










一、KNN简介
KNN作为一种监督学习方法,其工作机制为:给定测试样本,基于某种距离度量找出训练几种与其最靠近的k个训练样本,然后基于这k个“邻居”的信息进行预测。
上述提到的某种距离度量主要有三种方法:曼哈顿距离、欧式距离和闵可夫斯基距离。在本文中,距离的计算采用的是欧式距离:
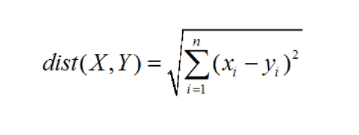
KNN模型是一种“懒惰学习”的代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再处理。
KNN可以在分类和回归两种任务中使用,下面将依次介绍。
二、分类任务
基本思想:
通常,在分类任务中可以使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果。
使用最近邻的类标号决定未知记录的类标号 (例如, 多数表决)

实例
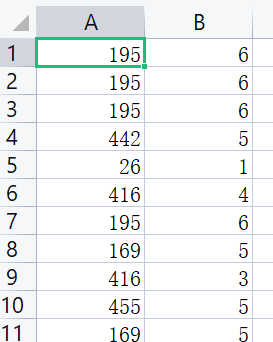
训练数据包含特征值feature:扔球的位置;标签label:球落入的篮筐。
数据如下图所示,本文最后附有数据下载地址。
思路:
1、把数据划充分打散,并划分为训练数据和测试数据两部分。
2、计算预测点与训练集中每个数据的距离;然后排序,选择最近的前k个;找出前k个中标签值最多的那个,即为预测值。
3、比较预测值和真实标签值是否相同。
4、重复2,3步骤,直到测试数据都被预测一遍,并计算最终预测准确率
代码:
import numpy as np
import collections as co
def knn(k,predictPoint,feature,label):
# 计算每个投置地与predictPoint的距离
distance = list(map(lambda x: abs(predictPoint - x), feature))
# 对distance的集合元素冲销到大排序,返回的是下表 np.sort()只是把集合里面的内容进行排序
sortindex = np.argsort(distance)
# 用排序的sortindex来操作lable集合
sortlabel = label[sortindex]
# 返回前k个中出现最多次数的标签值
return co.Counter(sortlabel[0:k]).most_common(1)[0][0]
if __name__ == '__main__':
data = np.loadtxt("数据/data0.csv", delimiter=",")
# 处理数据,把数据充分打散,拆分成训练集和测试集
np.random.shuffle(data)
#测试数据
testdata = data[:100]
#训练数据
traindata = data[100:-1]
# 输入值,特征数据
feature = traindata[:,0]
# label 标签值
label = traindata[:,-1]
#k的取值,取值不同,准确率也会相应的变化。
k=5
count = 0
for item in testdata:
predict=knn(k,item[0],feature,label)
real=item[1]
if predict ==real:
count=count+1
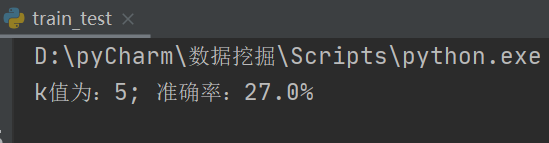
print("k值为:{}; 准确率:{}%".format(k,count*100.0/len(testdata)))
运行截图:
多个维度:
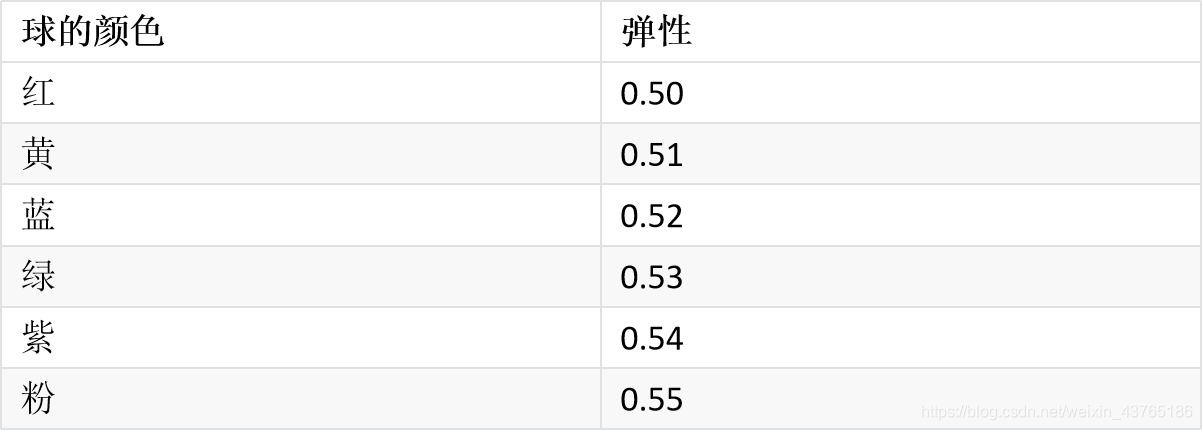
上述在预测时只考虑到了投掷位置对其的影响,然而在实际中,影响因素常常有多个,即特征值有多个。比如在上述基础上加一个球的弹性特征值:
与一维不同的是,要注意以下几点:
- 由于球的颜色为汉字,要把其转化为相应的数字,转化方法:在用np.loadtxt()加载数据文件时,它提供了converters参数,可以进行转化,官方给出的使用说明如下图片所示。
即例如converters={1: color2num}意思是将文件中第一列数据通过调用color2num函数将字符串解析为所需值。

