







bluestore写操作分为大写和小写,写操作经过层层处理后最终被传递到BlueStore::queue_transactions函数中,如下:
ReplicatedBackend::submit_transaction
parent->queue_transactions(tls, op.op); //调用PrimaryLogPG::queue_transactions
osd->store->queue_transactions(ch, tls, op, NULL); //调用BlueStore::queue_transactions
queue_transaction中经过层层调用,最终会调用_do_write_data来分别处理大写和小写,如下:
_txc_add_transaction(txc, &(*p));
_write(txc, c, o, off, len, bl, fadvise_flags);
_do_write(txc, c, o, offset, length, bl, fadvise_flags);
_do_write_data(txc, c, o, offset, length, bl, &wctx);
其中offset和length分别是要写的数据再对象内的逻辑偏移和长度。
_do_write_data实现如下
if (offset / min_alloc_size == (end - 1) / min_alloc_size && (length != min_alloc_size))
_do_write_small(txc, c, o, offset, length, p, wctx);
else
head_offset = offset; //offset为对象内偏移
head_length = p2nphase(offset, min_alloc_size); //头部的字节,即头部多出多少字节
tail_offset = p2align(end, min_alloc_size);
tail_length = p2phase(end, min_alloc_size)
middle_offset = head_offset + head_length;
middle_length = length - head_length - tail_length;
if (head_length)
_do_write_small(txc, c, o, head_offset, head_length, p, wctx);
if (middle_length)
_do_write_big(txc, c, o, middle_offset, middle_length, p, wctx);
if (tail_length)
_do_write_small(txc, c, o, tail_offset, tail_length, p, wctx);
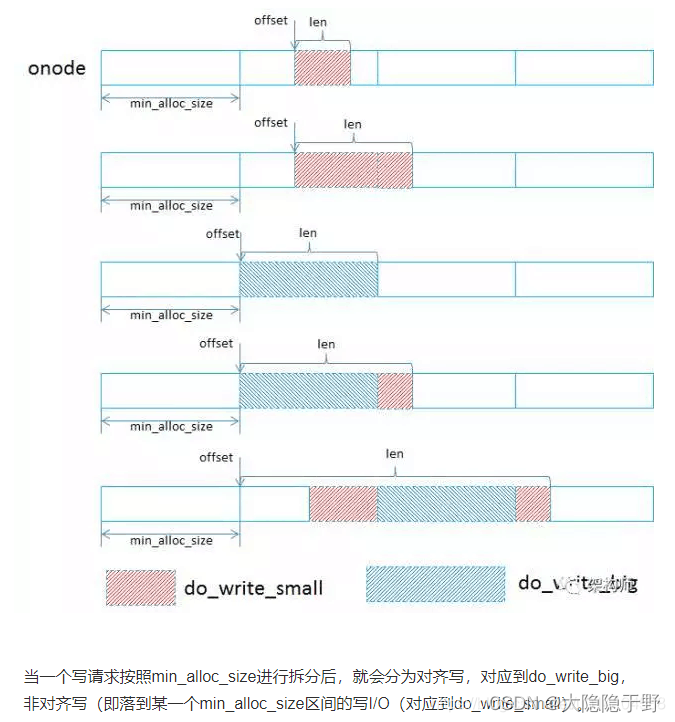
在_do_write_data中,会判断要写的数据是否处于一个min_alloc_size(一般为block size大小的整数倍)大小中,如果是,则就是小写,调用_do_write_small去处理。如果要写的数据跨越一个min_alloc_size,则会把数据按照min_alloc_size划分为大写和小写,如下图所示
使用以下方法调优 BlueStore 以实现小写操作 bluestore_min_alloc_size
在 BlueStore 中,原始分区以 bluestore_min_alloc_size 的块的形式进行配置和管理。默认情况下,bluestore_min_alloc_size 用于 HDD,16 KB 代表 SSD。当每个块中的未写入区域写入原始分区时,它会被填充为零。如果工作负载没有正确定义未使用空间(例如编写小对象时),这会导致浪费空间。最佳实践是将 bluestore_min_alloc_size 设置为与最小写入操作相匹配,从而避免产生放大的罚款。
例如,如果您的客户端频繁写入 4 KB 对象,请使用 ceph-ansible 在 OSD 节点上配置以下设置:
bluestore_min_alloc_size = 4096
注意:bluestore_min_alloc_size_ssd 和 bluestore_min_alloc_size_hdd 的设置分别特定于 SSD 和 HDD,但不需要设置它们,因为设置 bluestore_min_alloc_size 会覆盖它们。
_do_write_small会处理各种场景的小写,如下:
uint64_t end_offs = offset + length;//在对象内结束的逻辑地址
auto ep = o->extent_map.seek_lextent(offset);//返回offset处于的lextent,如果均小于则返回extent_map的end迭代,均大于则返回begin迭代
auto max_bsize = std::max(wctx->target_blob_size, min_alloc_size);
uint32_t alloc_len = min_alloc_size;
auto offset0 = p2align(offset, alloc_len); //返回往前最近按照alloc_len对齐的地址
BlobRef b = ep->blob;
auto bstart = ep->blob_start();//return logical_offset - blob_offset; 即返回这个blob开始处所代表的对象内逻辑偏移
uint64_t chunk_size = b->get_blob().get_chunk_size(block_size); //block_size
head_pad = p2phase(offset, chunk_size); //头部需要填充多少字节
tail_pad = p2nphase(end_offs, chunk_size); //尾部需要填充多少字节
if (head_pad && o->extent_map.has_any_lextents(offset - head_pad, chunk_size))
//检查是否有lextent和[offset-head_pad, offset-head_pad+chunk_size]区间重叠,如果有则不能用0补齐
