









MySQL经典9道面试题
1、用一条SQL语句查询出每门课都大于80分的学生姓名。
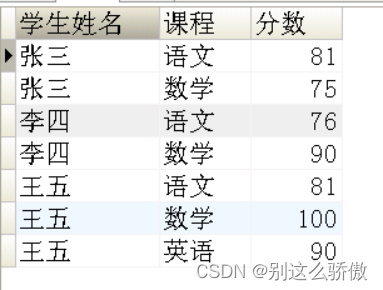
结果如下:

1.1创建表和插入数据
CREATE table if not EXISTS scores(
id INT PRIMARY KEY,
stu_name VARCHAR(20) comment '学生姓名',
subject_name VARCHAR(20) COMMENT '课程名称',
score float COMMENT '分数'
);
insert into scores(id,stu_name,subject_name,score)
VALUES (1,'张三','语文',81);
insert into scores(id,stu_name,subject_name,score)
VALUES (2,'张三','数学',75) ;
insert into scores(id,stu_name,subject_name,score)
VALUES (3,'李四','语文',76);
insert into scores(id,stu_name,subject_name,score)
VALUES (4,'李四','数学',90) ;
insert into scores(id,stu_name,subject_name,score)
VALUES (5,'王五','语文',81);
insert into scores(id,stu_name,subject_name,score)
VALUES (6,'王五','数学',100) ;
insert into scores(id,stu_name,subject_name,score)
VALUES (7,'王五','英语',90) ;
-- 查看表数据
mysql> select * from scores;
+----+----------+--------------+-------+
| id | stu_name | subject_name | score |
+----+----------+--------------+-------+
| 1 | 张三 | 语文 | 81 |
| 2 | 张三 | 数学 | 75 |
| 3 | 李四 | 语文 | 76 |
| 4 | 李四 | 数学 | 90 |
| 5 | 王五 | 语文 | 81 |
| 6 | 王五 | 数学 | 100 |
| 7 | 王五 | 英语 | 90 |
+----+----------+--------------+-------+
7 rows in set (0.00 sec)
1.2 sql解析
select a.stu_name
from scores as a
#按照学生分组
group by a.stu_name
#对每一个学生的成绩进行筛选,求学生的最低成绩>80
having min(a.score)>80
显示结果:
+‐‐‐‐‐‐+
| 姓名 |
+‐‐‐‐‐‐+
| 王五 |
+‐‐‐‐‐‐+
2、删除除了自动编号不同,其他都相同的学生冗余信息
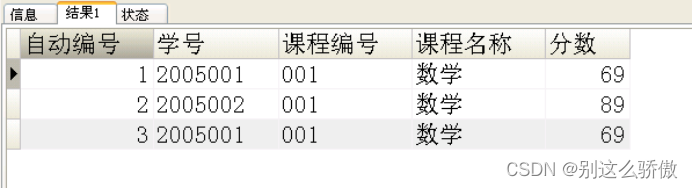
删除后的查询表的结果如下:
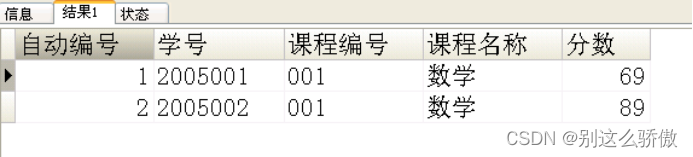
2.1创建表和插入数据
CREATE table if not EXISTS scores2(
id INT auto_increment PRIMARY KEY,
stu_no VARCHAR(20) COMMENT '学号',
stu_name VARCHAR(20) comment '学生姓名',
sub_no VARCHAR(20) COMMENT '课程编号',
sub_name VARCHAR(20) COMMENT '课程名称',
score float COMMENT '分数'
);
‐‐ 插入测试数据
insert into
scores2(stu_no,stu_name,sub_no,sub_name,score)
values('2005001','张三','001','数学',69);
insert into
scores2(stu_no,stu_name,sub_no,sub_name,score)
values('2005002','李四','001','数学',89);
insert into
scores2(stu_no,stu_name,sub_no,sub_name,score)
values('2005001','张三','001','数学',69);
#查看表数据
select * from scores2;
+----+---------+----------+--------+----------+-------+
| id | stu_no | stu_name | sub_no | sub_name | score |
+----+---------+----------+--------+----------+-------+
| 1 | 2005001 | 张三 | 001 | 数学 | 69 |
| 2 | 2005002 | 李四 | 001 | 数学 | 89 |
| 3 | 2005001 | 张三 | 001 | 数学 | 69 |
+----+---------+----------+--------+----------+-------+
3 rows in set (0.00 sec)
2.2 sql解析
#第一步:对除id以外,所有的字段进行分组,目的是得到所有记录相同的信息记录
#然后再对分组的数据进行min或者max 每一条重复的信息只取id最大或者id最小的#一条,从而过滤掉重复的信息
select min(id)
from scores2 as s
group by s.stu_no,s.stu_name,s.stu_no,s.sub_name,s.score
# 第二步:开始进行删除操作,where筛选掉重复的数据
delete from scores2 where id not in(...)
