







流程图:
步骤:
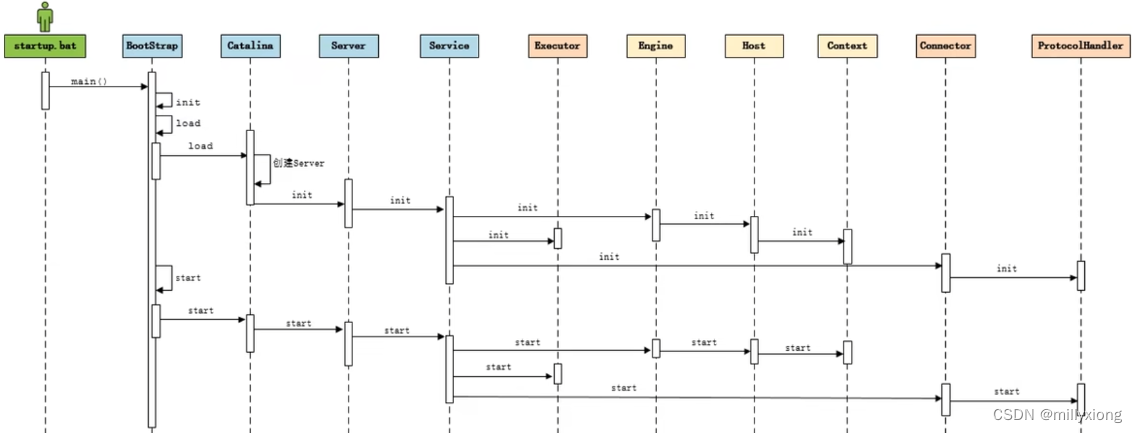
1)启动tomcat,需要调用bin/startup.bat(在linux目录下,需要调用bin/startup.sh),在startup.bat脚本中,调用了catalina.bat。
2)在catalina.bat脚本文件中,调用了BootStrap 中的main方法。
3)在BootStrap的main方法中调用了init方法,来创建catalina及初始化类加载器。
4)在BootStrap的main方法中调用了load方法,在其中又调用了catalina的load方法。
5)在catalina 的load方法中,需要进行一些初始化的工作,并需要构造Digester对象,用于解析xML。
6)然后在调用后续组件的初始化操作。
加载Tomcat的配置文件,初始化容器组件,监听对应的端口号,准备接受客户端请求。
源码解析
由于所有的组件均存在初始化、启动、停止等生命周期方法,拥有生命周期管理的特性,所以Tomcat在设计的时候,基于生命周期管理抽象成了一个接口Lifecycle,而组件Server、Service、Container、Executor、Connector组件,都实现了一个生命周期的接口,从而具有了以下生命周期中的核心方法:
1、init():初始化组件
2、start():启动组件
3、stop():停止组件
4、destroy():销毁组件