head_pad = 0;
if (tail_pad && o->extent_map.has_any_lextents(end_offs, tail_pad))
检查是否有lextent和[end_offs, end_offs+tail_pad]区间重叠,如果有则不能用0补齐
tail_pad = 0;
uint64_t b_off = offset - head_pad - bstart; //offset-head_pad在blob中的偏移
uint64_t b_len = length + head_pad + tail_pad;
if ((b_off % chunk_size == 0 && b_len % chunk_size == 0)&&
b->get_blob().get_ondisk_length() >= b_off + b_len && //已分配的pextent包含[b_off, b_off+b_len]
b->get_blob().is_unused(b_off, b_len) && //blob中[b_off, b_off+b_len]区间未使用
b->get_blob().is_allocated(b_off, b_len)) { //blob中[b_off, b_off+b_len]对应的pextent已分配
_apply_padding(head_pad, tail_pad, bl); //头部和尾部扩充0
//map函数就是找到blob对应的pextent,然后调用传递给map的lambda表达式
if (b_len <= prefer_deferred_size)
bluestore_deferred_op_t *op = _get_deferred_op(txc, o);
op->op = bluestore_deferred_op_t::OP_WRITE;
b->get_blob().map(b_off, b_len, [&](uint64_t offset, uint64_t length) {op->extents.emplace_back(bluestore_pextent_t(offset, length));return 0;});
op->data = bl;
else
//找到blob对应的pextent,并把b_off起始的bl数据写到pextent中
b->get_blob().map_bl(b_off, bl, [&](uint64_t offset, bufferlist& t) {bdev->aio_write(offset, t, &txc->ioc, wctx->buffered); });
Extent *le = o->extent_map.set_lextent(c, offset, b_off + head_pad, length, b, &wctx->old_extents); //b_off+head_pad代表了原始数据开始位置在blob中的偏移
//如果有lextent包含[logical_offset, logical_offset+length],则需要将[logical_offset, logical_offset+length]从原来的那个lextent中剔除
//原来的lextent分成一个或者两个lextent
punch_hole(c, logical_offset, length, old_extents);
首先检测能否前后补齐,其是利用has_any_lextents来实现的,has_any_lextents去检测是否有lextent和已知区间重叠,如果有则说明要补齐的区间(或部分)已经存在于lextent了,这时候需要从磁盘中读出这部分数据,而不是用0补齐。但是检测头部补齐区间时是用的o->extent_map.has_any_lextents(offset - head_pad, chunk_size)而不是
o->extent_map.has_any_lextents(offset - head_pad, head_pad)这一点让我很疑惑。
然后如果满足
(1)数据在blob中的偏移b_off和长度b_len都已经按照chunk_size对齐
(2)blob中已经分配的pextent长度大于b_off+b_len
(3)blob中[b_off, b_off+b_len]区间未使用
(4)blob中[b_off, b_off+b_len]对应的pextent已分配
就可以利用blob未使用的区间来存放这部分数据。注意这里的b_off和b_len是已经pad后的偏移和长度
如果在blob中的数据长度b_len小于prefer_deferred_size,就会执行延迟写,否则就会执行异步写。
最后调用set_lextent的作用有两个
(1)如果有lextent包含[logical_offset, logical_offset+length],则需要将[logical_offset, logical_offset+length]从原来的那个lextent中剔除(称作old_extent),原来的lextent分成一个或者两个lextent
(2)新创建一个lextent并插入到extent_map中
对于上面的这种小写场景,并不会发生(1)的情况。而且如果extent_map中有很多小的lextent,会执行相邻lextent合并 ,这里处理的情况如下图所示:

继续往下看_do_write_small
uint64_t head_read = p2phase(b_off, chunk_size);
uint64_t tail_read = p2nphase(b_off + b_len, chunk_size);
if (b->get_blob().get_ondisk_length() >= b_off + b_len && b_off % chunk_size == 0 && b_len % chunk_size == 0 && b->get_blob().is_allocated(b_off, b_len)) //对应的pextent已经分配
_apply_padding(head_pad, tail_pad, bl); //数据两端填充0
if (head_read)
