







 本文通过数据分析,揭示了中国、香港和台湾地区电影产业的发展趋势,包括每年的电影数量、平均评分和评分人数。同时,深入探讨了不同电影类型的数量、平均评分和评分人数,以及高评分电影的特点。
本文通过数据分析,揭示了中国、香港和台湾地区电影产业的发展趋势,包括每年的电影数量、平均评分和评分人数。同时,深入探讨了不同电影类型的数量、平均评分和评分人数,以及高评分电影的特点。
import pandas as pd
import numpy as np
读取豆瓣电影数据文档
df=pd.read_csv(‘doban.csv’)
df.head(1)
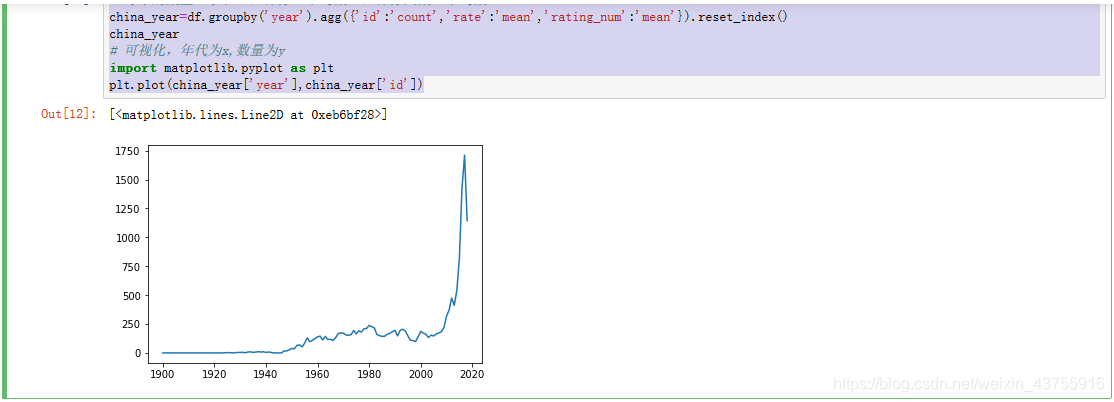
每年的数量(求和),评分(平均数),评分人数(平均数)
china_year=df.groupby(‘year’).agg({‘id’:‘count’,‘rate’:‘mean’,‘rating_num’:‘mean’}).reset_index()
china_year
可视化,年代为x,数量为y
import matplotlib.pyplot as plt
plt.plot(china_year[‘year’],china_year[‘id’])
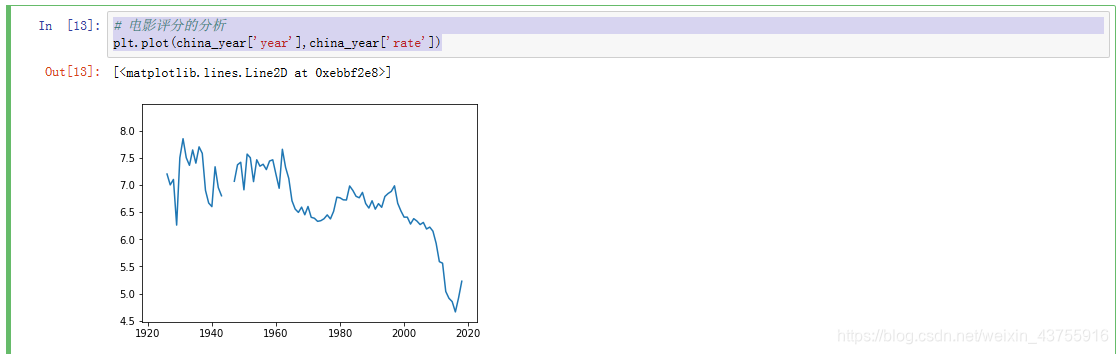
电影评分的分析
plt.plot(china_year[‘year’],china_year[‘rate’])
筛选出大陆的电影
df_mainland=df.loc[df[‘is_cn’]==1]
