器的数据包封装到原主机⽹络的三层或者四层数据包中,然后使⽤主机⽹络的 IP 或者 TCP/UDP 传输到⽬标主机,⽬标主机拆包后再转发给⽬标容器。overlay 隧道传输常见⽅案包括 Vxlan、ipip 等,⽬前使⽤ overlay 隧道传输技术的主流容器⽹络有 Flannel 等;
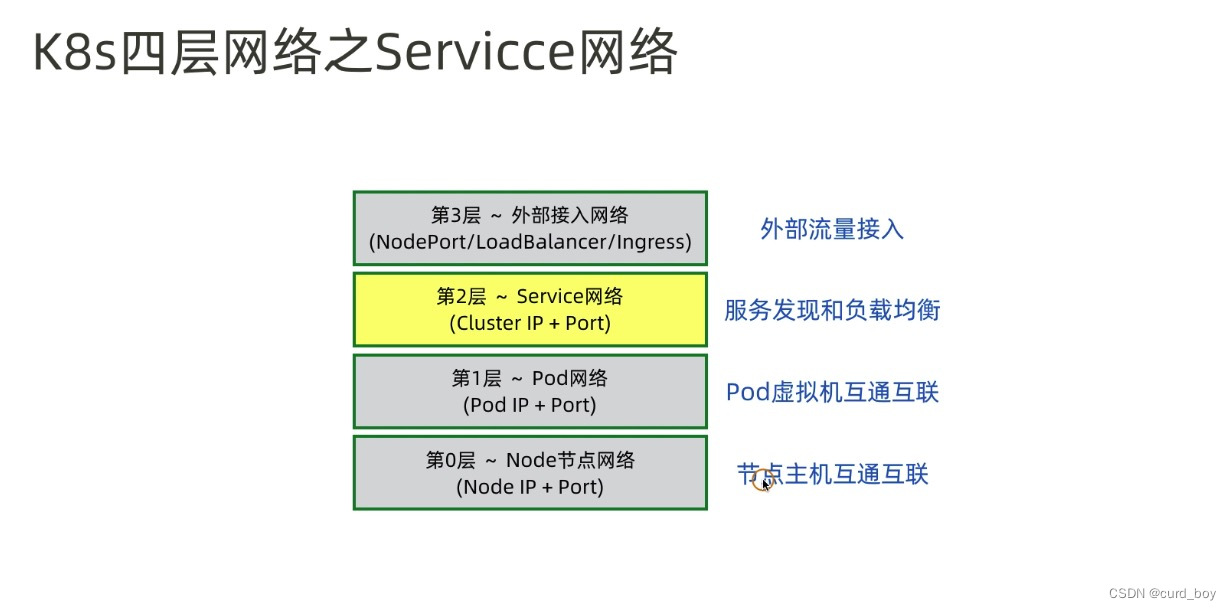
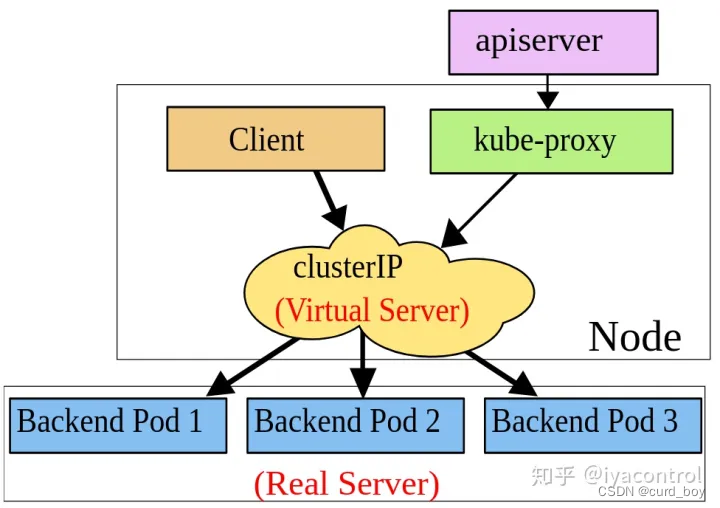
pod与service之间的网络
pod的ip地址是不持久的,当集群中pod的规模缩减或者pod故障或者node故障重启后,新的pod的ip就可能与之前的不一样的。所以k8s中衍生出来Service来解决这个问题。
Service管理了多个Pods,每个Service有一个虚拟的ip,要访问service管理的Pod上的服务只需要访问你这个虚拟ip就可以了,这个虚拟ip是固定的,当service下的pod规模改变、故障重启、node重启时候,对使用service的用户来说是无感知的,因为他们使用的service的ip没有变。
当数据包到达Service虚拟ip后,数据包会被通过k8s给该servcie自动创建的负载均衡器路由到背后的pod容器。
在k8s里,iptables规则是由kube-proxy配置,kube-proxy监视APIserver的更改,因为集群中所有service(iptables)更改都会发送到APIserver上,所以每台kubelet-proxy监视APIserver,当对service或pod虚拟IP进行修改时,kube-proxy就会在本地更新,以便正确发送给后端pod
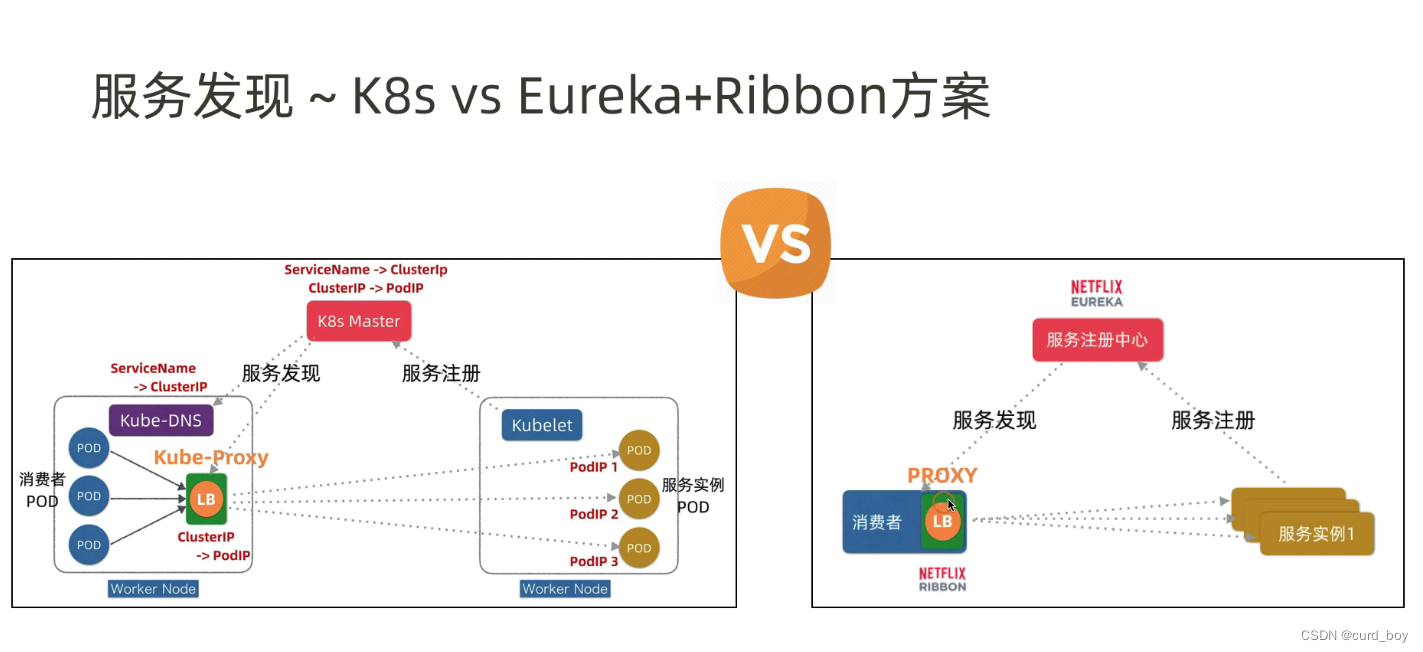
Service网络
Ingress
Ingress构成
Ingress 主要有两部分组成:
- Ingress 对象:提供 Ingress kubernetes 对象,能够通过 yaml 进行创建和更新,用于将服务与域名对应起来;
- Ingress Controller:部署在集群中的公共组件,将 Ingress 服务的配置转化成外部负载均衡的配置,对负载均衡器进行管理和更新。
Ingress 实现原理
在Ingress的使用过程中,常常会遇到一些问题,比如客户端访问偶尔报:“502”或“504”错误、域名证书配置不生效、获取不到客户端真实IP地址等。