_do_read(c.get(), o, offset - head_pad - head_read, head_read, head_bl, 0);
head_bl.claim_append(bl);
bl.swap(head_bl);
if (tail_read)
_do_read(c.get(), o, offset + length + tail_pad, tail_read, tail_bl, 0);
bl.claim_append(tail_bl);
bluestore_deferred_op_t *op = _get_deferred_op(txc, o);
op->op = bluestore_deferred_op_t::OP_WRITE;
_buffer_cache_write(txc, b, b_off, bl, wctx->buffered ? 0 : Buffer::FLAG_NOCACHE);
b->get_blob().map(b_off, b_len, [&](uint64_t offset, uint64_t length) {op->extents.emplace_back(bluestore_pextent_t(offset, length));return 0;});
op->data.claim(bl);
Extent *le = o->extent_map.set_lextent(c, offset, offset - bstart, length, b, &wctx->old_extents);
b->dirty_blob().mark_used(le->blob_offset, le->length);
这里就是处理覆盖写的情况了,因为bluestore是按照block_size整块写的,因此要把数据填充成block_size的整数倍来写入磁盘,前面是利用pad 0来填充,这里是要读取出覆盖的部分,然后利用读取的部分填充,这里要满足以几个条件
(1)blob中已经分配的pextent长度大于b_off+b_len
(2)b_off和b_len都已经按照chunk_size对齐
(3)blob中[b_off, b_off+b_len]对应的pextent已分配
注意这里的b_off和b_len是已经pad和读填充后的偏移和长度。
然后去读取head_read和tail_read部分的数据,并利用延迟写去写合并后的数据,同样最后也会调用set_lextent去punch_hole已存在的lextent和插入新的lextent。注意这里和上面不一样的是,这里新的lextent可能和原来的lextent有重叠,因此存在lextent分片的可能。
这里处理的情况如下图所示

_do_write_small然后再次检查是否可以复用blob,如下
if (b->can_reuse_blob(min_alloc_size, max_bsize, offset0 - bstart, &alloc_len))
if (!wctx->has_conflict(b, offset0, offset0 + alloc_len, min_alloc_size))
o->extent_map.punch_hole(c, offset, length, &wctx->old_extents);
wctx->write(offset, b, alloc_len, b_off0, bl, b_off, length, false, false);
if (prev_ep != end && prev_ep->logical_offset >= min_off)
if (b->can_reuse_blob(min_alloc_size, max_bsize, offset0 - bstart, &alloc_len))
if (!wctx->has_conflict(b, offset0, offset0 + alloc_len, min_alloc_size))
uint64_t chunk_size = b->get_blob().get_chunk_size(block_size);
_pad_zeros(&bl, &b_off0, chunk_size);
o->extent_map.punch_hole(c, offset, length, &wctx->old_extents);
wctx->write(offset, b, alloc_len, b_off0, bl, b_off, length, false, false);
最后,如果上述场景都不满足,则要写的数据处于一个新的blob中,_do_write_small最后一部分就是处理新的blob的
BlobRef b = c->new_blob();
uint64_t b_off = p2phase(offset, alloc_len); //往前补多少字节的0
uint64_t b_off0 = b_off;
//b_off代表对齐alloc_len大小需要扩充的字节数,pad_zeros只按照block_size扩展了,
//因此b_off0要减去不按照block_size对齐的大小
_pad_zeros(&bl, &b_off0, block_size);
o->extent_map.punch_hole(c, offset, length, &wctx->old_extents);
wctx->write(offset, b, alloc_len, b_off0, bl, b_off, length, true, true); //入队,在另一个地方被写
大写的处理流程比小写简单很多,因此就不多叙述
_do_write_data函数退出后,就开始执行_do_alloc_write,_do_alloc_write函数负责处理wctx->write函数入队的操作
for (auto& wi : wctx->writes)
alloc->reserve(need);
PExtentVector prealloc;
prealloc.reserve(2 * wctx->writes.size());
prealloc_left = alloc->allocate(need, min_alloc_size, need, 0, &prealloc);
auto prealloc_pos = prealloc.begin();
PExtentVector extents;