筛选出香港的电影
df_hk=df.loc[df[‘is_hk’]==1]
筛选出台湾的电影
df_tw=df.loc[df[‘is_tw’]==1]
df_tw.head()
大陆每年的数量,评分,评分人数
mainland_year=df_mainland.groupby(‘year’).agg({‘id’:‘count’,‘rate’:‘mean’,‘rating_num’:‘mean’}).reset_index()
香港每年的数量,评分,评分人数
hk_year=df_hk.groupby(‘year’).agg({‘id’:‘count’,‘rate’:‘mean’,‘rating_num’:‘mean’}).reset_index()
台湾每年的数量,评分,评分人数
tw_year=df_tw.groupby(‘year’).agg({‘id’:‘count’,‘rate’:‘mean’,‘rating_num’:‘mean’}).reset_index()
tw_year.head()
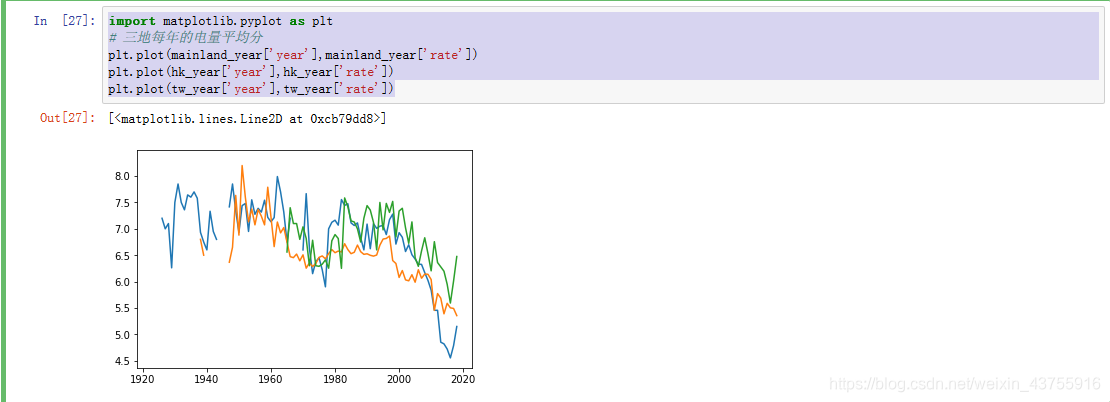
import matplotlib.pyplot as plt
三地每年的电量平均分
plt.plot(mainland_year[‘year’],mainland_year[‘rate’])
plt.plot(hk_year[‘year’],hk_year[‘rate’])
plt.plot(tw_year[‘year’],tw_year[‘rate’])