了解Ingress路由的实现原理,对于解决Ingress各种问题十分有帮助。本节将讲解Ingress是如何实现复杂的七层路由策略的。
以阿里云的Ingress组件为例,Ingress可以分为三个部分,分别是入口SLB(由Nginx-ingress-lb这个Service创建)、控制器以及Nginx代理,如下图所示。
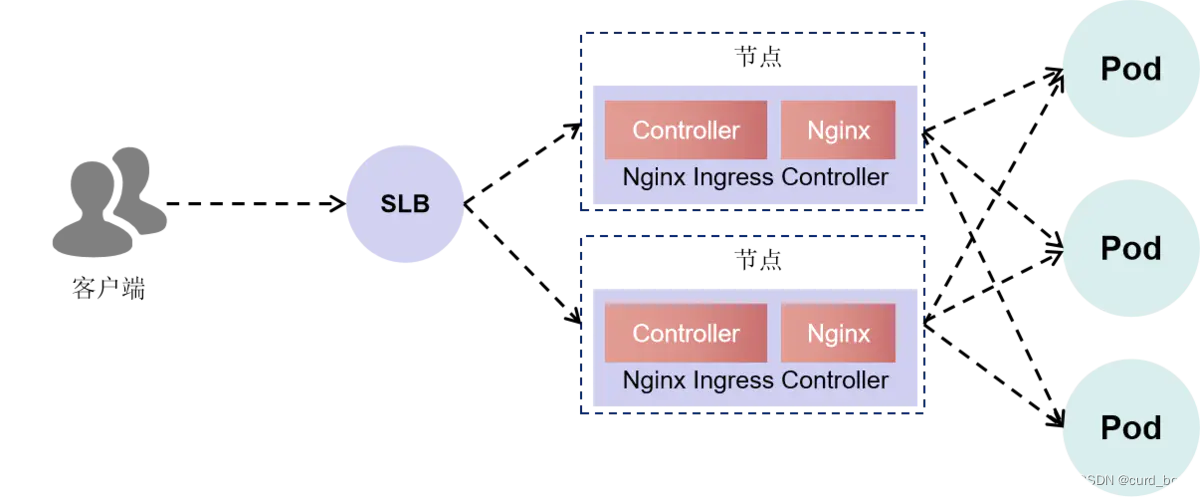
Ingress的实现包含了两部分内容,一个是Controller,即Ingress控制器,另一个是Nginx代理。当创建一个Ingress对象的时候,控制器会作为Ingress对象和Nginx之间的翻译官,把Ingress中定义的路由配置转换为Nginx的配置。
如果Ingress定义有错误,翻译工作会失败,导致最新的规则没有办法下发到Nginx里。控制器日志的Nginx的Access/Error日志,都会汇总到Nginx
Ingress Controller这个Pod的标准输出,可以从Pod的标准输出查看控制器的日志或者Nginx的访问日志。
一般情况下,如果需要查看生效的Nginx配置,我们可登录到Nginx Ingress Controller容器里,查看配置文件/etc/nginx/nginx.conf。
为了减少对Nginx配置高频率加载这样的操作,Nginx Ingress Controller引入了Lua模块。Lua模块可以协助Nginx低“成本”地更新Upstream,以避免此类操作对业务的影响。
在Ingress控制器里获取Lua配置的方法如下。
-
进入Pod。
kubectl -n kube-system exec -ti nginx-ingress-controller-7d7c69b5b8-d7qxw /bin/bash
-
查看配置
cur lhttp://127.0.0.1:10246/configuration/backends
https://www.jianshu.com/p/727e5aa93c58
ingress流量分析
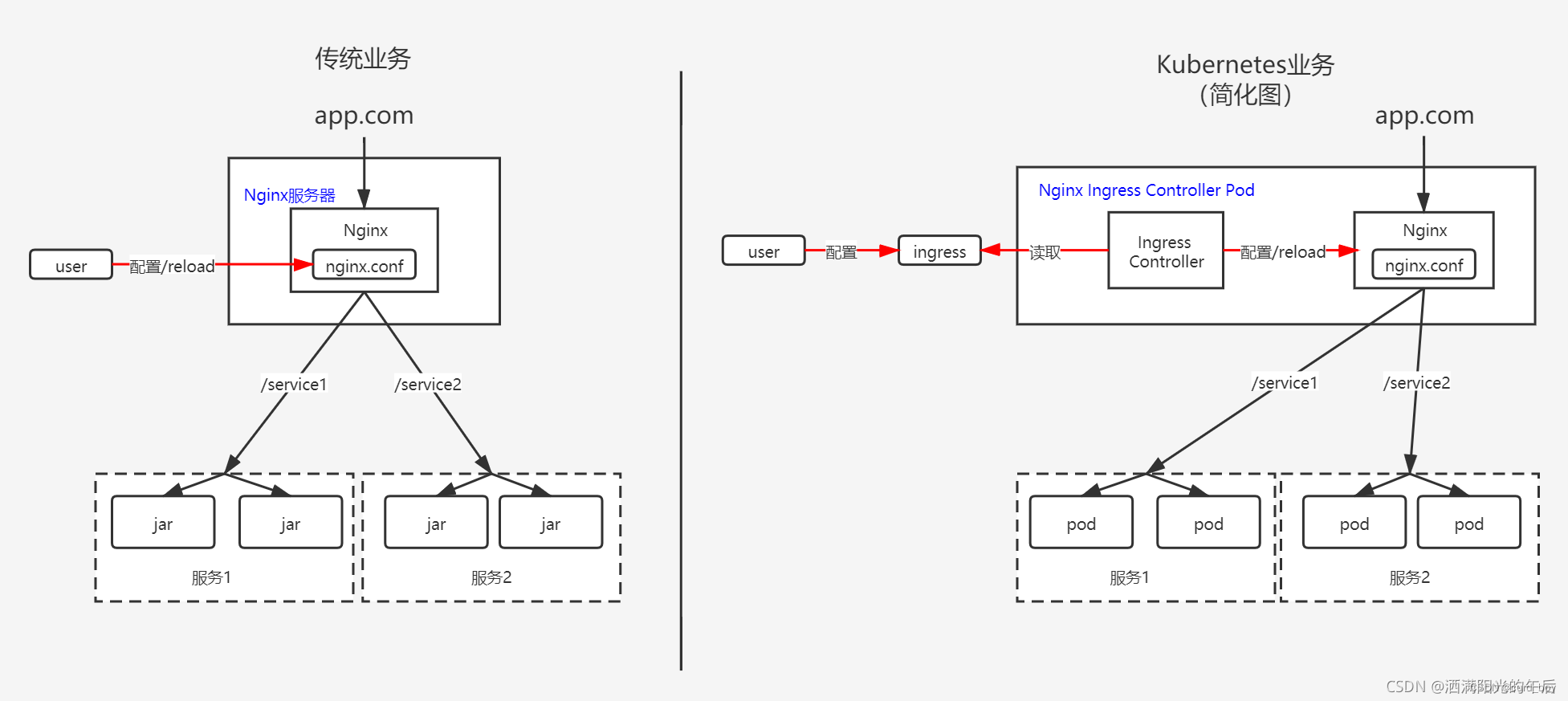
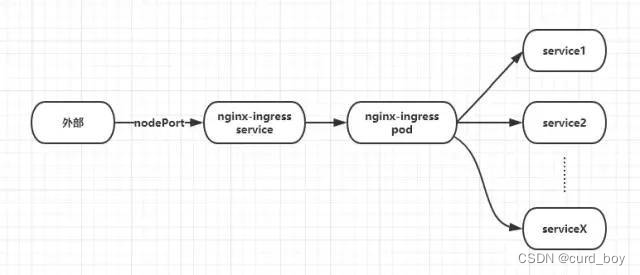
我们可以看到,因为 nginx-ingress 这个 pod 做了所有 service 的代理,在高并发情况下将承受巨大压力,我们可以增加多个 pod 实例。
->域名请求
->lb(监听node(部分或全部 看配置))
