







 该文介绍了一种使用Python进行Bilibili数据抓取的方法,主要关注获取季节列表的封面图片,涉及网络请求和文件操作。
该文介绍了一种使用Python进行Bilibili数据抓取的方法,主要关注获取季节列表的封面图片,涉及网络请求和文件操作。
本文是本人最近学习Python爬虫所做的小练习。
如有侵权,请联系删除。
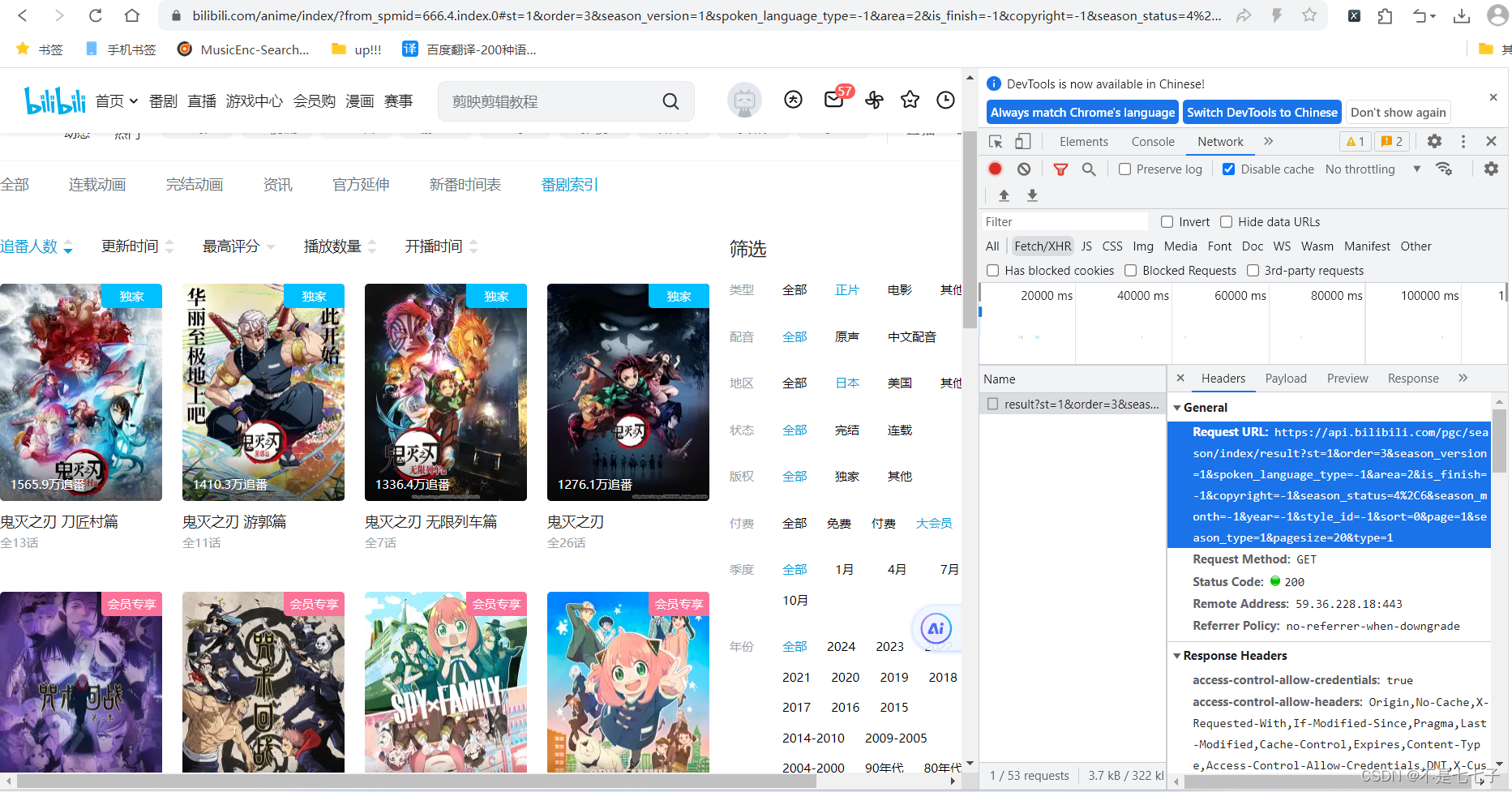
页面获取url
代码
import requests
import os
import re
# 创建文件夹
path = os.getcwd() + '/images'
if not os.path.exists(path):
os.mkdir(path)
# 当前页数
page = 1
# 总页数
total_page = 2
# 自动翻页,获取全部数据
def get_data():
global page, total_page
while page <= total_page:
# 地址
url = f"https://api.bilibili.com/pgc/season/index/result?st=1&order=3&season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&sort=0&page={page}&season_type=1&pagesize=20&type=1"
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.1311 SLBChan/105',
}
# 发送请求
response = requests.get(url, headers=headers)
# json数据格式
items = response.json()
# 循环遍历
for data in items['data']['list']:
# 标题
title = data.get('title')
# 封面
cover = data.get('cover')
# 下载图片到images文件夹中,文件名:title
if title != '' and cover != '':