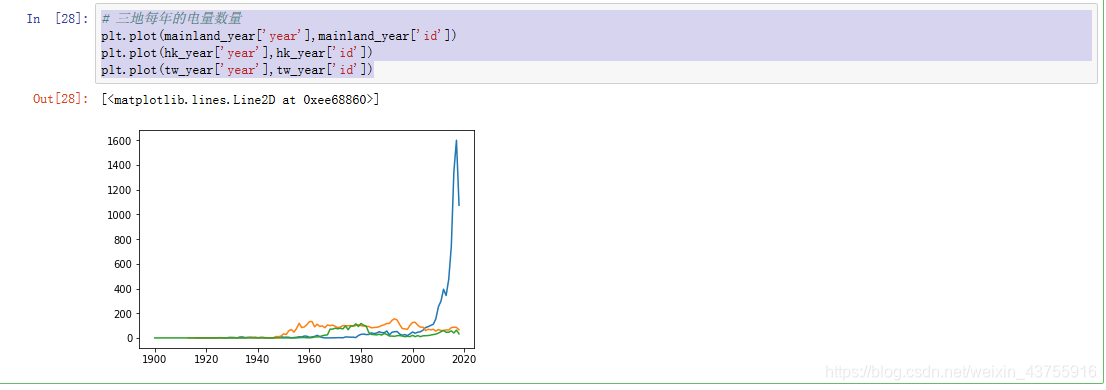
三地每年的电量数量
plt.plot(mainland_year[‘year’],mainland_year[‘id’])
plt.plot(hk_year[‘year’],hk_year[‘id’])
plt.plot(tw_year[‘year’],tw_year[‘id’])
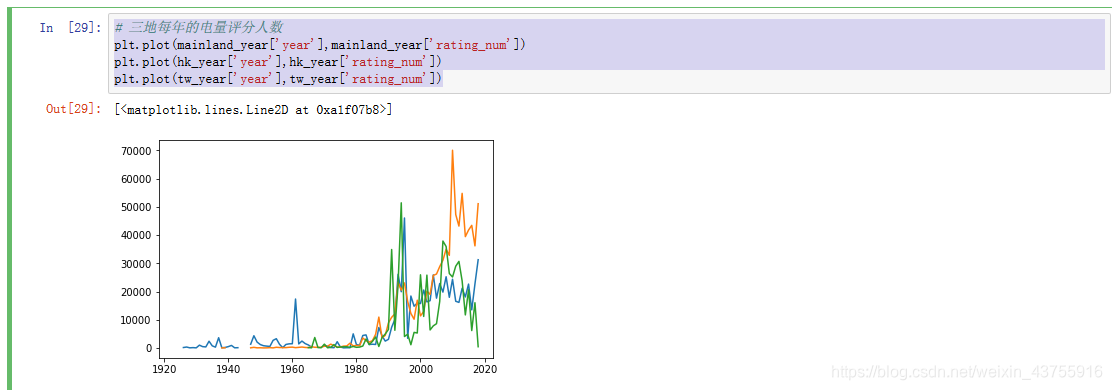
三地每年的电量评分人数
plt.plot(mainland_year[‘year’],mainland_year[‘rating_num’])
plt.plot(hk_year[‘year’],hk_year[‘rating_num’])
plt.plot(tw_year[‘year’],tw_year[‘rating_num’])
coldict = {‘is_drama’:‘剧情’,‘is_comedy’:‘喜剧’,‘is_action’:‘动作’,‘is_romance’:‘爱情’,
‘is_scifi’:‘科幻’,‘is_cartoon’:‘动画’,‘is_mystery’:‘悬疑’,‘is_thriller’:‘惊悚’,
‘is_horror’:‘恐怖’,‘is_crime’:‘犯罪’,‘is_homosexua’:‘同性’,‘is_music’:‘音乐’,
‘is_musical’:‘歌舞’,‘is_biographical’:‘传记’,‘is_historical’:‘历史’,‘is_war’:‘战争’,
