






 本文深入讲解了Python中Pandas库的DataFrame数据结构,包括其创建方式、数据查看与筛选、基本操作等内容。DataFrame类似于Excel表格,能存储多种类型的数据,支持通过位置、列名和行名进行数据访问。
本文深入讲解了Python中Pandas库的DataFrame数据结构,包括其创建方式、数据查看与筛选、基本操作等内容。DataFrame类似于Excel表格,能存储多种类型的数据,支持通过位置、列名和行名进行数据访问。
pandas时一个快元的python项目。最重要的两个数据结构:DataFrame和Series
DataFrame
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位。
行(英文row),列(英文column)。
2 创建DataFrame
在所有操作之前当然要先import必要的pandas库,因为pandas常与numpy一起配合使用,所以也一起import吧。
2.1 直接创建
可以直接使用pandas的DataFrame函数创建,比如接下来我们随机创建一个4*4的DataFrame。
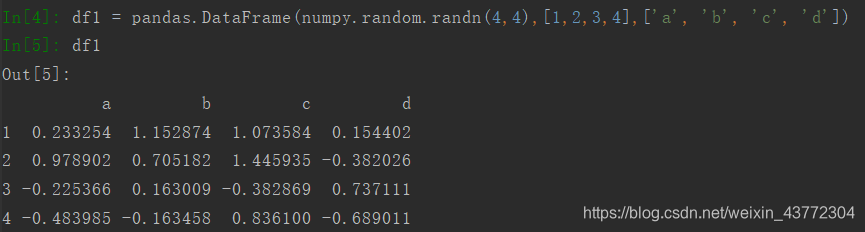
pandas.DataFrame()中第一个参数是存放在DataFrame里的数据,第二个参数index就是之前说的行名(或者应该叫索引),第三个参数columns是之前说的列名。
后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配,不然会报错。当然,这两个参数是可选的,你可以选择不设置。
而且这两个list是可以一样的,但是每行每列的名字在index或columns里要是唯一的。
2.2 使用字典创建
仍然是使用DataFrame这个函数,但是字典的每个key的value代表一列,而key是这一列的列名。
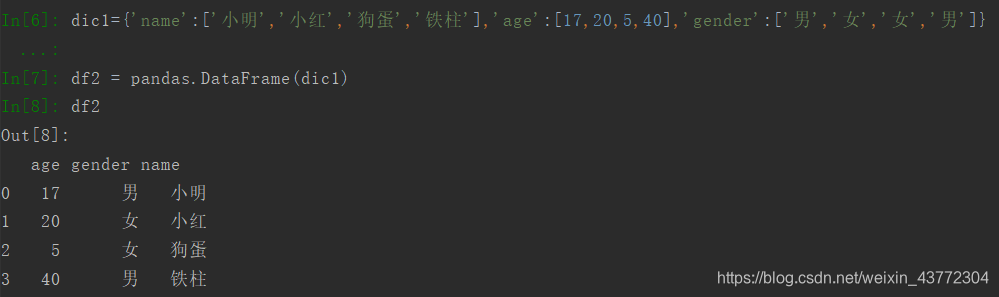
2.3 从外部CSV文件创建
from pandas.io.parsers import read_csv
df = read_csv('*.csv')
3 查看与筛选数据
2.2 使用字典创建
python没有matlab的工作区直接查看变量与内容,这大概是python科学计算的一个缺点。所以需要格外的代码来查看,最基本的直接写变量名与print就不说了。
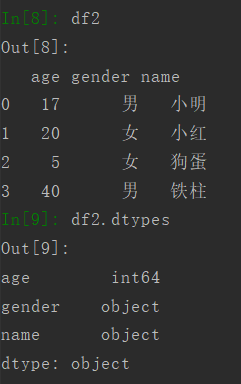
3.1 查看列的数据类型
使用dtypes方法可以查看各列的数据类型,比如说刚刚的df2。
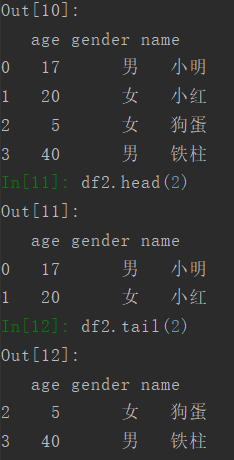
3.2 查看DataFrame的头尾
使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。
使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。
3.3 查看行名与列名
使用index查看行名,columns查看列名。
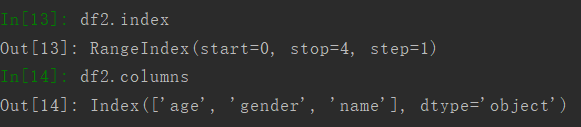
3.4 查看数据值
使用values可以查看DataFrame里的数据值,返回的是一个数组。

