






关于hash table的一些基础知识
首先,一般哈希表都是用来快速判断一个元素是否出现集合里。 他的核心思想就是空间换时间。哈希表一般有三种结构:
-
数组:数组也可以作为哈希表使用,但是缺点是数组的大小在定义时就不可改变,所以适合数据有限的情况下使用,比如242.有效的字母异位词就可以使用。但数组作为哈希表使用时有一个好处,就是不用经过哈希函数运算得到映射,所以在增加元素时的速度要比另外两种快。
-
set:set在c++中有三种容器,但只有
unordered_set的底层实现使用的是hash table。下面给出三种set容器的对比:

(图片来自卡哥的代码随想录)
可以看到set和multiset中的元素都是有序的,而unordered_set顾名思义其中的元素是无序的,并且unordered_set的增删查的效率都是O(1)。下面看一下unordered_set在c++中常用的函数:- 初始化:
//一般常用的有有三种初始化的方式 unordered_set<int> set1; //空的set unordered_set<int> set2(set1) //拷贝构造 unordered_set<int> set3(set1.begin(),set1.end()) //使用迭代器构造,这里的迭代器也可以是vector unordered_set<int> set4(nums,nums+5) //使用数组构造 unordered_set<int> set5 {1,2,3,4,5} //直接构造- 常用函数:
unordered_set<int> set {1,2,3,4,5}; //查找:find和count set.find(1) //find函数返回的是一个迭代器变量即元素的位置 set.count(1) //count函数返回的是0/1,0代表无,1代表有 //插入:insert,一般常用的有三种插入方式 set.insert(6) //直接插入元素,返回pair<unordered_set<int>::iterator, bool>,插入位置和是否成功 set.insert(set.end(),7) //指定位置插入,返回指向插入元素的迭代器 set.insert(set1.begin(),set1.end()) //范围插入 //删除:erase set.erase(1); //直接删除元素 set.erase(set.find(1)); //输入的是迭代器 set.erase(set.find(1),set.find(1)+1); //输入的是迭代器的范围参考此文:C++常用语法——unordered_set
注意函数在输入参数数量变化下返回值的不同。 -
map:map是一种key-value的数据类型,与set一样有三种类型,分别是
map、multimap和unordered_map,和set相似map、multimap底层实现是红黑树,unordered_map底层是hash table,同样给出对比:
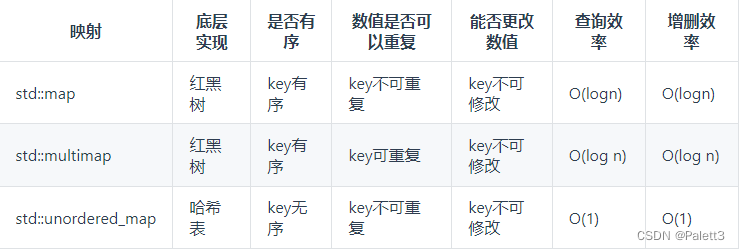
(图片来自卡哥的代码随想录)
其中map和unordered_map的区别主要就体现在底层实现。因为红黑树本质上是平衡二叉树吗,为了维护他的有序性,每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间。