int64_t left = final_length; //该wi压缩后的final_length
while (left > 0)
if (prealloc_pos->length <= left)
prealloc_left -= prealloc_pos->length; //prealloc_left刚开始为已申请的空间总大小,这里代表申请的空间中还剩多少
left -= prealloc_pos->length; //代表该wi还剩多少要没有分配
extents.push_back(*prealloc_pos); //将本段的bluestore_pextent_t插入extents中
++prealloc_pos;
else
extents.emplace_back(prealloc_pos->offset, left);
prealloc_pos->offset += left;
prealloc_pos->length -= left;
prealloc_left -= left;
left = 0;
break
dblob.allocated(p2align(b_off, min_alloc_size), final_length, extents);
Extent *le = o->extent_map.set_lextent(coll, wi.logical_offset, b_off + (wi.b_off0 - wi.b_off), wi.length0, wi.b, nullptr);
wi.b->dirty_blob().mark_used(le->blob_offset, le->length);
//map函数就是找到blob对应的pextent,然后调用传递给map的lambda表达式
if (b_len <= prefer_deferred_size)
bluestore_deferred_op_t *op = _get_deferred_op(txc, o);
op->op = bluestore_deferred_op_t::OP_WRITE;
b->get_blob().map(b_off, b_len, [&](uint64_t offset, uint64_t length) {op->extents.emplace_back(bluestore_pextent_t(offset, length));return 0;});
op->data = bl;
else
//找到blob对应的pextent,并把b_off起始的bl数据写到pextent中
b->get_blob().map_bl(b_off, bl, [&](uint64_t offset, bufferlist& t) {bdev->aio_write(offset, t, &txc->ioc, wctx->buffered); });
因为插入到wctx->writes中的操作都是新的blob,因此需要先申请磁盘空间给prealloc,dblob.allocated(p2align(b_off, min_alloc_size), final_length, extents);负责将分配的pextents和对应的blob关联起来,最后根据数据的长度来决定是延迟写还是异步写。
Tag: ceph 12.2.4
[BlueStore.cc]
int BlueStore::queue_transactions(Sequencer *posr, vector<Transaction>& tls, TrackedOpRef op, ThreadPool::TPHandle *handle)
>> TransContext *txc = _txc_create(osr);
创建事务上下文,关联回调函数
>> for (vector<Transaction>): _txc_add_transaction(txc, &(*p));
遍历事务列表,根据操作码处理,事务上下文添加修改操作
>> _txc_write_nodes(txc, txc->t);
更新元数据
>> _txc_finalize_kv(txc, txc->t);
>> _txc_state_proc(txc);
状态机处理
[注]
Sequencer: 序列器,请求保序
vector<Transaction>: 事务列表,一次可提交多个事务
[BlueStore.cc]
void BlueStore::_txc_add_transaction(TransContext *txc, Transaction *t)
>> case Transaction::OP_WRITE: _write(txc, c, o, off, len, bl, fadvise_flags);
[注]
Transaction: OSD层面事务
TransContext: BlueStore层面事务上下文
[BlueStore.cc]
int BlueStore::_write(TransContext *txc, CollectionRef& c, OnodeRef& o, uint64_t offset,
size_t length, bufferlist& bl, uint32_t fadvise_flags)
>> _do_write(txc, c, o, offset, length, bl, fadvise_flags);
写数据
>> txc->write_onode(o);
更新元数据
[BlueStore.cc]
int BlueStore::_do_write(TransContext *txc, CollectionRef& c, OnodeRef o, uint64_t offset,
uint64_t length, bufferlist& bl, uint32_t fadvise_flags)
>> _do_write_data(txc, c, o, offset, length, bl, &wctx);
>> _do_alloc_write(txc, c, o, &wctx);
>> _wctx_finish(txc, c, o, &wctx);
[BlueStore.cc]
void BlueStore::_do_write_data(TransContext *txc, CollectionRef& c, OnodeRef o,