->node上lvs路由规则负责均衡转发 nginx-ingress-controller所有pod
->nginx ingress路由匹配cluster_ip(controller监听)
->cluster_ip通过ipvs将请求转发给pod(kube-proxy监听pod、service变化,维护node ipvs或iptable规则)
查看nginx配置,路由转发对应 namespace-service-name-port
<<K9s-Shell>> Pod: kube-system/nginx-ingress-controller-f-scbdd | Container: nginx-ingress-controller
bash-5.1$ cat nginx.conf
## start server test-app.com
server {
server_name test-app.com ;
listen 80 ;
listen [::]:80 ;
listen 443 ssl http2 ;
listen [::]:443 ssl http2 ;
set $proxy_upstream_name "-";
ssl_certificate_by_lua_block {
certificate.call()
}
location / {
set $namespace "service";
set $ingress_name "test";
set $service_name "test";
set $service_port "9443";
set $location_path "/";
set $global_rate_limit_exceeding n;
rewrite_by_lua_block {
lua_ingress.rewrite({
force_ssl_redirect = false,
ssl_redirect = true,
force_no_ssl_redirect = false,
preserve_trailing_slash = false,
use_port_in_redirects = false,
global_throttle = { namespace = "", limit = 0, window_size = 0, key = { }, ignored_cidrs = { } },
})
balancer.rewrite()
plugins.run()