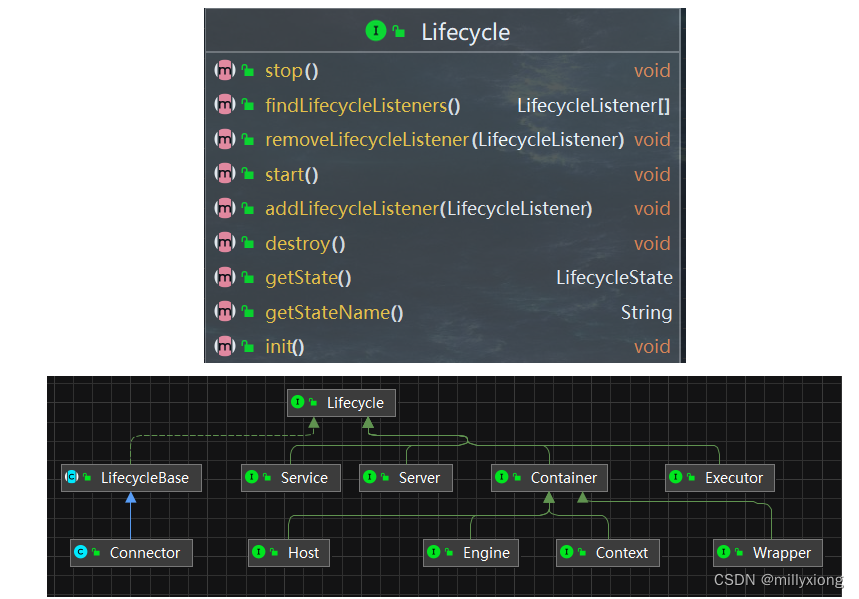

从启动流程图中,我们可以看出Tomcat的启动过程非常标准化,统一按照生命周期管理接口Lifecycle的定义进行启动。首先调用init()方法进行组件的逐级初始化操作,然后再调用start()方法进行启动。每一级的组件除了完成自身的处理外,还要负责调用子组件响应的生命周期管理方法,组件与组件之间是松耦合的,因为我们可以很容易的通过配置文件进行修改和替换。
Tomcat 请求
流程图设计分析:
设计了这么多层次的容器,Tomcat是怎么确定每一个请求应该由哪个Wrapper容器里的servlet来处理的呢?答案是,Tomcat是用Mapper组件来完成这个任务的。Mapper组件的功能就是将用户请求的URL定位到一个servlet,它的工作原理是:Mapper组件里保存了web应用的配置信息,其实就是容器组件与访问路径的映射关系,比如Host容器里配置的域名、Context容器里的web应用路径,以及Wrapper容器里servlet映射的路径,你可以想象这些配置信息就是一个多层次的Map。
当一个请求到来时,Mapper组件通过解析请求URL里的域名和路径,再到自己保存的Map里去查找,就能定位到一个Servlet。请你注意,一个请求URL最后只会定位到一个Wrapper容器,也就是一个servlet。下面的示意图中,就描述了当用户请求链接http://localhost:8080/course/add之后,是如何找到最终处理业务逻辑的servlet。