‘is_western’:‘西部’,‘is_fantasy’:‘奇幻’,‘is_adventure’:‘冒险’,‘is_disaster’:‘灾难’,
‘is_sowordsmen’:‘武侠’,‘is_erotic’:‘情色’}
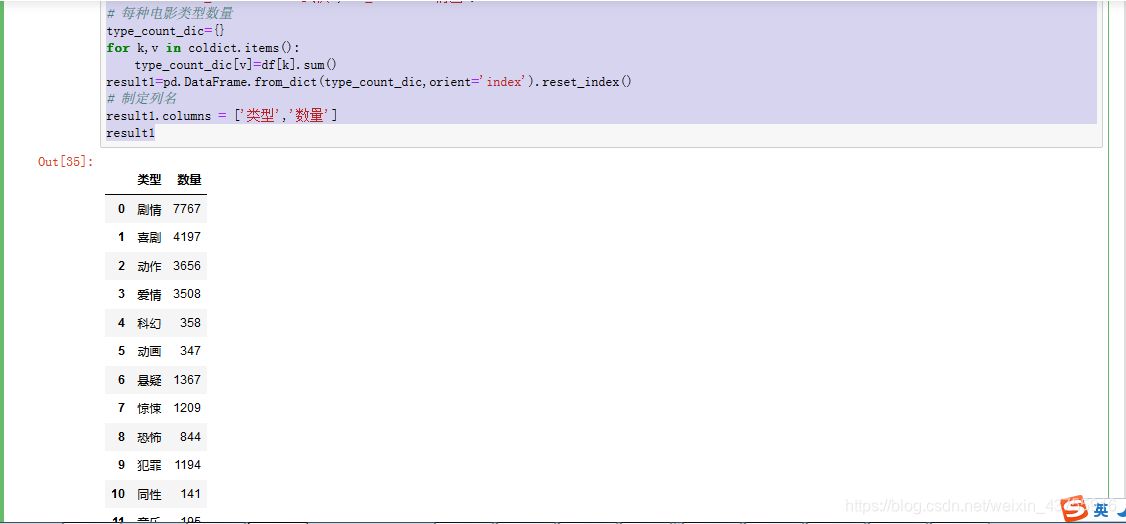
每种电影类型数量
type_count_dic={}
for k,v in coldict.items():
type_count_dic[v]=df[k].sum()
result1=pd.DataFrame.from_dict(type_count_dic,orient=‘index’).reset_index()
制定列名
result1.columns = [‘类型’,‘数量’]
result1
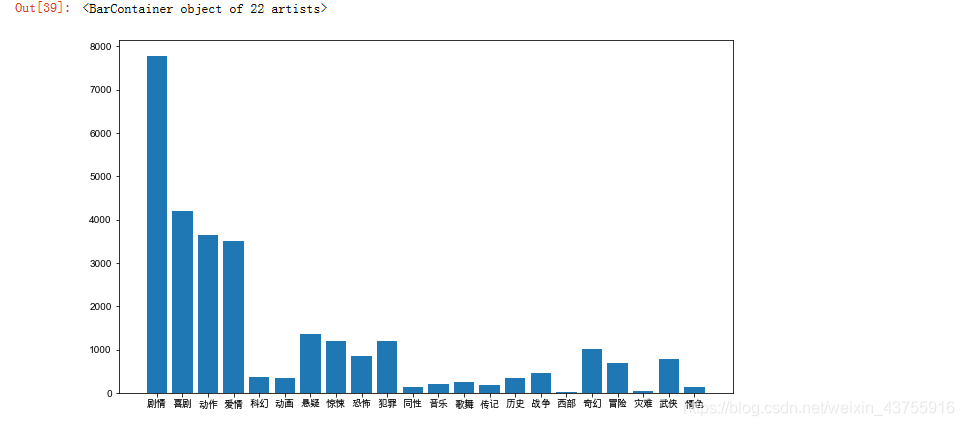
figsize
plt.figure(figsize=(11, 6.5))
设置字体
plt.rcParams[‘font.sans-serif’]=[‘Arial Unicode MS’]
绘图柱状图
plt.bar(result1[‘类型’],result1[‘数量’])
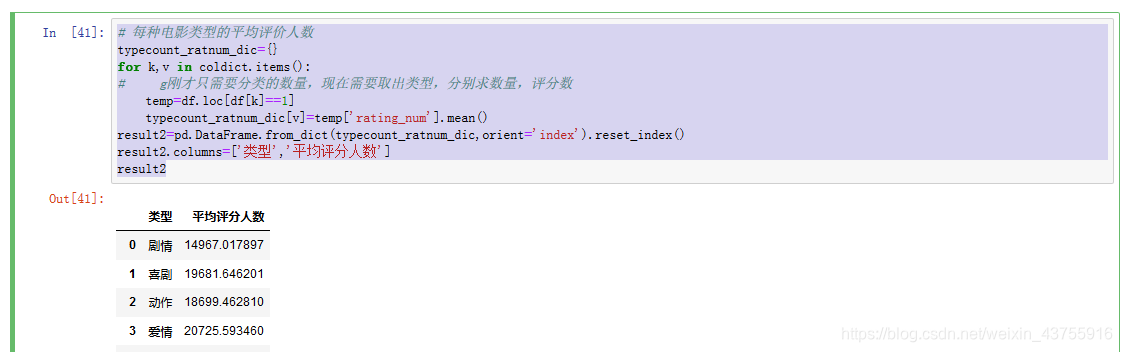
每种电影类型的平均评价人数
typecount_ratnum_dic={}
for k,v in coldict.items():
刚才只需要分类的数量,现在需要取出类型,分别求数量,评分数
temp=df.loc[df[k]==1]