}
# be careful with `access_by_lua_block` and `satisfy any` directives as satisfy any
# will always succeed when there's `access_by_lua_block` that does not have any lua code doing `ngx.exit(ngx.DECLINED)`
# other authentication method such as basic auth or external auth useless - all requests will be allowed.
#access_by_lua_block {
#}
header_filter_by_lua_block {
lua_ingress.header()
plugins.run()
}
body_filter_by_lua_block {
plugins.run()
}
log_by_lua_block {
balancer.log()
monitor.call()
plugins.run()
}
port_in_redirect off;
set $balancer_ewma_score -1;
set $proxy_upstream_name "service-test-app-9443";
set $proxy_host $proxy_upstream_name;
set $pass_access_scheme $scheme;
set $pass_server_port $server_port;
set $best_http_host $http_host;
set $pass_port $pass_server_port;
set $proxy_alternative_upstream_name "";
client_max_body_size 20m;
proxy_set_header Host $best_http_host;
# Pass the extracted client certificate to the backend
# Allow websocket connections
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_set_header X-Request-ID $req_id;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header X-Forwarded-Host $best_http_host;
proxy_set_header X-Forwarded-Port $pass_port;
proxy_set_header X-Forwarded-Proto $pass_access_scheme;
proxy_set_header X-Forwarded-Scheme $pass_access_scheme;
proxy_set_header X-Scheme $pass_access_scheme;
# Pass the original X-Forwarded-For
proxy_set_header X-Original-Forwarded-For $http_x_forwarded_for;
# mitigate HTTPoxy Vulnerability
# https://www.nginx.com/blog/mitigating-the-httpoxy-vulnerability-with-nginx/
proxy_set_header Proxy "";
# Custom headers to proxied server
proxy_connect_timeout 10s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering off;
proxy_buffer_size 4k;
proxy_buffers 4 4k;
proxy_max_temp_file_size 1024m;
proxy_request_buffering on;
proxy_http_version 1.1;
proxy_cookie_domain off;
proxy_cookie_path off;
# In case of errors try the next upstream server before returning an error
proxy_next_upstream error timeout;
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 3;
proxy_pass http://upstream_balancer;
proxy_redirect off;
}
}
## end server test-app.com
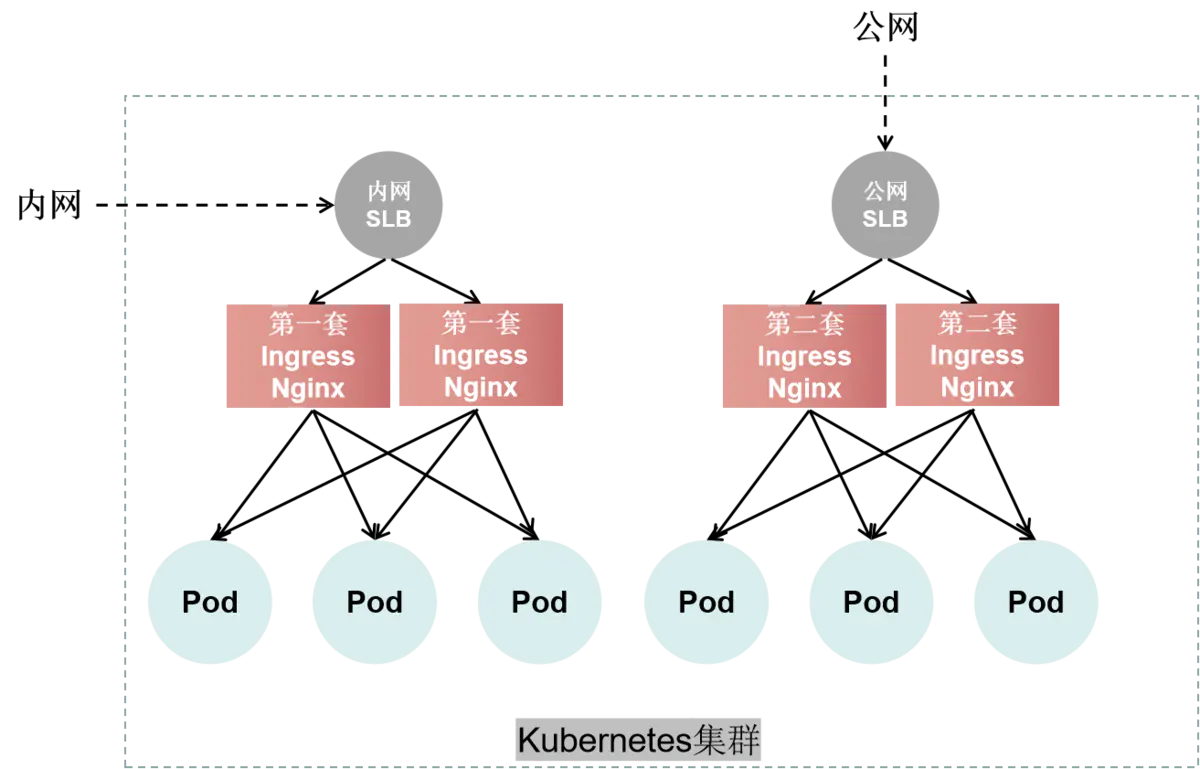
部署多套Ingress Controller
有时需要部署多套Ingress Controller,一套给VPC内网使用,另一套给公网使用。
ExternalTrafficPolicy的影响