另一种操作,使用loc或者iloc查看数据值。区别是loc是根据行名,iloc是根据数字索引(也就是行号)。
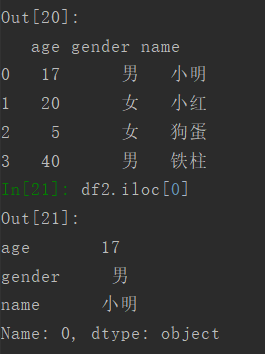
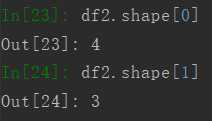
3.5 查看行列数
使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。
4 基本操作
DataFrame有些方法可以直接进行数据统计,矩阵计算之类的基本操作。
4.1 转置
直接字母T,df2.T。
4.2 描述性统计
使用describe可以对数据根据列进行描述性统计。比如说对df2进行描述性统计。
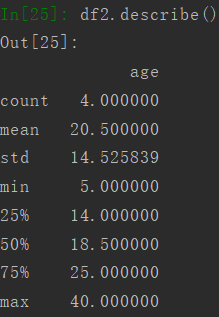
4.3 计算
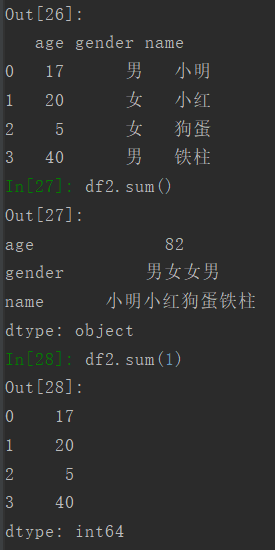
使用sum默认对每列求和,sum(1)为对每行求和。
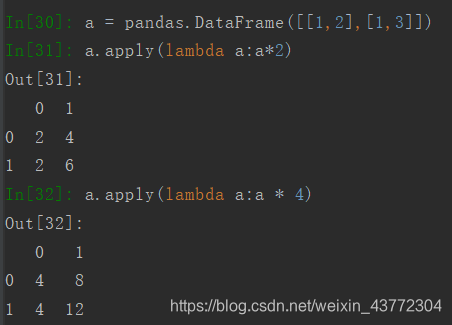
数乘运算使用apply,如果元素是字符串,则会把字符串再重复一遍。
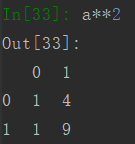
乘方运算跟matlab类似,直接使用两个*,比如
4.4 新增
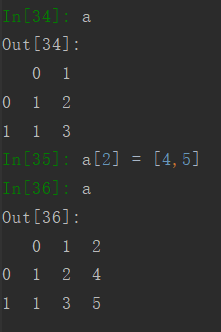
扩充列可以直接像字典一样,列名对应一个list,但是注意list的长度要跟index的长度一致。
使用insert,使用这个方法可以指定把列插入到第几列,其他的列顺延。
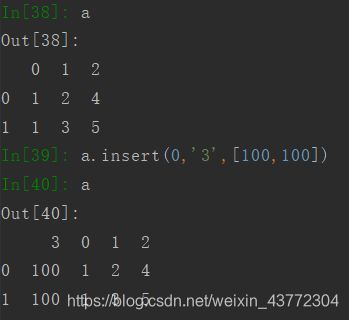
4.5 合并
使用join可以将两个DataFrame合并,但只根据行列名合并,并且以作用的那个DataFrame的为基准。如下所示,新的df7是以df2的行号index为基准的。
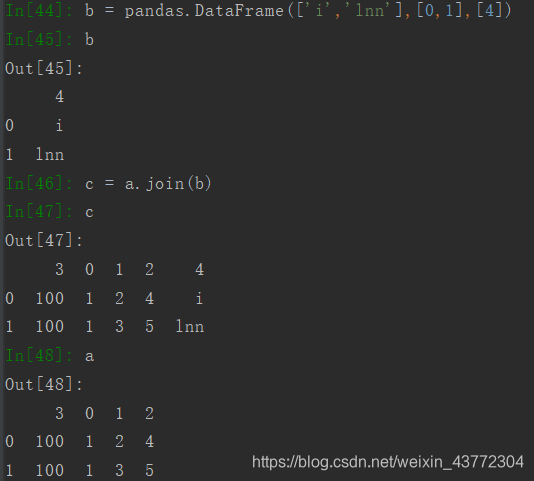
如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe。
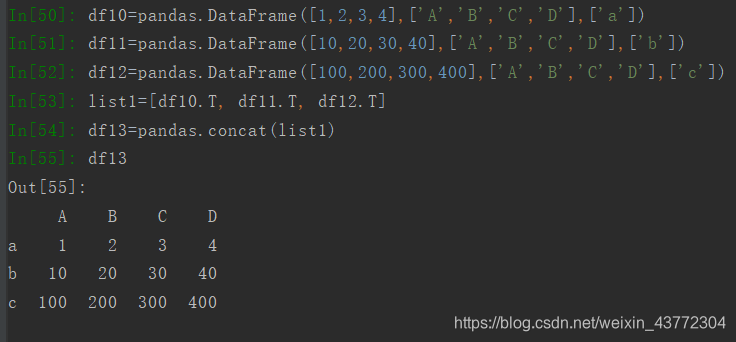
######################分割线############################
Series


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









