






介绍
Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个。简单易用,同时支持多种推荐算法(基础算法、协同过滤、矩阵分解等)。

设计surprise时考虑到以下目的:
- 让用户完美控制他们的实验。为此,特别强调 文档,试图通过指出算法的每个细节尽可能清晰和准确。
- 减轻数据集处理的痛苦。用户可以使用内置数据集(Movielens, Jester)和他们自己的自定义 数据集。
- 提供各种即用型预测算法, 例如基线算法, 邻域方法,基于矩阵因子分解( SVD, PMF, SVD ++,NMF)等等。
- 此外, 内置了各种相似性度量(余弦,MSD,皮尔逊…)。可以轻松实现新的算法思路。
- 提供评估, 分析 和 比较 算法性能的工具。
- 使用强大的CV迭代器(受scikit-learn优秀工具启发)以及 对一组参数的详尽搜索,可以非常轻松地运行交叉验证程序 。
其中基于近邻的方法(协同过滤)可以设定不同的度量准则

评估准则
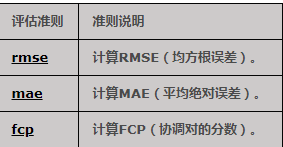
1.本地加载数据集
from surprise import KNNBasic,SVD
from surprise import Dataset,Reader
from surprise import evaluate, print_perf
from surprise.model_selection import cross_validate
import os
# http://surprise.readthedocs.io/en/stable/index.html
# http://files.grouplens.org/datasets/movielens/ml-100k-README.txt
# Load the movielens-100k dataset (download it if needed),
# and split it into 3 folds for cross-validation.
# data = Dataset.load_builtin('ml-100k')#加载
file_path=os.path.expanduser('ml-100k/u.data')#本地
reader=Reader(line_format='user item rating timestamp',sep='\t')
data=Dataset.load_from_file(file_path,reader=reader)
#k折交叉验证(k=3)
data.split(n_folds=3)
#基础过滤,测试效果
algo = KNNBasic()
perf = evaluate(algo, data, measures=['RMSE', 'MAE'])#评估方法均方根误差,均绝对误差
print_perf(perf)
打印输出:
Evaluating RMSE, MAE of algorithm KNNBasic.
------------
Fold 1
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9898
MAE: 0.7822
------------
Fold 2
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9905
MAE: 0.7821
------------
Fold 3
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9857
MAE: 0.7797
------------
------------
Mean RMSE: 0.9887
Mean MAE : 0.7813
------------
------------
Fold 1 Fold 2 Fold 3 Mean
RMSE 0.9898 0.9905 0.9857 0.9887
MAE 0.7822 0.7821 0.7797 0.7813
2. GridSearch寻找最优参数
from surprise import GridSearch
#定义好需要优选的参数网格
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
#算法使用SVD分解
grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP'])
#data = Dataset.load_builtin('ml-100k')
file_path=os.path.expanduser('ml-100k/u.data')#本地文件
#告诉文本阅读器,文本的格式是怎么样的
reader=Reader(line_format='user item rating timestamp',sep='\t')
#加载数据
data=Dataset.load_from_file(file_path,reader=reader)
data.split(n_folds=3)
#评估
grid_search.evaluate(data)
打印输出:
------------
Parameters combination 1 of 8
params: {'lr_all': 0.002, 'n_epochs': 5, 'reg_all': 0.4}
------------
Mean RMSE: 0.9972
Mean FCP : 0.6843
------------
------------
Parameters combination 2 of 8
params: {'lr_all': 0.005, 'n_epochs': 5, 'reg_all': 0.4}
------------
Mean RMSE: 0.9734
Mean FCP : 0.6946
------------
------------
Parameters combination 3 of 8
params: {'lr_all': 0.002, 'n_epochs': 10, 'reg_all': 0.4}
------------
Mean RMSE: 0.9777
Mean FCP : 0.6926
------------
------------
Parameters combination 4 of 8
params: {'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.4}
------------
Mean RMSE: 0.9635
Mean FCP : 0.6987
------------
------------
Parameters combination 5 of 8
params: {'lr_all': 0.002, 'n_epochs': 5, 'reg_all': 0.6}
------------
Mean RMSE: 1.0029
Mean FCP : 0.6875
------------
------------
Parameters combination 6 of 8
params: {'lr_all': 0.005, 'n_epochs': 5, 'reg_all': 0.6}
------------
Mean RMSE: 0.9820
Mean FCP : 0.6953
------------
------------
Parameters combination 7 of 8
params: {'lr_all': 0.002, 'n_epochs': 10, 'reg_all': 0.6}
------------
Mean RMSE: 0.9860
Mean FCP : 0.6943
------------
------------
Parameters combination 8 of 8
params: {'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.6}
------------
Mean RMSE: 0.9733
Mean FCP : 0.6991
------------
- 输出最优参数
# best RMSE score
print(grid_search.best_score['RMSE'])
# combination of parameters that gave the best RMSE score
print(grid_search.best_params['RMSE'])
# best FCP score
print(grid_search.best_score['FCP'])
# combination of parameters that gave the best FCP score
print(grid_search.best_params['FCP'])
打印输出:
0.963501988854
{'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.4}
0.699084153002
{'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.6}
- GridSearchCV 方法:
# 定义好需要优选的参数网格
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
# 使用网格搜索交叉验证
grid_search = GridSearchCV(SVD, param_grid, measures=['RMSE', 'FCP'], cv=3)
# 在数据集上找到最好的参数
data = Dataset.load_builtin('ml-100k')
# pref = cross_validate(grid_search, data, cv=3)
grid_search.fit(data)
# 输出调优的参数组
# 输出最好的RMSE结果
print(grid_search.best_score)
进行预测的常用方法和属性
grid.fit():运行网格搜索
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评
- dict的键成为DataFrame列:
import pandas as pd
results_df = pd.DataFrame.from_dict(grid_search.cv_results)
results_df