ExternalTrafficPolicy字段通常出现在LoadBalancer类型的服务中,它有两个值:Local和Cluster。
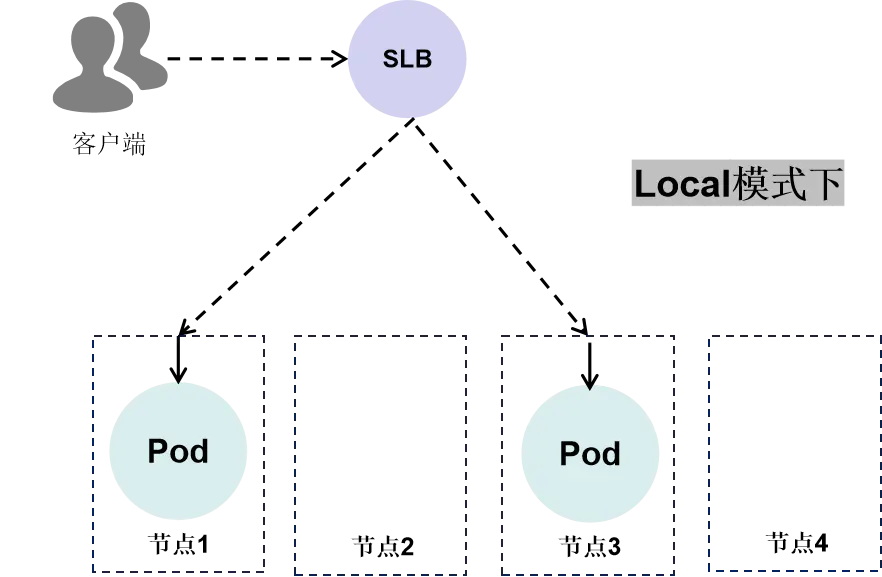
在Local模式下,SLB会将流量发往Pod所在的节点,即节点1和节点3,然后转发到本节点的Pod上。
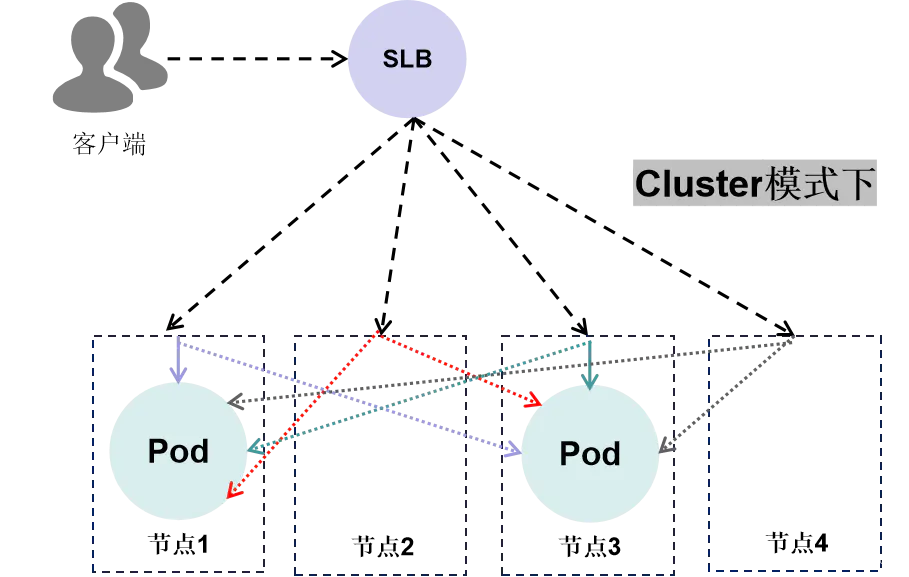
在Cluster模式下,SLB会将流量随机转发到任意一个Worker节点,然后Worker节点再随机转发到其中一个Pod上,既可能是转发到本届点的Pod上,有可能是转发到其他节点的Pod上。
跨节点转发是由SNAT实现的,而SNAT会修改掉报文的Source IP地址,Pod收到的报文的Source IP地址就是节点的IP地址,这样就把前一级的真实IP地址替换掉了。
前面讲过,SLB再四层的情况下,Client的真实IP地址是透传(不经过代理修改,直接转发)的。因此,Ingress-nginx无法获取客户端的真实IP地址。
如何获取客户端真实IP地址
根据上节所讲,需要将ExternelTrafficPolicy的值设置为Local,才能保证Ingress-nginx可以获取客户端的真实IP地址。这里分两种情况。
(1)SLB为四层转发时,Ingress-nginx可以正确获取到客户端真实IP地址,不需要做任何改动,Pod需要从Header里获取客户端真实IP地址。
(2)SLB为七层转发时,Tenginx会将客户端真实IP地址放到X-Forwarded-For里,同样,Ingress-nginx也会添加Tenginx的IP地址到X-Forwarded-For并传递给Pod。当Tenginx前面有多层代理时也是一样的。同时,我们需要再SLB和Ingress-nginx上开启X-Forwarded-For。SLB默认开启,Ingress-nginx开启X-Forwarded-For需要修改nginx-configuration,在data中添加:
https://www.jianshu.com/p/7079094c6518
1.2 Pod IP 地址的由来
https://www.cnblogs.com/sammyliu/p/8274478.html
coredns解析流程和corefile配置
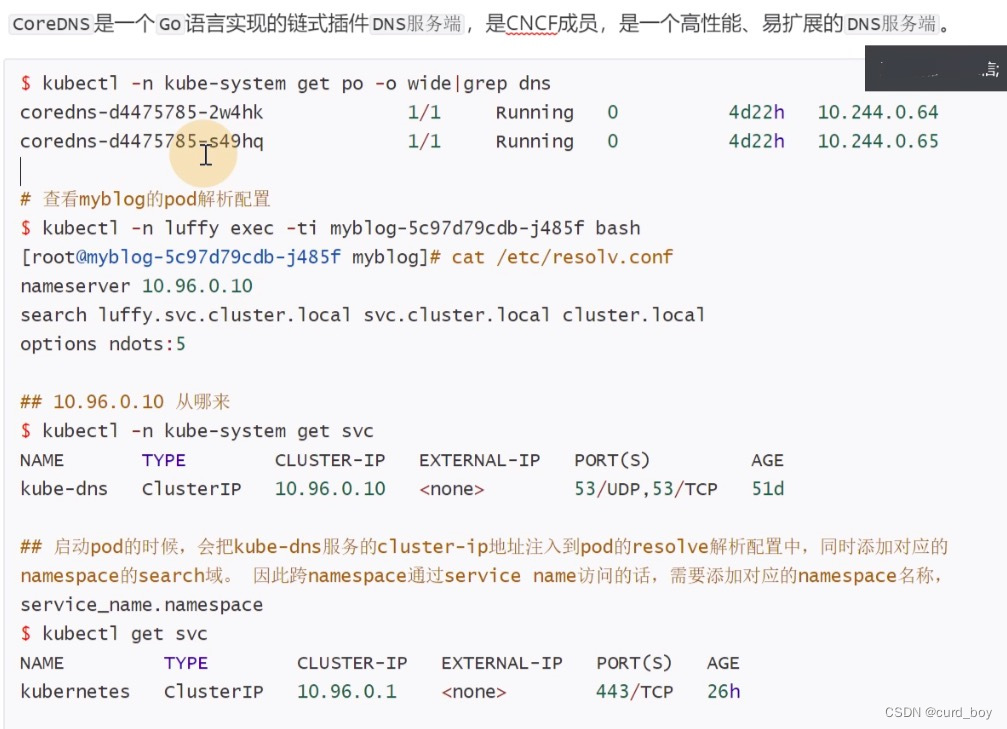
CoreDNS简介
CoreDNS 是一个 Go 语言编写的灵活可扩展的 DNS 服务器,在 Kubernetes 中,作为一个服务发现的配置中心,在 Kubernetes 中创建的 Service 和 Pod 都会在其中自动生成相应的 DNS 记录。Kubernetes 服务发现的特性,使 CoreDNS 很适合作为企业云原生环境的 DNS 服务器,保障企业容器化和非容器化业务服务的稳定运行。
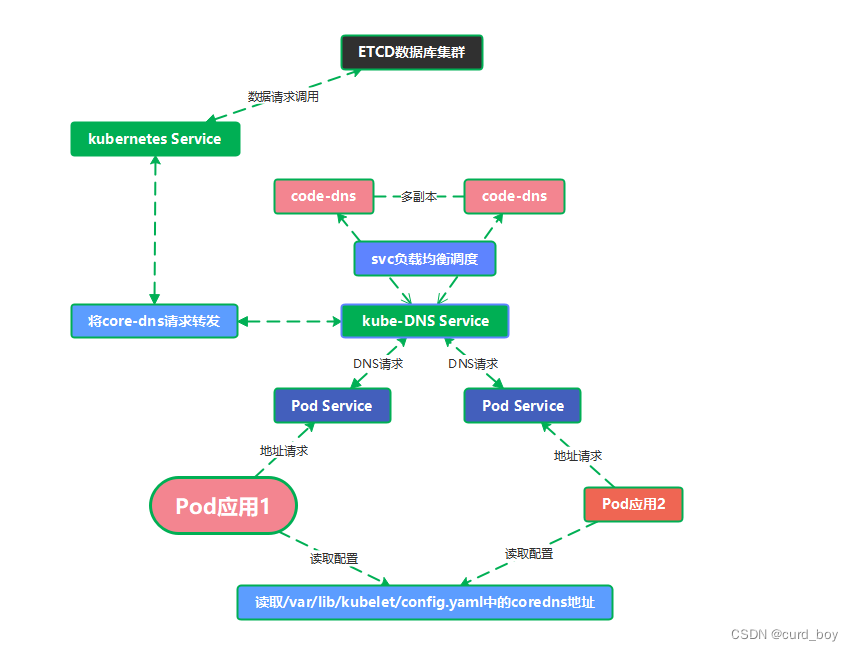
Core-DNS解析流程
当pod1应用想通过dns域名的方式访问pod2则首先根据容器中/etc/resolv.conf内容配置的nameserver地址,向dns服务器发出请求,由service将请求抛出转发给kube-dns service,由它进行调度后端的core-dns进行域名解析。
解析后请求给kubernetes service进行调度后端etcd数据库返回数据,pod1得到数据后由core-dns转发目的pod2地址解析,最终pod1请求得到pod2。
k8s服务发现 coredns
core dns配置
3.1 K8s DNS策略
Kubernetes 中 Pod 的 DNS 策略有四种类型。
1.Default:Pod 继承所在主机上的 DNS 配置;
2.ClusterFirst:K8s 的默认设置;先在 K8s 集群配置的 coreDNS 中查询,查不到的再去继承自主机的上游 nameserver 中查询;
3.ClusterFirstWithHostNet:对于网络配置为 hostNetwork 的 Pod 而言,其 DNS 配置规则与 ClusterFirst 一致;
4.None:忽略 K8s 环境的 DNS 配置,只认 Pod 的 dnsConfig 设置。
3.2 resolv.conf
在部署 pod 的时候,如果用的是 K8s 集群的 DNS,那么 kubelet 在起 pause 容器的时候,会将其 DNS 解析配置初始化成集群内的配置。
比如创建了一个叫 my-nginx 的 deployment,其 pod 中的 resolv.conf 文件如下:
# DNS 服务的 IP,即coreDNS 的 clusterIP
nameserver 169.254.25.10
# DNS search 域。解析域名的时候,将要访问的域名依次带入 search 域,进行 DNS 查询
# 比如访问your-nginx,其进行的 DNS 域名查询的顺序是:your-nginx.default.svc.cluster.local. -> your-nginx.svc.cluster.local. -> your-nginx.cluster.local.
search default.svc.cluster.local svc.cluster.local cluster.local