typecount_ratnum_dic[v]=temp['rating_num'].mean()
result2=pd.DataFrame.from_dict(typecount_ratnum_dic,orient=‘index’).reset_index()
result2.columns=[‘类型’,‘平均评分人数’]
result2
设置大小
plt.figure(figsize=(11,7))
设置排序
result2=result2.sort_values(‘平均评分人数’,ascending=False)
柱状图
plt.bar(result2[‘类型’],result2[‘平均评分人数’])
plt.show()
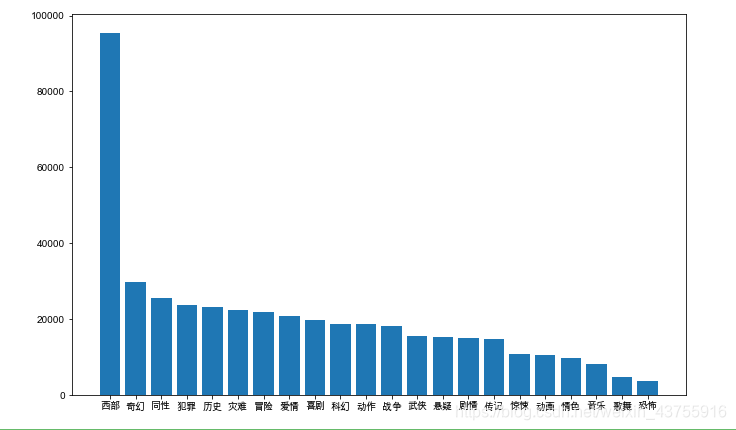
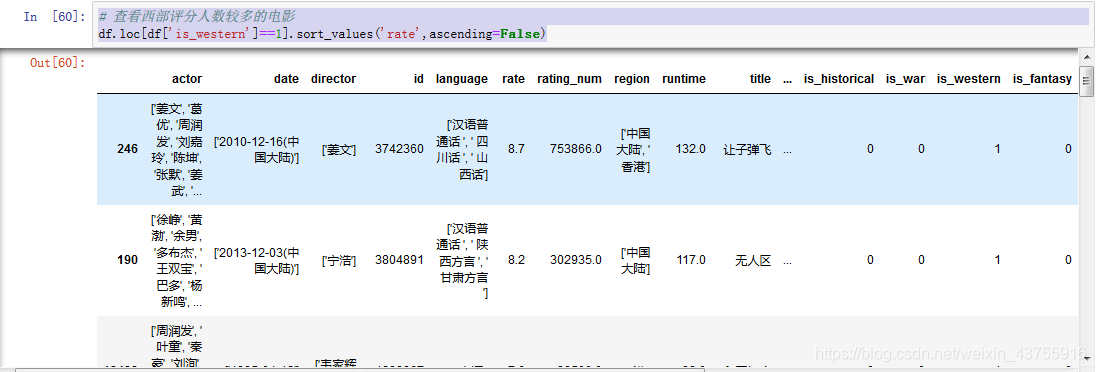
查看西部评分人数较多的电影
df.loc[df[‘is_western’]==1].sort_values(‘rate’,ascending=False)
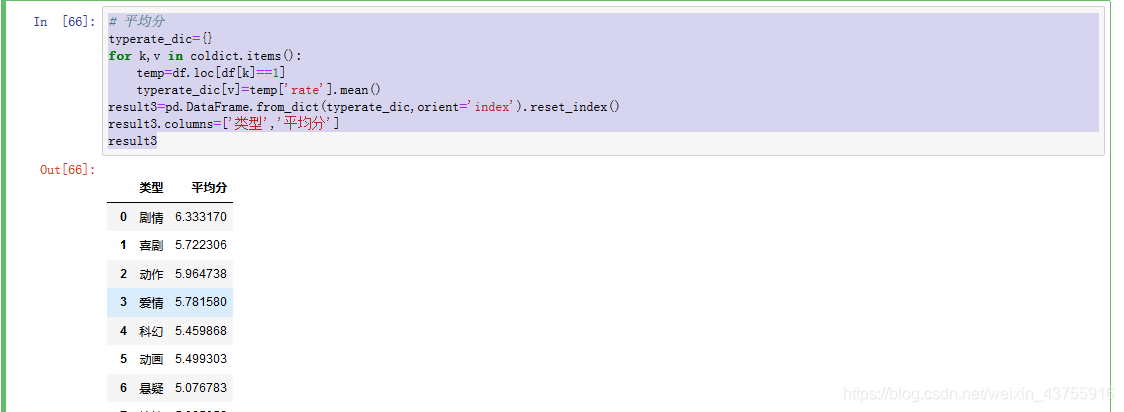
平均分
typerate_dic={}
for k,v in coldict.items():
temp=df.loc[df[k]==1]
typerate_dic[v]=temp[‘rate’].mean()
result3=pd.DataFrame.from_dict(typerate_dic,orient=‘index’).reset_index()