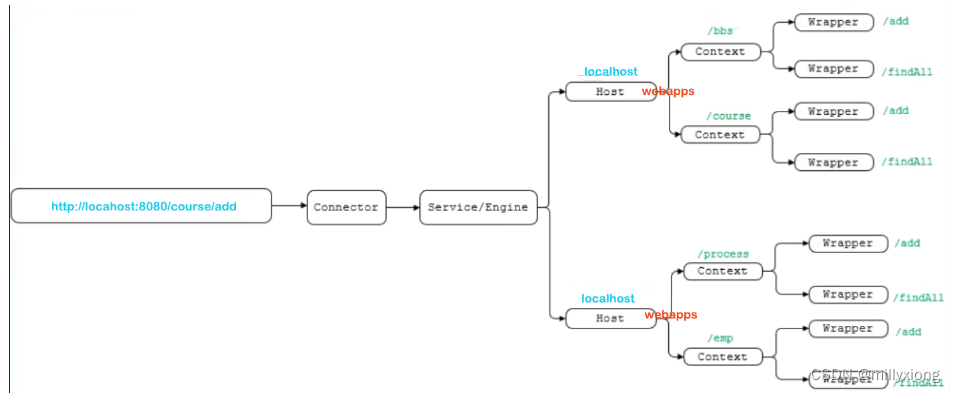
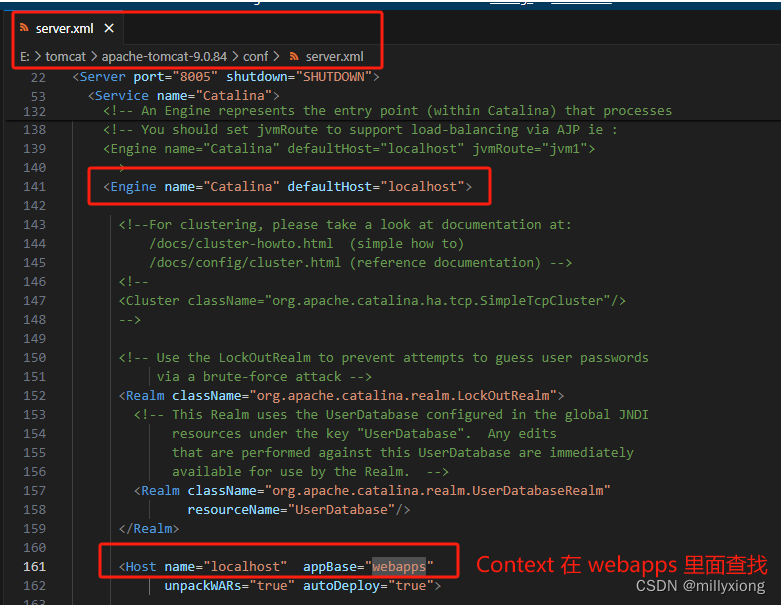
架构分析:
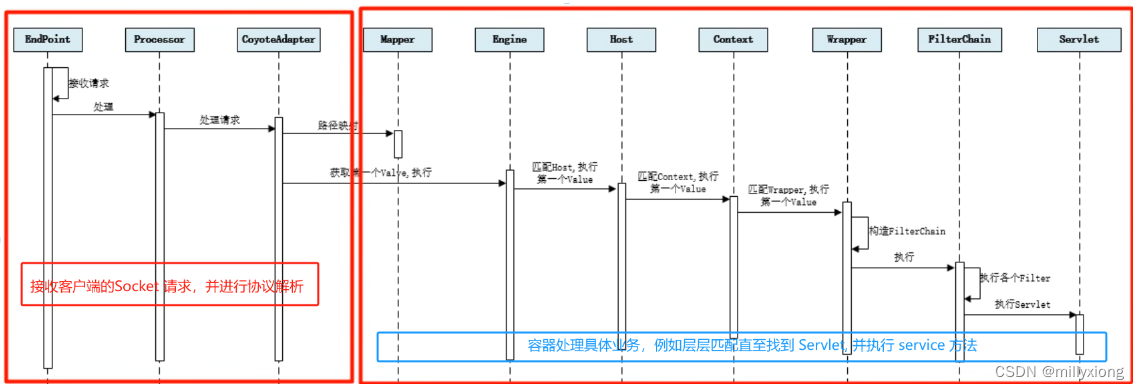
步骤如下:
1)Connector组件Endpoint中的Acceptor监听客户端套接字连接并接收socket。
2)将连接交给线程池Executor处理,开始执行请求响应任务。
3)Processor组件读取消息报文,解析请求行、请求体、请求头,封装成Request对象。
4)Mapper组件根据请求行的URL值和请求头的Host值匹配由哪个Host容器、Context容器、Wrapper容器处理请求。
5)CoyoteAdaptor组件负责将connector组件和Engine容器关联起来,把生成的Request对象和响应对象Response传递到Engine容器
中,调用Pipeline。
6)Engine容器的管道开始处理,管道中包含若干个valve、每个valve负责部分处理逻辑。执行完valve后会执行基础的Valve–StandardEngineValve,负责调Host 容器的pipeline。
7)Host容器的管道开始处理,流程类似,最后执行Context容器的pipeline。
8)Context容器的管道开始处理,流程类似,最后执行Wrapper容器的pipeline。
源码追踪