#最终sql,
/**
多用一层t临时表的目的是:在mysql中不能在不能在FROM子句中为更新指定
目标表'scores2'
**/
delete from scores2 where id not in (
select t.id
from(
select min(id) as id
from scores2
group by stu_no,stu_name,sub_no,sub_name,score
) as t
);
3、一个叫team的表,里面只有一个字段name,一共有4条纪录,分别是a,b,c,d,对应四个球队,现在四个球队进行比赛,用一条sql语句显示所有可能的比赛组合,创建表,插入测试数据。
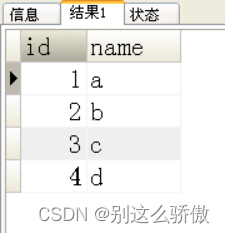
结果如下:
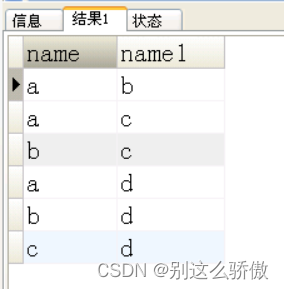
3.1创建表和插入数据
/**
**
‐#创建表
create table if not EXISTS team(
id int auto_increment PRIMARY key,
name VARCHAR(20) COMMENT '球队名称'
);
# 插入测试数据
insert into team(name) value('a');
insert into team(name) value('b');
insert into team(name) value('c');
insert into team(name) value('d');
mysql> select * from team;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+------+
4 rows in set (0.00 sec)
3.2sql解析
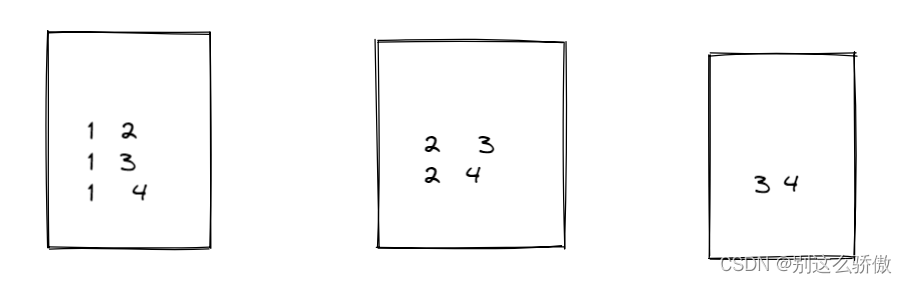
因为只有4个球队,球队的组合如上图所示,组合 1 1 ,2 2,3 3,4 4 (不存在的原因是球队不能和自己比赛)
select a.name,b.name
from team as a
join team as b
on a.id<b.id
+------+------+
| name | name |
+------+------+
| a | b |
| a | c |
| a | d |
| b | c |
| b | d |
| c | d |
+------+------+
6 rows in set (0.00 sec)
4、有如下的表结构,请创建表并插入测试数据。
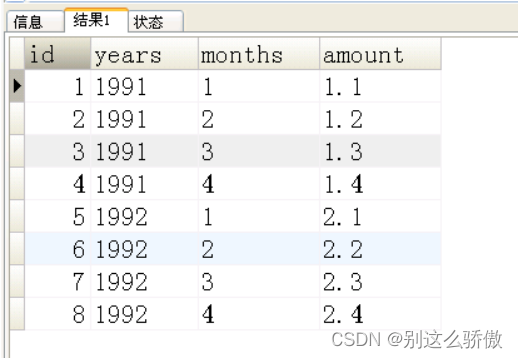
用一条sql写出如下的结果
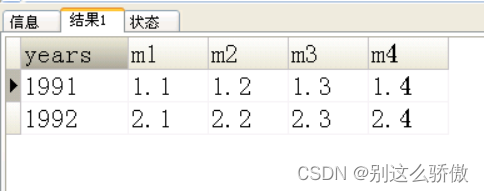
4.1创建表和插入数据
/**
** 创建表
create TABLE account(
years varchar(20),
months varchar(20),
amount varchar(20)
);
-- 插入测试数据
insert into account (years,months,amount) values('1991','1','1.1');
insert into account (years,months,amount) values('1991','2','1.2');
insert into account (years,months,amount) values('1991','3','1.3');
insert into account (years,months,amount) values('1991','4','1.4');
insert into account (years,months,amount) values('1992','1','2.1');
insert into account (years,months,amount) values('1992','2','2.2');
insert into account (years,months,amount) values('1992','3','2.3');
insert into account (years,months,amount) values('1992','4','2.4');