3.使用不同的推荐系统算法进行建模比较
from surprise import Dataset, print_perf
from surprise.model_selection import cross_validate
file_path=os.path.expanduser('ml-100k/u.data')#本地
reader=Reader(line_format='user item rating timestamp',sep='\t')
data=Dataset.load_from_file(file_path,reader=reader)
### 使用NormalPredictor
from surprise import NormalPredictor
algo = NormalPredictor()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('使用NormalPredictor\n')
print_perf(perf)
### 使用BaselineOnly
from surprise import BaselineOnly
algo = BaselineOnly()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('BaselineOnly\n')
print_perf(perf)
### 使用基础版协同过滤
from surprise import KNNBasic, evaluate
algo = KNNBasic()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('用基础版协同过滤\n')
print_perf(perf)
### 使用均值协同过滤
from surprise import KNNWithMeans, evaluate
algo = KNNWithMeans()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('使用均值协同过滤\n')
print_perf(perf)
print()
### 使用协同过滤baseline
from surprise import KNNBaseline, evaluate
algo = KNNBaseline()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('使用协同过滤baseline')
print_perf(perf)
print()
### 使用SVD
from surprise import SVD, evaluate
algo = SVD()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('使用SVD\n')
print_perf(perf)
print()
### 使用SVD++
from surprise import SVDpp, evaluate
algo = SVDpp()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('使用SVD++\n')
print_perf(perf)
print()
### 使用NMF
from surprise import NMF
algo = NMF()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print('用基础版协同过滤\n')
print_perf(perf)
打印输出:
使用NormalPredictor
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE1.5211 1.5267 1.5147 1.5208
TEST_MAE1.2210 1.2279 1.2186 1.2225
FIT_TIME0.0800 0.0960 0.0980 0.0913
TEST_TIME0.2160 0.1820 0.1920 0.1967
Estimating biases using als...
Estimating biases using als...
Estimating biases using als...
BaselineOnly
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9501 0.9420 0.9507 0.9476
TEST_MAE0.7505 0.7491 0.7542 0.7513
FIT_TIME0.1340 0.1420 0.1610 0.1457
TEST_TIME0.1540 0.1580 0.1650 0.1590
Computing the msd similarity matrix...
Done computing similarity matrix.
Computing the msd similarity matrix...
Done computing similarity matrix.
Computing the msd similarity matrix...
Done computing similarity matrix.
用基础版协同过滤
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9848 0.9930 0.9822 0.9867
TEST_MAE0.7785 0.7853 0.7761 0.7800
FIT_TIME0.2940 0.3080 0.3320 0.3113
TEST_TIME3.9830 4.2000 4.1950 4.1260
Computing the msd similarity matrix...
Done computing similarity matrix.
Computing the msd similarity matrix...
Done computing similarity matrix.
Computing the msd similarity matrix...
Done computing similarity matrix.
使用均值协同过滤
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9533 0.9585 0.9591 0.9569
TEST_MAE0.7502 0.7538 0.7571 0.7537
FIT_TIME0.3170 0.3400 0.3310 0.3293
TEST_TIME4.4160 4.3900 4.3870 4.3977
Estimating biases using als...
Computing the msd similarity matrix...
Done computing similarity matrix.
Estimating biases using als...
Computing the msd similarity matrix...
Done computing similarity matrix.
Estimating biases using als...
Computing the msd similarity matrix...
Done computing similarity matrix.
使用协同过滤baseline
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9344 0.9319 0.9397 0.9353
TEST_MAE0.7372 0.7332 0.7413 0.7372
FIT_TIME0.4720 0.4480 0.4880 0.4693
TEST_TIME5.1810 5.2340 5.1500 5.1883
使用SVD
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9430 0.9488 0.9481 0.9467
TEST_MAE0.7441 0.7492 0.7475 0.7470