复习一下unordered_map的初始化和常用函数://初始化 unordered_map<char,int> umap; //char为key,int为value unordered_map<char,int> umap1{('a',1),('b',2)}; //隐式调用构造函数 unordered_map<char,int> umap2(umap1); //拷贝构造 unordered_map<char,int> umap3(umap1.begin(),umap1.end()); //迭代器初始化 //添加元素 umap['a']++; //直接使用访问数组的方式添加 umap.insert(pair<char,int>('b',2)); //通过函数,pair对添加元素 //查找 umap.find('a'); //find获取元素的迭代器,如果没有返回umap.end() umap.count('a'); //count返回0/1,判断是否有元素 //删除 umap.erase('a'); //删除指定key umap.erase(umap.find('a')); //删除迭代器位置 umap.erase(umap.find('a'),umap.find('a') + 1); //删除迭代器范围 //获取key以及value auto it = umap.find('a'); char key = it->first; //key int value = it->second; //value另外insert函数插入的数据不会覆盖已有value的key,而用数组方式插入的数据可以覆盖。
红黑树可以参考:【算法】红黑树(二叉树)概念与查询(一)的系列文章。
242.有效的字母异位词
本题需要统计重复字符出现的次数,并且次数有有意义的,所以想到用hash table。因为元素的长度是固定的,从a-z的26个英文字母,所以可以用数组做hash table。下面给出数组的代码:
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {};
for(int i = 0; i < s.size(); i++){
record[s[i] - 'a']++;
}
for(int i = 0; i < t.size(); i++){
record[t[i] - 'a']--;
}
for(int i = 0; i < 26; i++){
if(record[i] != 0) return false;
}
return true;
}
};
这里的s[i] - 'a'相当于做了一个hash映射。
或者用unordered_map也行:
class Solution {
public:
bool isAnagram(string s, string t) {
int size1 = s.size();
int size2 = t.size();
if(size1!=size2)
return false;
unordered_map<char,int> m1;
unordered_map<char,int> m2;
for(int i = 0; i<size1;++i){
m1[s[i]]++;
}
for(int i = 0; i<size2;++i){
m2[t[i]]++;
}
if(m1==m2)
return true;
return false;
}
};
349. 两个数组的交集
本题因为输出结果中的每个元素一定是 唯一 的,我们可以不考虑输出结果的顺序,并且不需要统计出现次数,记录即可,所以想到用unordered_set作为储存答案的容器。
思路大体就是首先使用unordered_set将一个数组存入进去,然后再跟另一个数组比对,如果满足条件则存入答案中。下面给出代码:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> ans;
unordered_set<int> set(nums1.begin(),nums1.end());
for(auto it = nums2.begin(); it != nums2.end(); it++){
if(set.count(*it)) ans.insert(*it);
}
return vector<int>(ans.begin(),ans.end());
}
};
有几个细节:
- set的遍历包括vector和map都可以用迭代器遍历
- set的初始化这里使用vector的迭代器初始化
- 迭代器取值操作
*it可以获得其对应的value
因为本题把范围限定在了1 <= nums1.length, nums2.length <= 1000,所以用数组做hash table也是可以的:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> ans;
int hash[1005] = {0};
for(int num : nums1){
hash[num] = 1;
}
for(int num : nums2){
if(hash[num] == 1){
ans.insert(num);
}
}
return vector<int>(ans.begin(),ans.end());
}
};
记得使用set作为答案输出做去重操作。
202. 快乐数
本题的重点就是无限循环这几个字,当sum开始重复的时候,就代表进入了无限循环,那么这个数就不是快乐数,看到寻找重复的元素时,就想到用hash table,又因为这里是无序且不需要记录元素对应的下标或者出现次数,所以使用unordered_set即可。
代码如下:
class Solution {
public:
int get_sum(int n){
int sum = 0;
while(n){
sum += (n % 10) * (n % 10);
n = n / 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while(1) {
int sum = get_sum(n);
if (sum == 1) {
return true;
}
if (set.count(sum)) {
return false;
} else {
set.insert(sum);
}
n = sum;
}
}
};
首先写一个求和函数,然后主函数中选择一个while(1)的死循环。
这里if (set.count(sum))中的判断也可以用if (set.find(sum) != set.end())也是可以的。
1. 两数之和
都说这题是梦开始的地方,但一开始写这道题的时候也是有点懵逼的,只会暴力解,后来才想到用hash做,代码很短但是其实没有那么容易理解。大体思想就是遍历数组,在遍历数组的过程中,向map中插入新的元素,然后再遍历的时候要判断当前数组元素是否能在哈希表中找到满足条件的元素。代码如下:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> map;
for(int i = 0; i < nums.size(); i++){
if(map.find(target - nums[i]) != map.end()){
return {map.find(target - nums[i])->second,i};
}
map.insert(pair<int,int>(nums[i],i));
}
return {};
}
};
需要注意的是,要先判断,再向map中插入新元素。这里unordered_map中的key是数组中的元素,value是下标,因为unordered_map中find函数的参数是key值。另外返回类型是vector的话,可以直接返回{}。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