-- 查询数据
mysql> SELECT * from account;
+-------+--------+--------+
| years | months | amount |
+-------+--------+--------+
| 1991 | 1 | 1.1 |
| 1991 | 2 | 1.2 |
| 1991 | 3 | 1.3 |
| 1991 | 4 | 1.4 |
| 1992 | 1 | 2.1 |
| 1992 | 2 | 2.2 |
| 1992 | 3 | 2.3 |
| 1992 | 4 | 2.4 |
+-------+--------+--------+
8 rows in set (0.00 sec)
4.2sql解析
#最终sql
select a.years as years,
sum(case when a.months=1 then a.amount end)as m1,
sum(case when a.months=2 then a.amount end)as m2,
sum(case when a.months=3 then a.amount end)as m3,
sum(case when a.months=4 then a.amount end)as m4
from account as a
group by a.years;
+-------+------+------+------+------+
| years | m1 | m2 | m3 | m4 |
+-------+------+------+------+------+
| 1991 | 1.1 | 1.2 | 1.3 | 1.4 |
| 1992 | 2.1 | 2.2 | 2.3 | 2.4 |
+-------+------+------+------+------+
2 rows in set (0.00 sec)
5、复制表结构,只是复制表结构,不拷贝表中的数据(源表名:a,新表名:b),写出sql语句。
A表的结构如下:
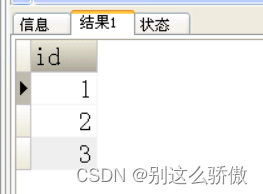
使用一条sql复制a表结构创建新表b如下但是不复制数据:
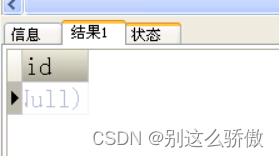
5.1创建表和插入数据
CREATE table if not EXISTS a(
id int
);
insert into a(id) values(1);
insert into a(id) values(2);
insert into a(id) values(3);
--查看表数据
mysql> select * from a;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
4.2sql解析
-- 复制表不需要数据
CREATE table a_copy_b as SELECT * from a where 1=2
结果:
mysql> select * from a_copy_b;
Empty set (0.00 sec)
-- 复制表并且复制数据
CREATE table a_copy_c as SELECT * from a where 1=1;
结果:
mysql> select * from a_copy_c;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
-- 将a_copy_c 数据插入到 a_copy_b
INSERT into a_copy_b SELECT * from a_copy_c;
6、有三张表,学生表S,课程表C,学生课程表SC,学生可以选修多门课程,一门课程可以被多个学生选修,通过SC表关联。
6.1写出建表语句;
-- 学生表
create table s(id integer primary key, name varchar(20));
-- 课程表
create table c(id integer primary key, name varchar(20));
-- 学生的选课表
create table sc(
sid integer,
cid integer,
primary key(sid,cid), -- 联合主键
