





numpy的学习
原文连接

numpy包是python生态系统中数据分析、机器学习和科学计算的主力。它极大地简化了向量和矩阵的操作和运算。python的一些主要包依赖NumPy作为其基础架构的基本部分(例如scikit-learn、SciPy、panda和tensorflow)。除了能够对数字数据进行切片和分割之外,掌握numpy还将使您在处理和调试这些库中的高级用例时获得优势。
在这篇文章中,我们将介绍使用NumPy的一些主要方法,以及在将它们用于机器学习模型之前,它如何表示不同类型的数据(表、图像、文本等等)。
import numpy as np创建数组
我们可以通过向它传递一个python列表并使用’ np.array() '来创建一个NumPy数组(也称为mighty ndarray)。在本例中,python创建了我们可以在右边看到的数组:

通常情况下,我们希望NumPy为我们初始化数组的值。NumPy为这些情况提供了像ones()、zeros()和random.random()这样的方法。我们只是传递给他们我们希望它产生的元素的数量:

一旦我们创建了数组,就可以开始以有趣的方式操作它们。
数组运算
让我们创建两个NumPy数组来展示它们的用处。我们叫他们data和ones:

将它们按位置做加法运算(即按每行的值加),data+ones:

当我开始学习这样的工具时,我发现这样的抽象使我不必编写循环去进行计算,这让我耳目一新。这是一个很好的抽象概念,可以让你在更高的层次上思考问题。
不仅仅是加法运算,我们还可以这样做:

通常情况下,我们希望在数组和单个数字之间执行操作(我们也可以将此称为向量和标量之间的操作)。例如,我们的数组表示距离(以英里为单位),我们想把它转换成公里。我们简单地举个例子: data * 1.6

看到NumPy是如何理解这个操作的了吗?这个概念叫做广播(broadcasting),它非常有用。
indexing(索引)
我们可以像对python列表一样对Numpy数组进行索引和切片操作:

Aggregation(聚合)
我们还能从NumPy的聚合函数得到一些额外的益处:
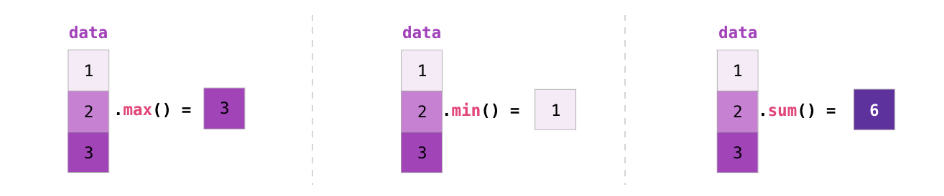
除了min,max和sum函数,我们还可以从mean函数得到均值,prod函数得到所有元素的乘积,std函数得到标准差,等等其他的函数。
In more dimensions(更多的维度)
我们看过的所有例子都是关于一维向量的。NumPy的一个关键之处在于它能够将我们目前看到的所有东西应用到任意数量的维度上。
Creating Matrices(创建矩阵)
我们可以通过以下形状的python列表来让NumPy创建一个矩阵来表示它们:

我们也可以使用上面提到的方法(ones(),zeros(),and random.random()),只要我们给他们一个元组来描述我们创建的矩阵的维数:

Matrix Arithmetic(矩阵运算)
如果两个矩阵大小相同,我们可以使用算术运算符(±*/)对矩阵进行加法和乘法运算。NumPy将这些进行position-wise 运算:

(例如,矩阵只有一列或一行),我们才能对矩阵执行这些算术操作,当矩阵的维度不同的时候,NumPy可以使用它的广播规则来执行该操作:

Dot Product(点积)
算术的一个关键区别是使用点积的矩阵乘法(matrix multiplication)。NumPy给每个矩阵一个dot()方法,我们可以用来执行与其他矩阵的点乘操作:

我已经在这个图的底部添加了矩阵维数来强调这两个矩阵必须有相同的维数。你可以想象这个操作是这样的:

Matrix Indexing(矩阵索引)
当我们处理矩阵时,索引和切片操作变得更加有用:

Matrix Aggregation(矩阵聚合)
我们可以像集合向量一样集合矩阵:

我们不仅可以在一个矩阵中聚合所有的值,还可以使用axis参数跨行或跨列聚合:

Transposing and Reshaping(矩阵转置和shape 重塑)
处理矩阵时一个常见的需求是需要旋转它们。经常会出现这种情况:当我们需要取两个矩阵的点积并且需要对齐它们共享的维度时。NumPy数组有一个方便的属性称为T来得到一个矩阵的转置:

在更高级的用例中,您可能会发现需要切换某个矩阵的维数。在机器学习应用程序中,这通常是这样的情况:特定的模型需要与数据集不同的输入的特定形状。NumPy的reshape()方法在这些情况下很有用。你只需要把矩阵的新维数传递给它。你可以通过-1作为一个尺寸 并且 NumPy可以基于你的矩阵推断正确的尺寸:

Yet More Dimensions(更多的尺寸)
NumPy可以做我们在任何维度中提到的所有事情。它的中心数据结构被称为ndarray (N-Dimensional Array)是有原因的。

在很多情况下,处理一个新维度仅仅在NumPy函数的参数中添加一个逗号就可以了:

注意:请记住,当您打印一个三维NumPy数组时,文本输出显示的数组与这里显示的不同。NumPy打印n维数组的顺序是,最后一个轴是最快的,而第一个轴是最慢的。这意味着,np.ones((4,3,2))将被打印为:(4个3行2列的二维数组)

Practical Usage(实际运用)
下面是一些NumPy将帮助您完成的事情的示例。
formulas(公式)
实现基于矩阵和向量的数学公式是考虑使用NumPy的一个关键原因。这就是为什么NumPy是科学python社区的宠儿。例如,考虑处理回归问题的监督机器学习模型的核心均方误差公式:
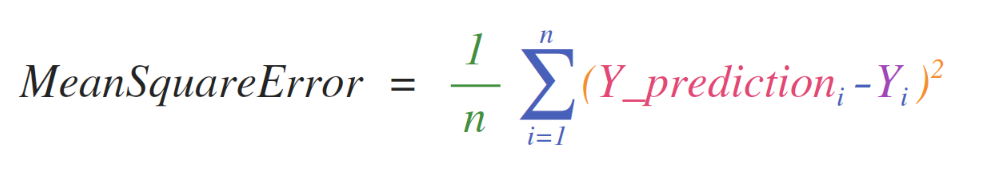
实现这个对于NumPy来说非常简单:

它的美妙之处在于numpy并不关心预测和标签是否包含一个或1000个值(只要它们的大小相同)。我们可以通过一个例子,依次通过以下四个操作步骤:

预测和标签(实际值)向量都包含三个值。也就是说n的值是3。在我们进行减法之后,我们得到的值是这样的:

然后我们可以平方向量中的值:

现在我们把这些值相加:

结果是预测模型的质量分数。
Data Representation(数据表示)
考虑所有你需要处理和构建模型的数据类型(电子表格、图像、音频……等等)。它们中的许多都非常适合在n维数组中表示:
Tables and Spreadsheets(表和电子表格)
电子表格或值表是二维矩阵。电子表格中的每个工作表都可以是自己的变量。python中最流行的抽象是panda dataframe,它实际上使用NumPy并在其上构建:

Audio and Timeseries(音频和Timeseries)
音频文件是一维的样本数组。每个样本是一个数字,代表一小块音频信号。CD质量的音频每秒可能有44,100个样本,每个样本是-32767到32768之间的整数。这意味着如果您有一个10秒的CD质量的WAVE文件,您可以将它装入一个长度为10 * 44,100 = 441,000的NumPy数组中。想提取音频的第一秒吗?只需将文件加载到我们将调用的NumPy数组中audio方法,然后使用 audio[:44100]
下面是一段音频文件:

时间序列数据也是如此(例如,股票价格随时间的变化)。
Images(图片)
图像是大小(高x宽)像素的矩阵。
如果图像是黑白的(也称为灰度),每个像素可以用一个数字表示(通常在0(黑色)和255(白色)之间)。想要裁切图像左上角的10x10像素部分吗?通过调用NumPy的image[:10,:10]
下面是一个图像文件的切片:

如果图像是彩色的,那么每个像素由三个数字表示—分别代表红色、绿色和蓝色。在这种情况下,我们需要第三维(因为每个单元格只能包含一个数字)。因此,彩色图像是由一个维度的ndarray表示的:(高x宽x 3)。

Language(语言)
如果我们处理的是文本,情况就有点不同了。文本的数字表示需要构建词汇表(模型需要知道所有单词的清单,也就是需要一个词汇表)和嵌入步骤。让我们看看用数字来表示这句话的步骤吧:
“Have the bards who preceded me left any theme unsung?”
一个模型需要查看大量的文本,然后才能用数字表示文字。我们可以继续让它处理一个小数据集,并使用它来建立一个词汇表(71,290个单词):

然后,句子可以被分解成一组标记(tokens)(基于通用规则的单词或单词的一部分):可以理解为分词

然后用词汇表中的id替换每个单词:

这些id仍然不能为模型提供太多的信息价值。因此,在将单词序列提供给模型之前,需要将标记/单词替换为它们的嵌入(本例使用word2vec词嵌入为50维):

您可以看到这个NumPy数组的维数是[embedding_dimension x sequence_length]。在实践中,这些可能是另一种方式,但我这样做是为了保持视觉一致性。出于性能方面的原因,深度学习模型倾向于保留批处理大小的第一个维度(因为如果并行地训练多个示例,则可以更快地训练模型)。这是一个很明显的例子,在这个例子中,reshape()变得非常有用。例如,像BERT这样的模型,它的输入应该是这样的:[batch_size、sequence_length、embedding_size]。

现在这是一个数字体积(numeric volume),模型可以处理它并使用它做一些有用的事情。我将其他行留空,但它们将被其他示例填充,以便模型进行训练(或预测)。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