# 其他项,最常见的是 dnots。dnots 指的是如果查询的域名包含的点 “.” 小于 5,则先走search域,再用绝对域名;如果查询的域名包含点数大于或等于 5,则先用绝对域名,再走search域
# K8s 中默认的配置是 5。
options ndots:5
DNS
在 k8s 中做服务发现,最常用的方式是通过 DNS 解析。
在我们的 k8s 集群配置了 dns 服务(最常用的是 coredns)的前提下,我们就可以直接通过全限定域名(FQDN)来访问别的服务。
全限定域名的格式如下:
# 格式
<service-name>.<namespace>.svc.cluster.local # 域名 .svc.cluster.local 是可自定义的
# 举例:访问 default 名字空间下的 nginx 服务
nginx.default.svc.cluster.local
如果两个服务在同一个名字空间内,可以省略掉后面的 ..svc.cluster.local,直接以服务名称为 DNS 访问别的服务
P.S. DNS 服务发现的实现方式:修改每个容器的 /etc/resolv.conf,使容器访问 k8s 自己的 dns 服务器。而该 dns 服务器知道系统中的所有服务,所以它能给出正确的响应。
4.2 NodeLocal DNSCache
NodeLocal DNSCache通过在集群上运行一个dnsCache daemonset来提高clusterDNS性能和可靠性。相比于纯coredns方案,nodelocaldns + coredns方案能够大幅降低DNS查询timeout的频次,提升服务稳定性。
通过 DaemonSet 在集群的每个节点上部署一个 hostNetwork 的 Pod,该 Pod 是 node-cache,可以缓存本节点上 Pod 的 DNS 请求。如果存在 cache misses ,该 Pod 将会通过 TCP 请求上游 kube-dns 服务进行获取。原理图如下所示:
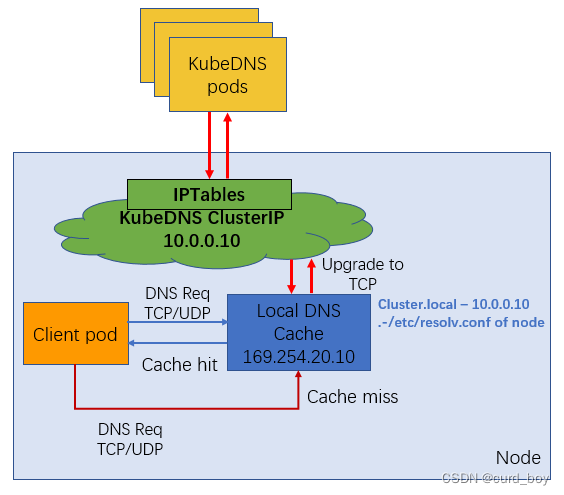
NodeLocal DNS Cache 没有高可用性(High Availability,HA),会存在单点 nodelocal dns cache 故障(Pod Evicted/ OOMKilled/ConfigMap error/DaemonSet Upgrade),但是该现象其实是任何的单点代理(例如 kube-proxy,cni pod)都会存在的常见故障问题。
Kubernetes中如何通过DNS name找到IP
kubectl describe service kube-dns -n kube-system

minikube上自动安装了coredns组件,并为这个组件创建了一个Service,叫kube-dns。通过Service(ip=10.96.0.10:53)可以找到coredns的Pod(ip=172.17.0.3:9153)。
可以看到这里的nameserver IP即为上述的kube-system下的Service为kube-dns的IP。

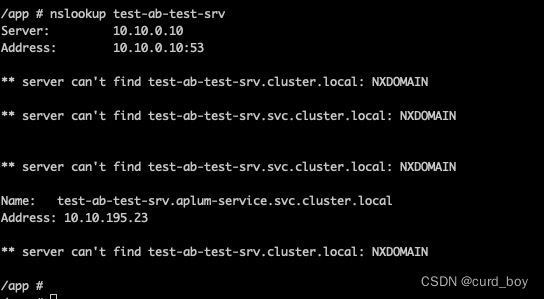
另外,我们在Pod的terminal界面中,还可以用nslookup命令来通过name在dns中查找ip
nslookup test-ab-test-srv

kube-proxy
kube-proxy 的主要作用是watch apiserver,当监听到pod 或service变化时,修改本地的iptables规则或ipvs规则。
clusterIP如何转换为pod ip呢
linux内核功能
每台机器上都运行一个kube-proxy服务,它监听api-server 和endpoint变化情况,维护service和pod之间的一对多的关系,通过iptable或者ipvs为服务提供负载均衡的能力。通常kube-proxy作为deemonset运行在各种节点中。
kube-proxy 常支持以下二种:
1)iptables:iptable模式是目前的默认模式,可以看成是userspace模式的升级版,它将请求的代理转发规则全部写入iptable中,砍掉了kube-proxy转发的部分。整个过程全部发生在内核空间,提高了转发性能。但是,iptable的规则是基于链表实现的,规则数量随着Service数量的增加线性增加,查找时间复杂度为O(n)。当Service数量到达一定量级时,CPU消耗和延迟增加显著
2)ipvs:ipvs模式是基于章文嵩博士开发的LVS实现的,ipvs和iptables都是基于内核的netfilter框架实现的,不同的是iptable主攻防火墙,ipvs主攻内核态4层负载均衡。可以说先天上,ipvs就比iptable更适合做Service的实现。
iptables
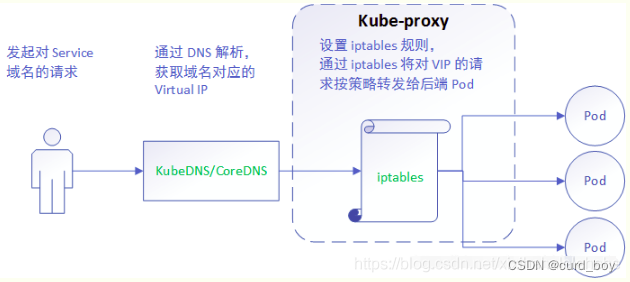
iptables 模式与 userspace 相同,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;但它并不在本地节点开启反向代理服务,而是把反向代理全部交给 iptables 来实现;即 iptables 直接将对 VIP 的请求转发给后端 Pod,通过 iptables 设置转发策略。其工作流程大体如下:
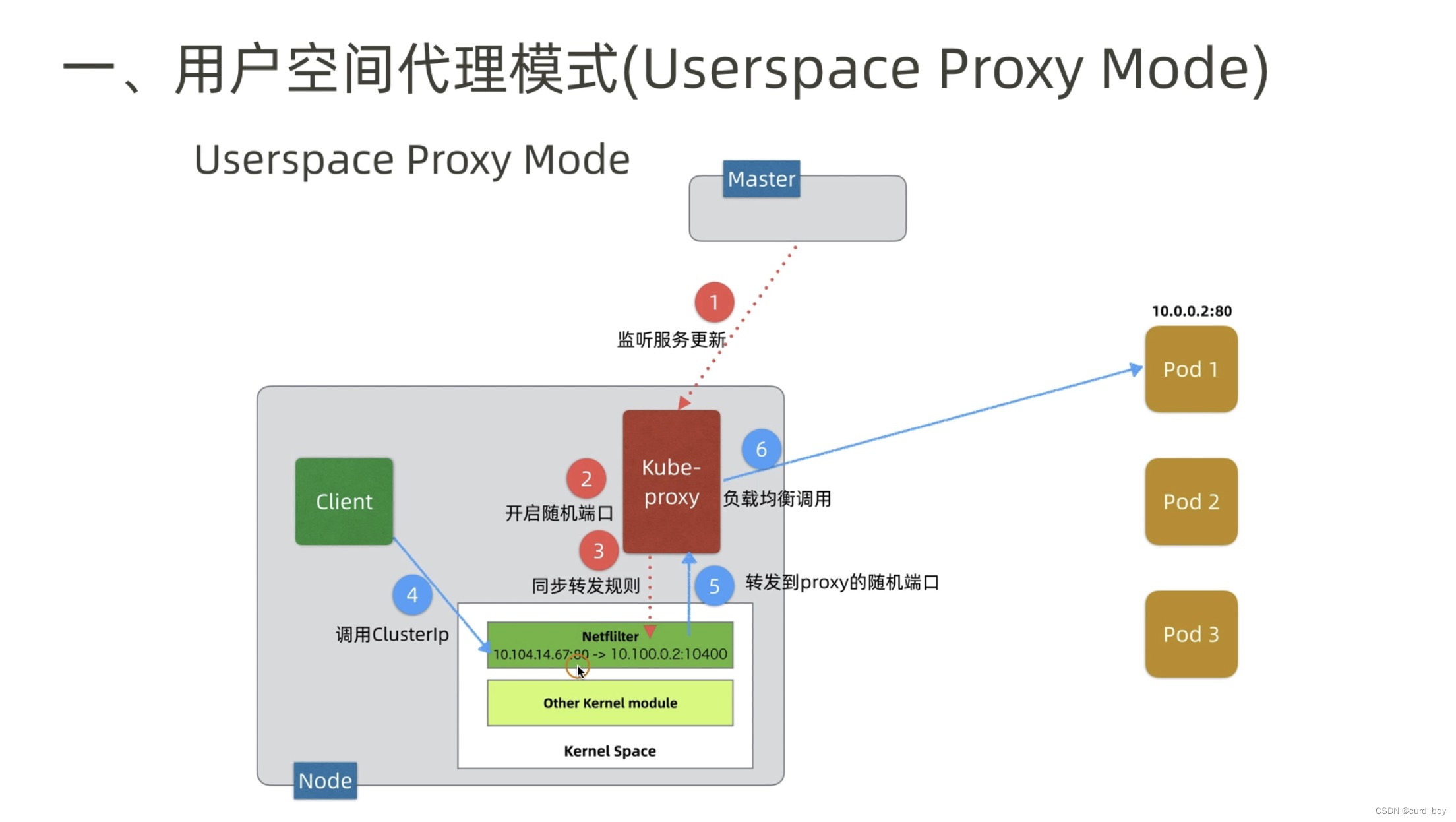
由此分析: 该模式相比 userspace 模式,克服了请求在用户态-内核态反复传递的问题,性能上有所提升,但使用 iptables NAT 来完成转发,存在不可忽视的性能损耗,而且在大规模场景下,iptables 规则的条目会十分巨大,性能上还要再打折扣。
ipvs模式下k8s的网络通信
这种模式,Kube-Proxy 会监视 Kubernetes Service 对象 和 Endpoints,调用 Netlink 接口以相应地创建 IPVS 规则并定期与 Kubernetes Service 对象 和 Endpoints 对象同步 IPVS 规则,以确保 IPVS 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.1:443 rr persistent 10800
-> 192.168.0.1:6443 Masq 1 1 0
TCP 10.0.0.10:53 rr
-> 172.17.0.2:53 Masq 1 0 0
UDP 10.0.0.10:53 rr
-> 172.17.0.2:53 Masq 1 0 0
网络插件

阿里云k8s
k8s信息

在pod内访问 ecs自建数据库
ECS的安全组 放行一下 内网的pod 和vpc的网段
10.0.0.0/8
192.168.0.0/16


在pod内测试结果, 内网可以访问:
/data # ping 192.168.0.63
PING 192.168.0.63 (192.168.0.63): 56 data bytes
64 bytes from 192.168.0.63: seq=0 ttl=63 time=0.379 ms
64 bytes from 192.168.0.63: seq=1 ttl=63 time=0.290 ms
64 bytes from 192.168.0.63: seq=2 ttl=63 time=0.294 ms
64 bytes from 192.168.0.63: seq=3 ttl=63 time=0.294 ms
64 bytes from 192.168.0.63: seq=4 ttl=63 time=0.321 ms
从外网访问k8s内部pod流程
进入nginx-ingress-controller pod
cat nginx.conf 可以查看到,通过nginx转发到不同命名空间服务的service
## start server test-www.ap-inc.com
server {
server_name test-www.ap-inc.com ;
listen 80 ;
listen 443 ssl http2 ;
set $proxy_upstream_name "-";
ssl_certificate_by_lua_block {
certificate.call()
}
location / {
set $namespace "ap-fe";
set $ingress_name "test-ap-homepage-pc";
set $service_name "test-ap-homepage-pc";
set $service_port "80";
set $location_path "/";
set $global_rate_limit_exceeding n;
rewrite_by_lua_block {
lua_ingress.rewrite({
force_ssl_redirect = false,
ssl_redirect = false,
force_no_ssl_redirect = false,
preserve_trailing_slash = false,
use_port_in_redirects = false,
global_throttle = { namespace = "", limit = 0, window_size = 0, key = { }, ignored_cidrs = { } },
})
balancer.rewrite()
plugins.run()
}
# be careful with `access_by_lua_block` and `satisfy any` directives as satisfy any
# will always succeed when there's `access_by_lua_block` that does not have any lua code doing `ngx.exit(ngx.DECLINED)`
# other authentication method such as basic auth or external auth useless - all requests will be allowed.
#access_by_lua_block {
#}
header_filter_by_lua_block {
lua_ingress.header()