foreign key (sid) references s(id), -- 外键
foreign key (cid) references c(id) -- 外键
);
INSERT into s(id,name) values (1,'zhangsan');
INSERT into s(id,name) values (2,'lisi');
INSERT into s(id,name) values (3,'wangwu');
INSERT into c(id,name) values (10,'git');
INSERT into c(id,name) values (20,'oracle');
INSERT into c(id,name) values (30,'mysql');
INSERT into c(id,name) values (50,'linux');
INSERT into c(id,name) values (40,'hive');
SELECT * from s;
SELECT * from c;
SELECT * from sc;
6.2写出SQL语句,查询选修了所有选修课程的学生;
select s.id,count(*)
from s
join sc
on s.id=sc.sid
join c
on c.id=sc.cid
group by s.id
having count(c.id)=(select count(distinct id) from c)
6.3写出SQL语句,查询选修了至少5门以上的课程的学生。
#解析3:
select s.id,count(*)
from s
join sc
on s.id=sc.sid
join c
on c.id=sc.cid
group by s.id
having count(c.id)>=5
7、创建如下的表结构,并且插入测试数据,写出sql
表一:
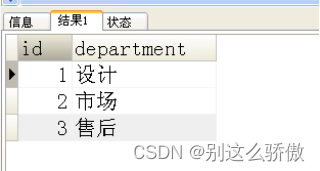
表二:depId为表一的id
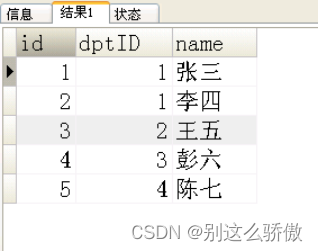
用一条sql查询出如下的结果
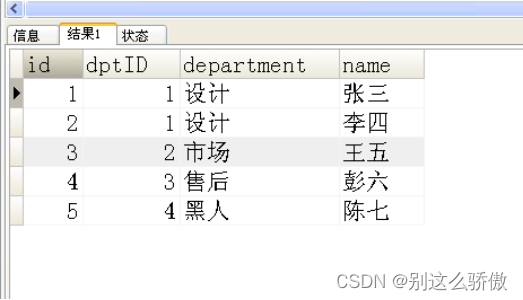
7.1创建表和插入数据;
create table testtable1
(
id int PRIMARY KEY,
department varchar(12)
);
-- 插入测试数据
select * from testtable1;
insert into testtable1(id,department) values(1,'设计');
insert into testtable1(id,department) values(2,'市场');
insert into testtable1(id,department) values(3,'售后');
-- 创建表二
create table testtable2
(
id int PRIMARY KEY,
dptID int,
name varchar(12)
);
-- 插入测试数据
insert into testtable2(id,dptId,name) values(1,1,'张三');
insert into testtable2(id,dptId,name) values(2,1,'李四');
insert into testtable2(id,dptId,name) values(3,2,'王五');
insert into testtable2(id,dptId,name) values(4,3,'彭六');
insert into testtable2(id,dptId,name) values(5,4,'陈七');
select * from testtable1;
select * from testtable2;
7.2sql解析;
select b.id,b.dptid,if(a.department is not null,a.department,'黑人'),b.name
from testtable1 as a
right join testtable2 as b
on a.id=b.dptid
8、有如下表结构,写出创建表的sql并且插入测试数据,其中:p_id为产品ID,p_num为产品库存量,s_id为仓库ID。