uint64_t offset, uint64_t length, bufferlist& bl, WriteContext *wctx)
>> _do_write_big(txc, c, o, middle_offset, middle_length, p, wctx);
>> _do_write_small(txc, c, o, head_offset, head_length, p, wctx);
[注] 根据offset、length、min_alloc_size区分执行大写、小写处理流程
[BlueStore.cc]
void BlueStore::_do_write_big(TransContext *txc, CollectionRef &c, OnodeRef o,
uint64_t offset, uint64_t length, bufferlist::iterator& blp, WriteContext *wctx)
>> o->extent_map.punch_hole(c, offset, length, &wctx->old_extents);
目标写区域与extent_map lextent所有重叠区域分离到old_extents;原lextent首尾也相应调整
是否存在可复用blob,否则新建blob;
>> wctx->write(offset, b, l, b_off, t, b_off, l, false, new_blob);
写操作存入writes
[BlueStore.h]
void write(uint64_t loffs, BlobRef b, uint64_t blob_len, uint64_t o, bufferlist& bl,
uint64_t o0, uint64_t len0, bool _mark_unused, bool _new_blob)
>> writes.emplace_back(loffs, b, blob_len, o, bl, o0, len0, _mark_unused, _new_blob);
[BlueStore.cc]
void BlueStore::_do_write_small(TransContext *txc, CollectionRef &c, OnodeRef o,
uint64_t offset, uint64_t length, bufferlist::iterator& blp, WriteContext *wctx)
>> 是否需补零处理:_apply_padding
>> IO是否落在blob未使用空间
>> if b_len <= prefer_deferred_size:
bluestore_deferred_op_t *op = _get_deferred_op(txc, o);
op->op = bluestore_deferred_op_t::OP_WRITE;
>> else:
bdev->aio_write(offset, t, &txc->ioc, wctx->buffered);
>> 覆盖写场景
>> if head_read:
_do_read(c.get(), o, offset - head_pad - head_read, head_read, head_bl, 0);
>> if tail_read:
_do_read(c.get(), o, offset + length + tail_pad, tail_read, tail_bl, 0);
>> bluestore_deferred_op_t *op = _get_deferred_op(txc, o);
>> op->op = bluestore_deferred_op_t::OP_WRITE;
>> can_reuse_blob、punch_hole、wctx->write
[BlueStore.cc]
int BlueStore::_do_alloc_write(TransContext *txc, CollectionRef coll, OnodeRef o,
WriteContext *wctx)
>> for (wctx->writes): 计算各个write_item所需磁盘空间
>> alloc->reserve(need); 预留空间
>> alloc->allocate(need, min_alloc_size, need, 0, &prealloc); 预分配空间
>> for (wctx->writes):
>> wi.new_blob: 初始化blob;
>> wi.bl长度小于等于prefer_deferred_size:
bluestore_deferred_op_t *op = _get_deferred_op(txc, o); 放入txc->deferred_txn->ops
op->op = bluestore_deferred_op_t::OP_WRITE;
>> wi.bl长度非小于等于prefer_deferred_size:
bdev->aio_write(offset, t, &txc->ioc, false); 放入pending_aios
[BlueStore.cc][状态机:STATE_PREPARE]
void BlueStore::_txc_state_proc(TransContext *txc)
>> txc->state = TransContext::STATE_AIO_WAIT;
>> _txc_aio_submit(txc);
[BlueStore.cc]
void BlueStore::_txc_aio_submit(TransContext *txc)
>> bdev->aio_submit(&txc->ioc);
[KernelDevice.cc]
void KernelDevice::aio_submit(IOContext *ioc)
>> aio_queue.submit_batch(ioc->running_aios.begin(), e, ioc->num_running.load(), priv,
&retries);
[KernelDevice.h]
struct AioCompletionThread : public Thread {
KernelDevice *bdev;