- 涉及到多维向量计算欧氏距离时不能再采用 distance = list(map(lambda x: abs(predictPoint - x), feature))
可以采用以下通用方法:
#计算xi-yi
matrixtemp = (feature - predictPoint)
#计算(xi-yi)的平方
matrixtemp2 = np.square(matrixtemp)
#计算欧式距离, 此处一定要设置axis=1,它表示按行的方向相加,返回每个行的值;
# axis=0按列相加,返回每个列的值;如果不写则返回的是所有值相加的结构
distance = np.sqrt(np.sum(matrixtemp2, axis=1))
全部代码:
import numpy as np
import collections as co
def color2num(str):
dict={"红":0.50,"黄":0.51,"蓝":0.52,"绿":0.53,"紫":0.54,"粉":0.55}
return dict[str]
#考虑多个维度
def knn2(k,predictPoint,feature,label):
#计算xi-yi
matrixtemp = (feature - predictPoint)
#计算(xi-yi)的平方
matrixtemp2 = np.square(matrixtemp)
#计算欧式距离, 此处一定要设置axis=1,它表示按行的方向相加,返回每个行的值;
# axis=0按列相加,返回每个列的值;如果不写则返回的是所有值相加的结构
distance = np.sqrt(np.sum(matrixtemp2, axis=1))
# 对distance的集合元素冲销到大排序,返回的是下表 np.sort()只是把集合里面的内容进行排序
sortindex = np.argsort(distance)
# 用排序的sortindex来操作lable集合
sortlabel = label[sortindex]
# 返回前k个中出现最多次数的标签值
return co.Counter(sortlabel[0:k]).most_common(1)[0][0]
if __name__ == '__main__':
# 由于数据中颜色值为中文需要把它转化为数字
# 通过converters={1: color2num}进行转化,
# 意思是将文件中第一列数据通过调用color2num函数将字符串解析为所需值。
data = np.loadtxt("数据/data1.csv", delimiter=",", converters={1: color2num}, encoding="gbk")
np.random.shuffle(data)
testdata = data[:100]
traindata = data[100:-1]
# 输入值,特征数据
feature = traindata[:,0:2]
# label 标签值
label = traindata[:,-1]
k=5
x_test=testdata[:,0:2]
y_test=testdata[:,-1]
count = 0
for i in range(len(x_test)):
predict=knn2(k,x_test[i],feature,label)
real=y_test[i]
if predict ==real:
count=count+1
print("k值为:{}; 准确率:{}%".format(k,count*100.0/len(testdata)))
运行截图:
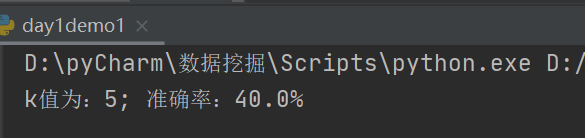
从上面实验结果我们也可以看出,当考虑的特征值增加时,准确率也相应的增加。
三、回归任务
&embp;&embp;在回归任务中可以使用“平均法”,即选择k个样本中出现最多的类别标记的平均值作为预测结果;还可以基于距离远近进行加权平均,距离越近的样本权重越大。
实例
预测房价时,考虑特征值:经度,维度,面积。label标签值为房的具体价格
由于给出的数据文件中含有很多数据,因此需要挑出我们实验所需要用到的
feature = np.loadtxt(“数据/kc_house_data.csv”,delimiter=",",skiprows=1,usecols=(17,18,6))
label = np.loadtxt(“数据/kc_house_data.csv”, delimiter=",", skiprows=1, usecols=(2))
usecols=(17,18,6)表示选择第17,18,6列作为特征值。
代码:
import numpy as np
def knn(k,predictPoint,feature,label):
matrixtemp = (feature - predictPoint)
matrixtemp2 = np.square(matrixtemp)
distance = np.sqrt(np.sum(matrixtemp2, axis=1))
sortindex = np.argsort(distance)
sortlabel = label[sortindex]
predictprice = np.sum(sortlabel[0:k]) / k
return predictprice
if __name__ == '__main__':
feature = np.loadtxt("数据/data2.csv",delimiter=",",skiprows=1,usecols=(17,18,6))
label = np.loadtxt("数据/data2.csv", delimiter=",", skiprows=1, usecols=(2))
predictPoint=np.array([47.5112,-122.257,5660])
predict=knn(450,predictPoint,feature,label)
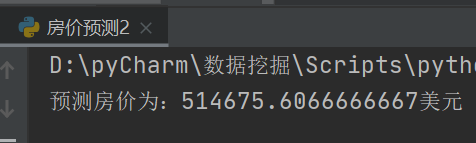
print("预测房价为:{}美元".format(predict))
运行截图:
上面用到的实验数据请从下面链接中获取
提取码为4xkx
链接:https://pan.baidu.com/s/1qD4zj3L6054UCiVxDsLX0Q
提取码:4xkx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