download_image(title, cover)
total = items.get('data')['total']
size = items.get('data')['size']
total_page = get_page_count(total, size)
page += 1
# 下载图片
def download_image(title, cover):
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.1311 SLBChan/105',
}
res = requests.get(cover, headers=headers)
# 判断标题是否含有\/:*?"<>|,文件命名不能含有这些,如果有,则用下划线_取代
new_title = validateTitle(title)
with open(path + '/' + new_title + '.jpg', mode='wb') as f:
# 图片内容写入文件
f.write(res.content)
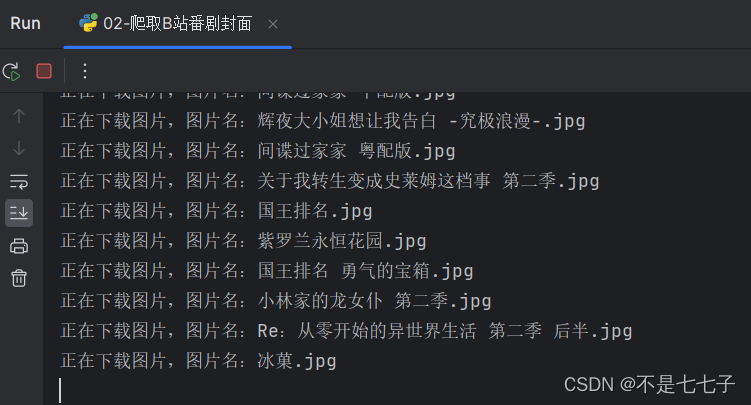
print(f"正在下载图片,图片名:{title}.jpg")
# 去除文件中的非法字符(正则表达式)
def validateTitle(title):
pattern = r"[\\\/\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, '_', title)
return new_title
# 求页数
def get_page_count(total, page):
page_count = total // page
if total % page != 0:
page_count += 1
return page_count
if __name__ == '__main__':
get_data()
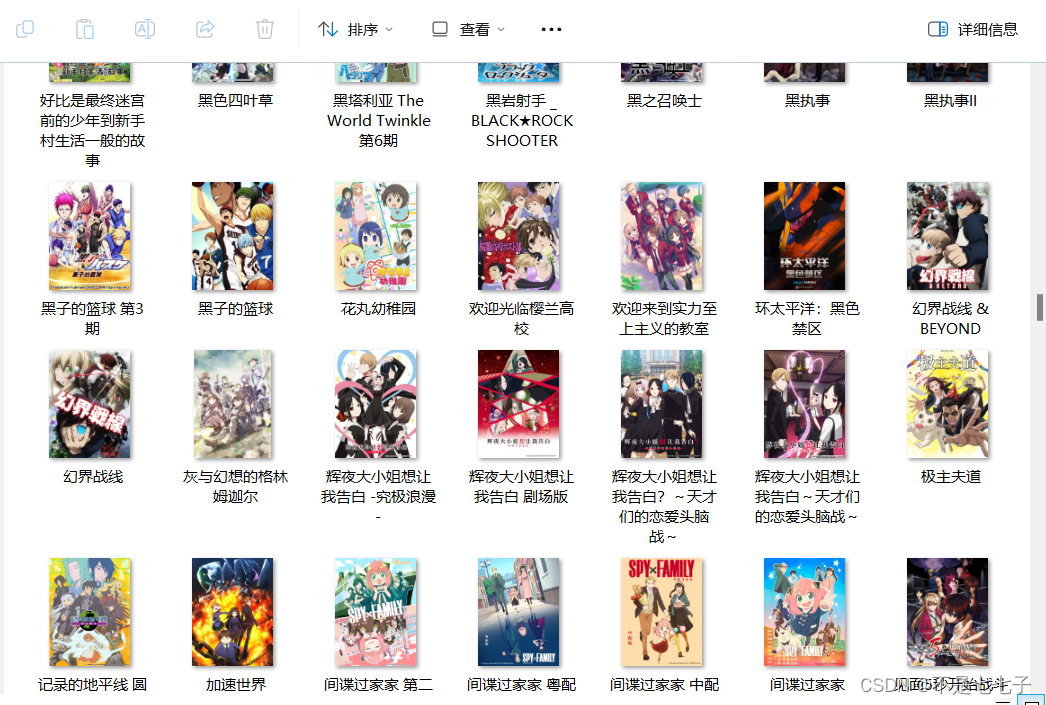
效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