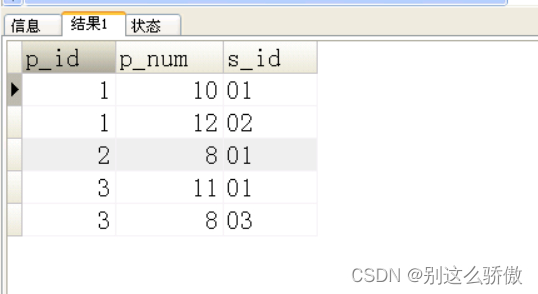
请用一条sql插叙出如下的结果
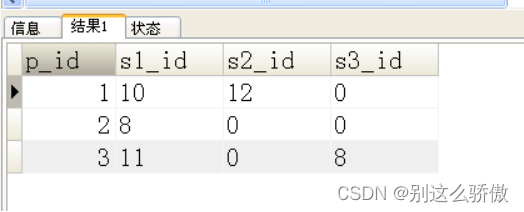
其中:s1_id为仓库1的库存量,s2_id为仓库2的库存量,
s3_id为仓库3的库存量。如果该产品在某仓库中无库存量,
那么就是0代替。
结果如下:
8.1创建表和插入数据;
create table if not EXISTS a1(
p_id int COMMENT '产品id',
p_num int COMMENT '产品数量',
s_id varchar(20) COMMENT '仓库编号'
);
-- 插入测试数据
insert into a1(p_id,p_num,s_id)
values(1,10,'01');
insert into a1(p_id,p_num,s_id)
values(1,12,'02');
insert into a1(p_id,p_num,s_id)
values(2,8,'01');
insert into a1(p_id,p_num,s_id)
values(3,11,'01');
insert into a1(p_id,p_num,s_id)
values(3,8,'03');
select * from a1;
8.2sql解析:
select p_id,
ifnull(sum(case when s_id='01' then p_num end),0) as s1_id,
ifnull(sum(case when s_id='02' then p_num end),0) as s2_id,
ifnull(sum(case when s_id='03' then p_num end),0) as s3_id
from a1
group by p_id
+------+-------+-------+-------+
| p_id | s1_id | s2_id | s3_id |
+------+-------+-------+-------+
| 1 | 10 | 12 | 0 |
| 2 | 8 | 0 | 0 |
| 3 | 11 | 0 | 8 |
+------+-------+-------+-------+
3 rows in set (0.00 sec)
9、数据库表如下,创建表,插入测试数据列出所有年龄比所属主管年龄大的人的ID和名字,manger是该人所属部门领导的id
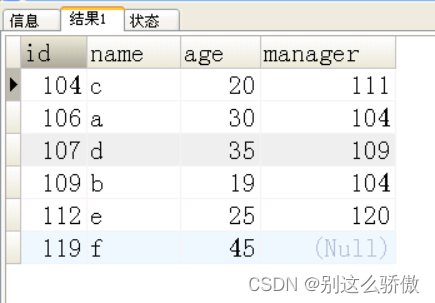
结果如下:
9.1创建表和插入数据;
create table person1(
id int PRIMARY key,
name VARCHAR(20),
age INT,
manager INT
);
-- 插入测试数据
insert into person1(id,name,age,manager)
values(106,'a',30,104);
insert into person1(id,name,age,manager)
values(109,'b',19,104);
insert into person1(id,name,age,manager)
values(104,'c',20,111);
insert into person1(id,name,age,manager)
values(107,'d',35,109);
insert into person1(id,name,age,manager)
values(112,'e',25,120);
insert into person1(id,name,age)
values(119,'f',45);
SELECT * from person1;
9.2sql解析:
select b.id,b.name,b.age,a.id,a.name,a.age
#--领导表 a
from person1 as a
join person1 as b
on b.manager=a.id
where b.age>a.age
















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











