







Kafka实战笔记
关于这份笔记,为了不影响大家的阅读体验,我只能在文章中展示部分的章节内容和核心截图

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置

- Kafka的集群
- 第一个Kafka程序

afka的生产者

- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

- Kafka实战之削峰填谷

drop database if exists db_name1;
drop database if exists db_name2;
说明:数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
2. 常用数据类型
==========
2.1 数值类型
整型和浮点型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| BIT[(M)] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用boolean对应BIT,此时默认为1位,只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M,D) | 4字节 | 单精度,M指定长度,D指定小数位数,会发生精度丢失 | Float |
| DOUBLE(M,D) | 8字节 | Double | |
| DECIMAL(M,D) | M/D最大值+2 | 双精度,M指定长度,D表示小数点位数,精确数值 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
2.2 字符串类型
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| VARCHAR(SIZE) | 0-65535字节 | 可变长度字符串 | String |
| TEXT | 0-65535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16777215字节 | 中等长度文本数据 | String |
| BLOB | 0-65535字节 | 二进制形式的长文本数据 | byte[] |
2.3 日期类型
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| DATATIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换 | java.util.Data java.sql.Timestamp |
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换 | java.util.Data java.sql.Timestamp |
3. 表的操作
========
需要操作数据库中的表时,需要先使用数据库:
use db_name;
3.1 查看表的结构
desc 表名;
示例:
3.2 创建表
语法:
create table table_name(
field1 datatype,
field2 datatype,
field3 datatype
);
可以使用comment增加字段说明
示例:
create table student (
id int,
name varchar(10) comment ‘姓名’,
age int comment ‘年龄’,
sex varchar(1)
);
3.3 删除表
语法格式:
DROP [TEMPORARY] TABLE [IF EXISTS] tab_name;
示例:
– 删除tab_name1表
drop table tab_name1;
– 如果tab_name2表存在,则删除
drop table if exists tab_name2;
4. MySQL表的增删查改(CRUD)
=====================
注释:在SQL中可以使用“–空格+描述”来进行注释说明
CRUD即:增加(create),查询(retrieve),更新(updata),删除(delete)
4.1 新增(create)
语法:
INSERT
[INTO] table_name [(column [, column]…
) ]
VALUES
(value_list) [, (value_list)]…value_list: value,
[, value]…
案例表:
create table student (
id int,
name varchar(10) comment ‘姓名’,
age int comment ‘年龄’,
sex varchar(1) comment ‘性别’
);
单行数据 + 全列插入 :
– value_list数量必须和表的列的数量和顺序一致
insert into student values (1,‘小张’,20,‘男’);
insert into student values (2,‘小红’,21,‘女’);
多行数据 + 指定列插入:
insert into
student (id, name, age)
values
(3, ‘小花’, 22),
(4, ‘小赵’, 25);
4.2 查询(retrieve)
语法:
SELECT
[DISTINCT] {* | {column [, column] …}
[FROM table_name]
[WHERE …]
[ORDER BY column [ASC | DESC], …]
LIMIT …
案例表:
– 创建成绩表
create table student_score (
id int,
name varchar(10),
chinese decimal(3, 1),
math decimal(3, 1),
english decimal(3, 1)
);
– 往成绩表中插入数据
insert into
student_score (id, name, chinese, math, english)
values
(1, ‘小张’, 60.5, 70, 85),
(2, ‘小花’, 85.5, 95, 96),
(3, ‘小赵’, 76, 88, 92),
(4, ‘小王’, 85, 64, 73);
全列查询:
– *代表全部列
select * from student_score;
结果:

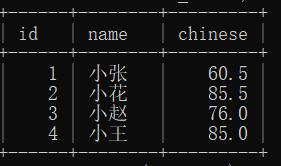
指定列查询:
select
id,
name,
chinese
from
student_score;
结果:
查询字段为表达式:
表达式含有一个字段
– 表达式包含一个字段
select
id,
name,
chinese + 10,
math -10,
english -5
from
student_score;
结果:

表达式不含有字段
– 表达式不包含字段
select id,name,10 from student_score;
结果:

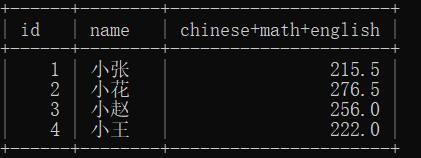
表达式包含多个字段
– 表达式含多个字段
select
id,
name,
chinese + math + english
from
student_score;
结果:
4.3 别名
为查询结果中的指定列起别名,表示返回的结果集中,以别名作为该列的名称,语法:
SELECT column [AS] alias_name […] FROM table_name;
关键字为:as,但是as可以省略
示例:
– 别名作为列名返回
select
id,
name,
chinese + math + english sum
from
student_score;
结果:

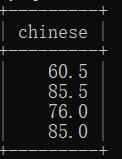
4.4 去重(distinct)
使用DISTINCT关键字对某列数据进行去重
– 语文得85分的重复了
select chinese from student_score;

– 去重结果
select distinct chinese from student_score;
4.5 排序(ORDER BY)
语法:
– ASC 为升序(从小到大)
– DESC 为降序(从大到小)
– 默认为 ASC
SELECT … FROM table_name [WHERE …]
ORDER BY column [ASC|DESC], […];
1. 没有order by子句的查询返回的顺序是未定义的
2. null数据排序,视为比任何值都小,升序在最上面,降序在最下面
示例:按语文成绩进行升序排序:
select
from
student_score
order by
chinese;
结果:

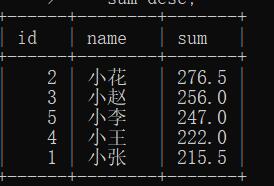
3. 使用表达式及别名进行排降序
select
id,
name,
chinese + math + english sum
from
student_score
order by
sum desc;
结果:
4. 可以对多个字段进行排序,排序优先级随书写顺序
select
from
student_score
order by
chinese,
math,
english desc;
结果:

4.6 条件查询(where)
比较运算符:
| 运算符 | 说明 |
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL不安全,NULL=NULL的结果为NULL |
| <=> | 等于,NULL安全,NULL<=>NULL的结果为TRUE |
| !=,<> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[ a0,a1 ] |
| IN(option1......) | 如果是option中的任意一个返回true |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配,%表示任意多个任意字符;_表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件都必须是true,结果才是true |
| OR | 任意一个条件为true,结果就是true |
| NOT | 条件为true,结果为false |
注意:
1. where条件可以使用表达式,但是不能使用别名
2. AND的优先级高于OR
示例:
· 基本查询:
– 查询语文成绩小于70分的同学
select id,name,chinese from student_score where chinese<70;
–查询语文成绩比英语成绩低的同学
select
id,
name,
chinese,
english
from
student_score
where
chinese < english;
– 查询总分低于250分的同学
select
id,
name,
chinese + math + english
from
student_score
where
总结
面试难免让人焦虑不安。经历过的人都懂的。但是如果你提前预测面试官要问你的问题并想出得体的回答方式,就会容易很多。
此外,都说“面试造火箭,工作拧螺丝”,那对于准备面试的朋友,你只需懂一个字:刷!
给我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”

且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。

同学
select
id,
name,
chinese + math + english
from
student_score
where
总结
面试难免让人焦虑不安。经历过的人都懂的。但是如果你提前预测面试官要问你的问题并想出得体的回答方式,就会容易很多。
此外,都说“面试造火箭,工作拧螺丝”,那对于准备面试的朋友,你只需懂一个字:刷!
给我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”
[外链图片转存中…(img-MOcmX0oV-1715591545374)]
且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
[外链图片转存中…(img-hy05Gbgl-1715591545375)]















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