explicit AioCompletionThread(KernelDevice *b) : bdev(b) {}
void *entry() override {
bdev->_aio_thread();
return NULL;
}
} aio_thread;
[KernelDevice.cc][线程:aio_thread]
void KernelDevice::_aio_thread()
>> aio_queue.get_next_completed(cct->_conf->bdev_aio_poll_ms, aio, max);
>> aio_callback(aio_callback_priv, ioc->priv);
[注] aio_callback: KernelDevice aio_cb
[BlueStore.cc][线程:aio_thread]
static void aio_cb(void *priv, void *priv2)
>> BlueStore::AioContext *c = static_cast<BlueStore::AioContext*>(priv2);
>> c->aio_finish(store);
[BlueStore.h][线程:aio_thread]
void aio_finish(BlueStore *store) override
>> store->txc_aio_finish(this);
[BlueStore.h][线程:aio_thread]
void txc_aio_finish(void *p)
>> _txc_state_proc(static_cast<TransContext*>(p));
[BlueStore.cc][线程:aio_thread] [状态机:STATE_AIO_WAIT]
void BlueStore::_txc_state_proc(TransContext *txc)
>> _txc_finish_io(txc);
[BlueStore.cc][线程:aio_thread]
void BlueStore::_txc_finish_io(TransContext *txc)
>> txc->state = TransContext::STATE_IO_DONE;
>> osr->q.iterator_to(*txc);
>> _txc_state_proc(&*p++);
[BlueStore.cc][线程:aio_thread] [状态机:STATE_IO_DONE]
void BlueStore::_txc_state_proc(TransContext *txc)
>> txc->state = TransContext::STATE_KV_QUEUED;
>> if cct->_conf->bluestore_sync_submit_transaction:
>> txc->state = TransContext::STATE_KV_SUBMITTED;
>> db->submit_transaction(txc->t);
>> _txc_applied_kv(txc);
>> kv_queue.push_back(txc);
>> kv_cond.notify_one(); # notify kv_sync_thread线程
>> kv_queue_unsubmitted.push_back(txc);
[kv_sync_thread] [BlueStore.h]
struct KVSyncThread : public Thread {
BlueStore *store;
explicit KVSyncThread(BlueStore *s) : store(s) {}
void *entry() override {
store->_kv_sync_thread();
return NULL;
}
};
[BlueStore.cc][线程: kv_sync_thread]
void BlueStore::_kv_sync_thread()
[注] 非deferred写数据完成,开始写kv元数据
>> kv_cond.wait(l);
>> kv_committing.swap(kv_queue);
>> for (kv_committing):
>> if txc->state == TransContext::STATE_KV_QUEUED:
>> db->submit_transaction(txc->t);
>> _txc_applied_kv(txc);
>> txc->state = TransContext::STATE_KV_SUBMITTED;
>> db->submit_transaction_sync(synct); 事务同步落盘
>> kv_committing_to_finalize.swap(kv_committing);
>> kv_finalize_cond.notify_one();
[BlueStore.h]
struct KVFinalizeThread : public Thread {
BlueStore *store;
explicit KVFinalizeThread(BlueStore *s) : store(s) {}
void *entry() {
store->_kv_finalize_thread();
return NULL;
}
};
[BlueStore.cc][线程: kv_finalize_thread]
void BlueStore::_kv_finalize_thread()
>> kv_finalize_cond.wait(l);
>> kv_committed.swap(kv_committing_to_finalize);
>> while(!kv_committed.empty()): _txc_state_proc(txc);
[BlueStore.cc][线程: kv_finalize_thread] [状态机: STATE_KV_SUBMITTED]
void BlueStore::_txc_state_proc(TransContext *txc)
>> txc->state = TransContext::STATE_KV_DONE;
>> _txc_committed_kv(txc);
>> 状态机进入下一状态