plugins.run()
}
body_filter_by_lua_block {
plugins.run()
}
log_by_lua_block {
balancer.log()
monitor.call()
plugins.run()
}
port_in_redirect off;
set $balancer_ewma_score -1;
set $proxy_upstream_name "ap-fe-test-p-homepage-pc-80";
set $proxy_host $proxy_upstream_name;
set $pass_access_scheme $scheme;
set $pass_server_port $server_port;
set $best_http_host $http_host;
set $pass_port $pass_server_port;
set $proxy_alternative_upstream_name "";
client_max_body_size 20m;
proxy_set_header Host $best_http_host;
# Pass the extracted client certificate to the backend
# Allow websocket connections
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_set_header X-Request-ID $req_id;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header X-Forwarded-Host $best_http_host;
proxy_set_header X-Forwarded-Port $pass_port;
proxy_set_header X-Forwarded-Proto $pass_access_scheme;
proxy_set_header X-Forwarded-Scheme $pass_access_scheme;
proxy_set_header X-Scheme $pass_access_scheme;
# Pass the original X-Forwarded-For
proxy_set_header X-Original-Forwarded-For $http_x_forwarded_for;
# mitigate HTTPoxy Vulnerability
# https://www.nginx.com/blog/mitigating-the-httpoxy-vulnerability-with-nginx/
proxy_set_header Proxy "";
# Custom headers to proxied server
proxy_connect_timeout 10s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering off;
proxy_buffer_size 4k;
proxy_buffers 4 4k;
proxy_max_temp_file_size 1024m;
proxy_request_buffering on;
proxy_http_version 1.1;
proxy_cookie_domain off;
proxy_cookie_path off;
# In case of errors try the next upstream server before returning an error
proxy_next_upstream error timeout;
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 3;
proxy_pass http://upstream_balancer;
proxy_redirect off;
}
}
## end server test-www.ap-inc.com
curl service-name.namespace.svc.cluster.local:port

总结:nginx-> service-name -> kube-proxy -> podip
常用命令
进入集群环境 查看pod之间是否可以访问
BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件。 BusyBox
包含了一些简单的工具,例如ls、cat和echo等等,还包含了一些更大、更复杂的工具,例grep、find、mount以及telnet。
有些人将 BusyBox 称为 Linux 工具里的瑞士军刀。 简单的说BusyBox就好像是个大工具箱,它集成压缩了 Linux
的许多工具和命令,也包含了 Linux 系统的自带的shell。
kubectl run busybox --rm=true --image=busybox --restart=Never -it















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