result3.columns=[‘类型’,‘平均分’]
result3
设置大小
plt.figure(figsize=(11,8))
排序
result3=result3.sort_values(‘平均分’,ascending=False)
plt.bar(result3[‘类型’],result3[‘平均分’])

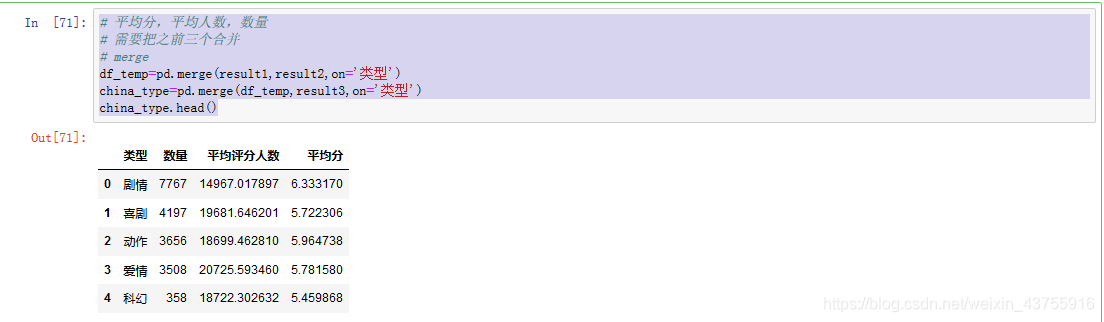
平均分,平均人数,数量
需要把之前三个合并
merge
df_temp=pd.merge(result1,result2,on=‘类型’)
china_type=pd.merge(df_temp,result3,on=‘类型’)
china_type.head()
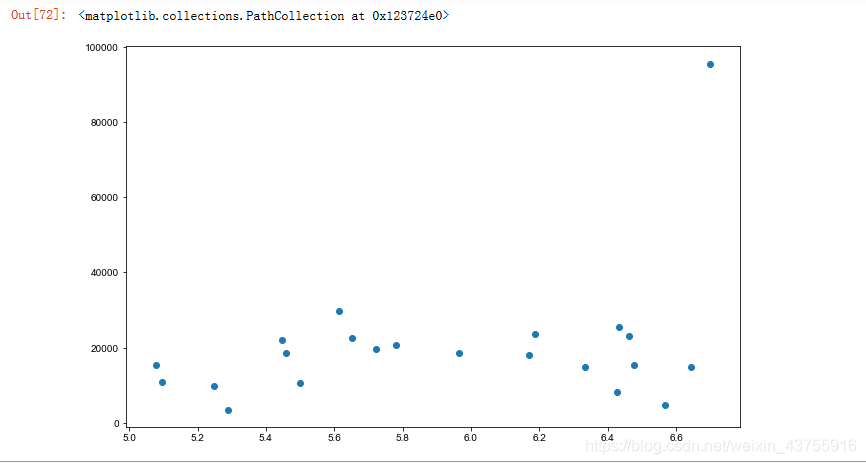
plt.figure(figsize=(11,7))
plt.scatter(china_type[‘平均分’],china_type[‘平均评分人数’])
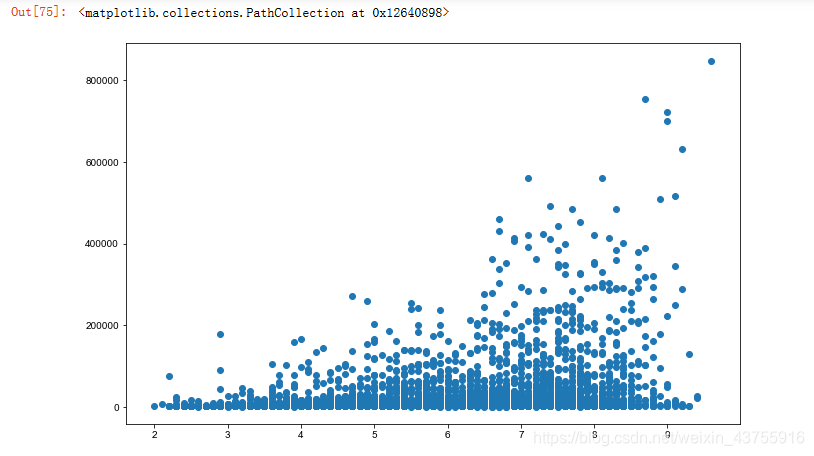
剔除评分人数少于500的
df0=df.loc[df[‘rating_num’]>=500]
plt.figure(figsize=(11,7))
plt.scatter(df0[‘rate’],df0[‘rating_num’])

















 6415
6415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