自定义的外部Servlet 项目,找到 servlet-01 项目 -》 out 目录 -》
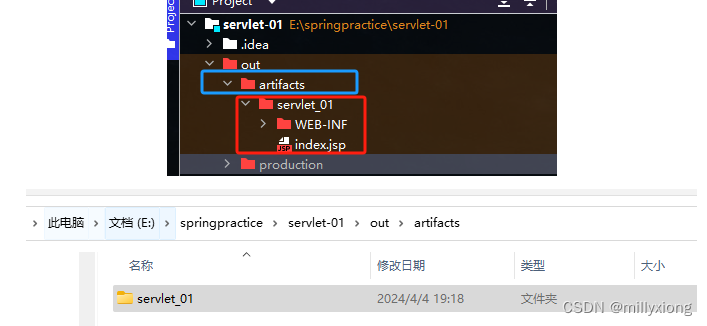
将上面的目录下的所有文件复制到 Tomcat 源码目录下的webapps 下。
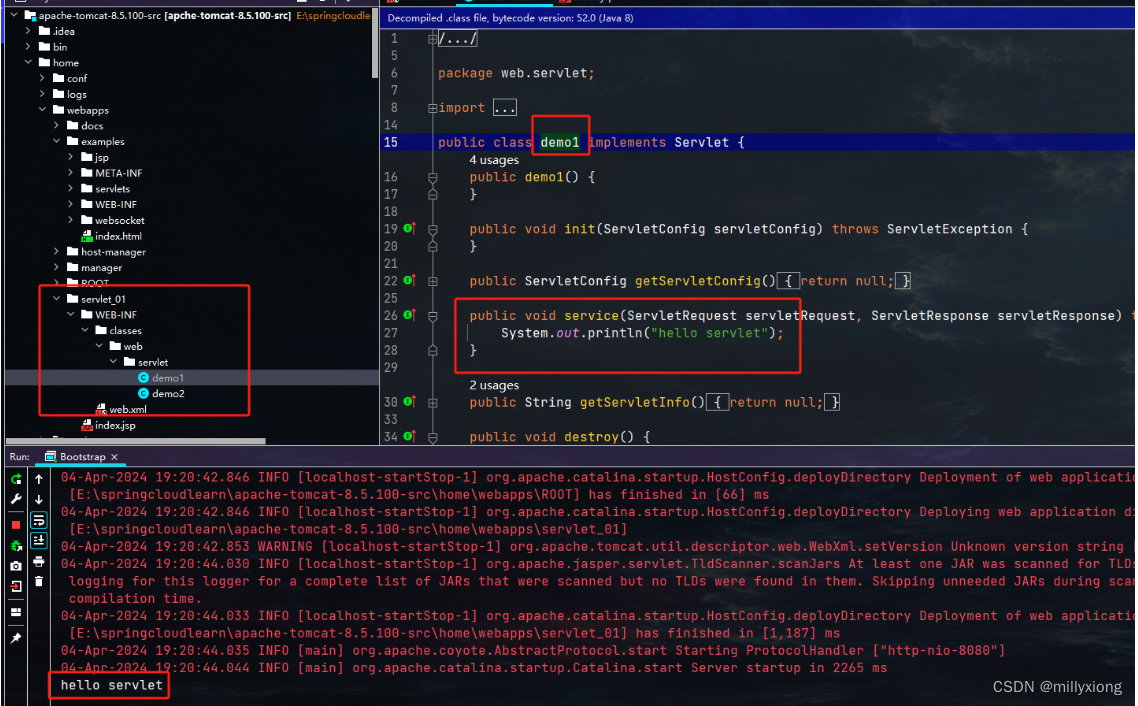
访问地址 : http://localhost:8080/servlet_01/demo1
结果:
源码解析图解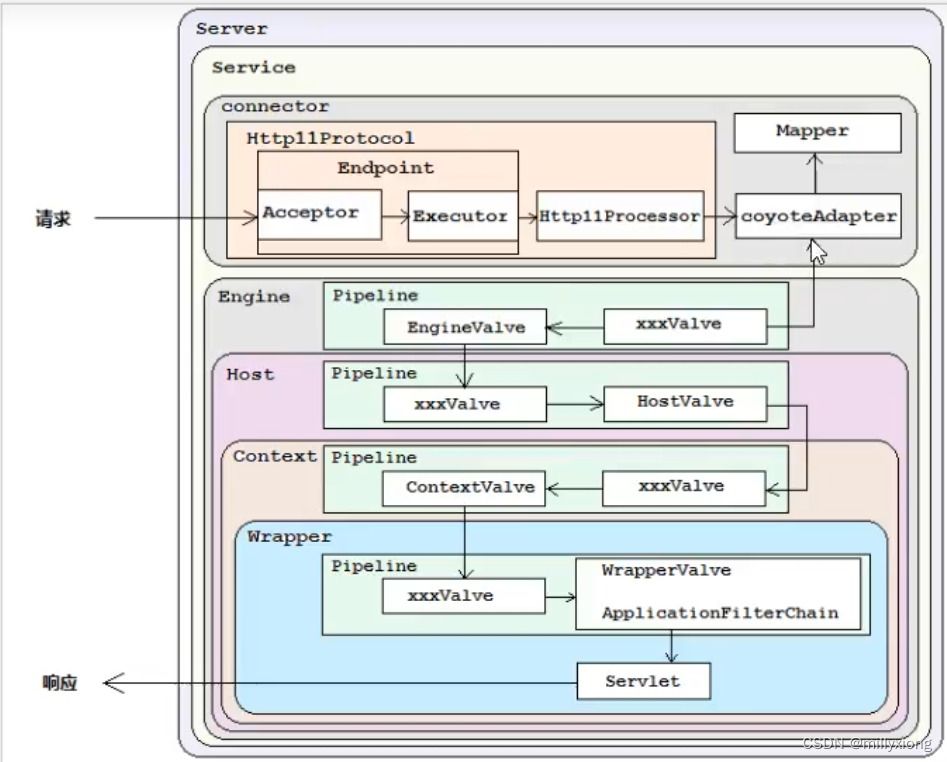
在Tomcat的整体架构中,我们发现Tomcat中的各个组件各司其职,组件之间松耦合,确保了整体架构的可伸缩性和可拓展性,那么在组件内部,如何增强组件的灵活性和拓展性呢?在Tomcat中,每个container组件采用责任链模式来完成具体的请求处理。在Tomcat中定义了Pipeline和Valve两个接口,Pipeline用于构建责任链,后者代表责任链上的每个处理器。Pipeline中维护了一个基础的valve,它始终位于Pipeline的末端(最后执行),封装了具体的请求处理和输出响应的过程。当然,我们也可以调用addValve()方法,为Pipeline添加其他的valve,后添加的valve位于基础的valve之前,并按照添加顺序执行。Pipiline通过获得首个valve来,启动整合链条的执行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