FIT_TIME3.2910 3.2740 3.2060 3.2570
TEST_TIME0.2330 0.2120 0.2180 0.2210
使用SVD++
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9310 0.9256 0.9244 0.9270
TEST_MAE0.7305 0.7275 0.7274 0.7285
FIT_TIME96.0670 93.5950 94.2860 94.6493
TEST_TIME3.9380 3.9330 3.9100 3.9270
用基础版协同过滤
Fold 1 Fold 2 Fold 3 Mean
TEST_RMSE0.9704 0.9731 0.9804 0.9746
TEST_MAE0.7629 0.7633 0.7701 0.7654
FIT_TIME3.4200 3.4150 3.4240 3.4197
TEST_TIME0.1840 0.1850 0.1830 0.1840
4.训练KNNBaseline模型
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import os
import io
from surprise import KNNBaseline
from surprise import Dataset
def read_item_names():
file_name = ('./ml-100k/u.item')
rid_to_name = {}
name_to_rid = {}
with io.open(file_name, 'r', encoding='ISO-8859-1') as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
data = Dataset.load_builtin('ml-100k')
#转换为标准矩阵格式
trainset = data.build_full_trainset()
#使用pearson_baseline方式计算相似度 False以item为基准计算相似度 本例为电影之间的相似度
sim_options = {'name': 'pearson_baseline', 'user_based': False}#参数
algo = KNNBaseline(sim_options=sim_options)
algo.train(trainset)
5.获取id到name的互相映射
- 数据样本ID
rid_to_name, name_to_rid = read_item_names()
print(rid_to_name)
toy_story_raw_id = name_to_rid['Now and Then (1995)']
toy_story_raw_id #数据样本ID
{'1': 'Toy Story (1995)', '2': 'GoldenEye (1995)', '3': 'Four Rooms (1995)', '4': 'Get Shorty (1995)', '5': 'Copycat (1995)', '6': 'Shanghai Triad (Yao a yao yao dao waipo qiao) (1995)', '7': 'Twelve Monkeys (1995)', '8': 'Babe (1995)', '9': 'Dead Man Walking (1995)', '10': 'Richard III (1995)', '11': 'Seven (Se7en) (1995)', '12': 'Usual Suspects, The (1995)', '13': 'Mighty Aphrodite (1995)', '14': 'Postino, Il (1994)', '15': "Mr. Holland's Opus (1995)", '16': 'French Twist (Gazon maudit) (1995)', '17': 'From Dusk Till Dawn (1996)', '18': 'White Balloon, The (1995)', '19': "Antonia's Line (1995)", '20': 'Angels and Insects (1995)', '21': 'Muppet Treasure Island (1996)', '22': 'Braveheart (1995)', '23': 'Taxi Driver (1976)', '24': 'Rumble in the Bronx (1995)', '25': 'Birdcage, The (1996)', '26': 'Brothers McMullen, The (1995)', '27': 'Bad Boys (1995)', '28': 'Apollo 13 (1995)', '29': 'Batman Forever (1995)', '30': 'Belle de jour (1967)', '31': 'Crimson Tide (1995)', '32': 'Crumb (1994)', '33': 'Desperado (1995)', '34': 'Doom Generation, The (1995)', '35': 'Free Willy 2: The Adventure Home (1995)', '36': 'Mad Love (1995)', '37': 'Nadja (1994)', '38': 'Net, The (1995)', '39': 'Strange Days (1995)', '40': 'To Wong Foo, Thanks for Everything! Julie Newmar (1995)', '41': 'Billy Madison (1995)', '42': 'Clerks (1994)', '43': 'Disclosure (1994)', '44': 'Dolores Claiborne (1994)', '45': 'Eat Drink Man Woman (1994)', '46': 'Exotica (1994)', '47': 'Ed Woo........
'1053'
- 样本ID转矩阵ID
toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id)
toy_story_inner_id #矩阵ID
961
- 寻找矩阵中邻近的ID
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=10)
toy_story_neighbors
[291, 82, 366, 528, 179, 101, 556, 310, 431, 543]
- 矩阵ID到样本name
raw_iids = (algo.trainset.to_raw_iid(inner_id)
for inner_id in toy_story_neighbors)
toy_story_neighbors = (rid_to_name[rid]
for rid in raw_iids)
print()
print('The 10 nearest neighbors of Toy Story are:')
for movie in toy_story_neighbors:
print(movie)
The 10 nearest neighbors of Toy Story are:
While You Were Sleeping (1995)
Batman (1989)
Dave (1993)
Mrs. Doubtfire (1993)
Groundhog Day (1993)
Raiders of the Lost Ark (1981)
Maverick (1994)
French Kiss (1995)
Stand by Me (1986)
Net, The (1995)















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