>> case TransContext::STATE_KV_DONE:
>> if txc->deferred_txn: 存在WAL事务要处理
txc->state = TransContext::STATE_DEFERRED_QUEUED;
_deferred_queue(txc);
>> else:
txc->state = TransContext::STATE_FINISHING;
[BlueStore.cc][线程: kv_finalize_thread]
void BlueStore::_txc_committed_kv(TransContext *txc)
>> if (txc->oncommit): finishers[n]->queue(txc->oncommit);
>> if (txc->onreadable): finishers[n]->queue(txc->onreadable);
[Finisher.h][Finisher]
void queue(Context *c, int r = 0) {
finisher_lock.Lock();
if (finisher_queue.empty()) {
finisher_cond.Signal(); # notify 线程finisher_thread
}
if (r) {
finisher_queue_rval.push_back(pair<Context*, int>(c, r));
finisher_queue.push_back(NULL);
} else
finisher_queue.push_back(c);
finisher_lock.Unlock();
}
[Finisher.h]
struct FinisherThread : public Thread {
Finisher *fin;
explicit FinisherThread(Finisher *f) : fin(f) {}
void* entry() override { return (void*)fin->finisher_thread_entry(); }
} finisher_thread;
[Finisher.cc][线程:finisher_thread]
void *Finisher::finisher_thread_entry()
>> finisher_cond.Wait(finisher_lock);
>> vector<Context*> ls;
>> ls.swap(finisher_queue);
>> for (vector<Context*>::iterator p = ls.begin(); p != ls.end(); ++p):
>> (*p)->complete(0);
执行回调返回OSD层
[BlueStore.cc][线程:kv_finalize_thread]
void BlueStore::_deferred_queue(TransContext *txc)
>> _deferred_submit_unlock(txc->osr.get());
[BlueStore.cc][线程:kv_finalize_thread]
void BlueStore::_deferred_submit_unlock(OpSequencer *osr)
>> bdev->aio_write(start, bl, &b->ioc, false);
[BlueStore.cc][线程:aio_thread]
static void aio_cb(void *priv, void *priv2)
>> BlueStore::AioContext *c = static_cast<BlueStore::AioContext*>(priv2);
>> c->aio_finish(store);
[BlueStore.cc][线程:aio_thread]
void aio_finish(BlueStore *store) override
>> store->_deferred_aio_finish(osr);
[BlueStore.cc][线程:aio_thread]
void BlueStore::_deferred_aio_finish(OpSequencer *osr)
>> DeferredBatch *b = osr->deferred_running;
>> for (auto& i : b->txcs): txc->state = TransContext::STATE_DEFERRED_CLEANUP;
>> deferred_done_queue.emplace_back(b);
>> kv_cond.notify_one(); # notify线程kv_sync_thread
[BlueStore.cc][线程:kv_sync_thread]
void BlueStore::_kv_sync_thread()
>> 同上文,通过notify线程kv_finalize_thread,进而调用_txc_state_proc
[BlueStore.cc][线程:kv_finalize_thread] [状态机: STATE_DEFERRED_CLEANUP]
void BlueStore::_txc_state_proc(TransContext *txc)
>> txc->state = TransContext::STATE_FINISHING;
>> 状态机进入下一状态: _txc_finish(txc);
[BlueStore.cc][线程:kv_finalize_thread]
void BlueStore::_txc_finish(TransContext *txc)
>> txc->state = TransContext::STATE_DONE;
>> while (!osr->q.empty()): releasing_txc.push_back(*txc);
>> while (!releasing_txc.empty()):
>> _txc_release_alloc(txc);
>> delete txc;













 4498
4498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









