






问题描述
问题描述如下
sysbench 压200个服务节点(每个4c16G,总共800core), 发现qps不能线性增加(200节点比100节点好1.2倍而已)。
如果压单个服务节点节点QPS 2.4万,CPU跑到390%(每个服务节点独占4个核),如果压200个服务节点(分布在16台64核的海光物理机上)平均每个服务节点节点QPS才1.2万。但是每个服务节点的CPU也跑到了390%左右。 现在的疑问就是为什么CPU跑上去了QPS打了个5折。
机器集群为16*64core 为1024core,也就是每个服务节点独占4core还有冗余
因为服务节点还需要通过LVS调用后端的多个MySQL集群,所以需要排除LVS、网络等链路瓶颈,然后找到根因是什么。
海光物理机CPU相关信息
总共有16台如下的海光服务器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 64 On-line CPU(s) list: 0-63 Thread(s) per core: 2 //每个物理core有两个超线程 Core(s) per socket: 16 //每路16个物理core Socket(s): 2 //2路 NUMA node(s): 4 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 5280 16-core Processor Stepping: 1 CPU MHz: 2455.552 CPU max MHz: 2500.0000 CPU min MHz: 1600.0000 BogoMIPS: 4999.26 Virtualization: AMD-V L1d cache: 32K L1i cache: 64K L2 cache: 512K L3 cache: 8192K NUMA node0 CPU(s): 0-7,32-39 NUMA node1 CPU(s): 8-15,40-47 NUMA node2 CPU(s): 16-23,48-55 NUMA node3 CPU(s): 24-31,56-63 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate sme ssbd sev ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 MySQLeed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca #numactl -H available: 4 nodes (0-3) node 0 cpus: 0 1 2 3 4 5 6 7 32 33 34 35 36 37 38 39 node 0 size: 128854 MB node 0 free: 89350 MB node 1 cpus: 8 9 10 11 12 13 14 15 40 41 42 43 44 45 46 47 node 1 size: 129019 MB node 1 free: 89326 MB node 2 cpus: 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 node 2 size: 128965 MB node 2 free: 86542 MB node 3 cpus: 24 25 26 27 28 29 30 31 56 57 58 59 60 61 62 63 node 3 size: 129020 MB node 3 free: 98227 MB node distances: node 0 1 2 3 0: 10 16 28 22 1: 16 10 22 28 2: 28 22 10 16 3: 22 28 16 10 |
AMD Zen 架构的CPU是胶水核,也就是把两个die拼一块封装成一块CPU,所以一块CPU内跨die之间延迟还是很高的。
验证是否是上下游的瓶颈
需要先分析问题是否在LVS调用后端的多个MySQL集群上。
先写一个简单的测试程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | #cat Test.java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/*
* 目录:/home/admin/jdbc
*
* 编译:
* javac -cp /home/admin/lib/*:. Test.java
*
* 运行:
* java -cp /home/admin/MySQL-server/lib/*:. Test "jdbc:mysql://172.16.160.1:4261/qc_pay_0xwd_0002" "myhhzi0d" "jOXaC1Lbif-k" "select count(*) from pay_order where user_id=1169257092557639682 and order_no='201909292111250000102'" "100"
* */
public class Test {
public static void main(String args[]) throws NumberFormatException, InterruptedException, ClassNotFoundException {
Class.forName("com.mysql.jdbc.Driver");
String url = args[0];
String user = args[1];
String pass = args[2];
String sql = args[3];
String interval = args[4];
try {
Connection conn = DriverManager.getConnection(url, user, pass);
while (true) {
long start = System.currentTimeMillis();
for(int i=0; i<1000; ++i){
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
}
rs.close();
stmt.close();
Thread.sleep(Long.valueOf(interval));
}
long end = System.currentTimeMillis();
System.out.println("rt : " + (end - start));
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
|
然后通过传入不同的jdbc参数跑2组测试:
- 走服务节点执行指定id的点查;
- 直接从服务节点节点连MySQL指定id点查
上述2组测试同时跑在三组场景下:
- A) 服务节点和MySQL都没有压力;
- B) 跑1、2测试的服务节点没有压力,但是sysbench 在压别的服务节点,这样后端的MySQL是有sysbench压侧压力,LVS也有流量压力的;
- C) sysbench压所有服务节点, 包含运行 1、2测试程序节点)
这样2组测试3个场景组合可以得到6组响应时间的测试数据
从最终得到6组数据来看可以排除链路以及MySQL的问题,瓶颈似乎还是在服务节点上
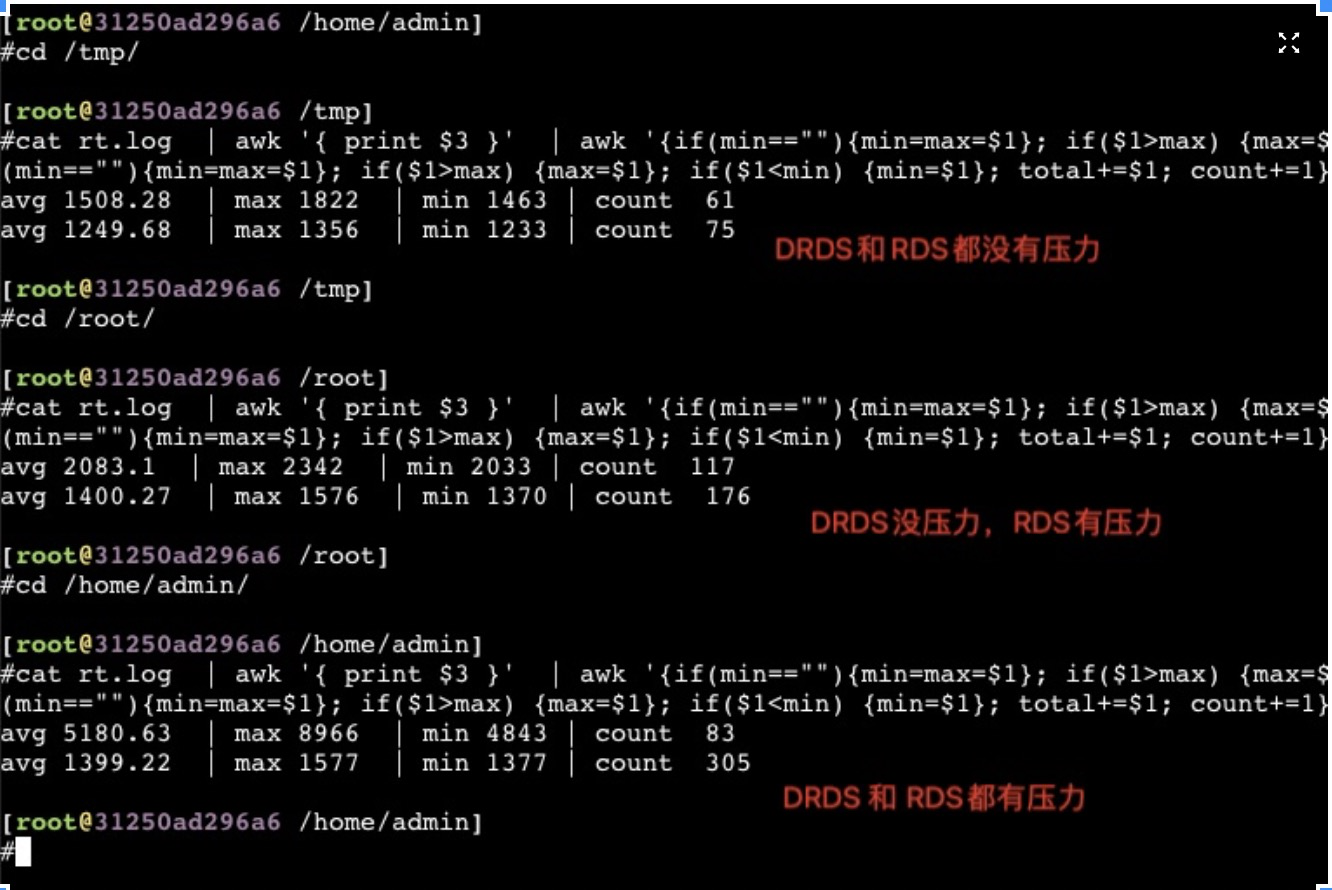
单独压一个服务节点节点并在上面跑测试,服务节点 CPU被压到 390%(每个服务节点 节点固定绑到4核), 这个时候整个宿主机压力不大,但是这四个核比较紧张了
1 2 3 4 5 6 7 | #cat rt.log | awk '{ print $3 }' | awk '{if(min==""){min=max=$1}; if($1>max) {max=$1}; if($1<min) {min=$1}; total+=$1; count+=1} END {print "avg " total/count," | max "max," | min " min, "| count ", count}' ; cat MySQL.log | awk '{ print $3 }' | awk '{if(min==""){min=max=$1}; if($1>max) {max=$1}; if($1<min) {min=$1}; total+=$1; count+=1} END {print "avg " total/count," | max "max," | min " min, "| count ", count }';
avg 2589.13 | max 3385 | min 2502 | count 69
avg 1271.07 | max 1405 | min 1254 | count 141
[root@d42a01107.cloud.a02.am78 /root]
#taskset -pc 48759
pid 48759's current affinity list: 19,52-54
|
通过这6组测试数据可以看到,只有在整个系统都有压力(服务节点所在物理机、LVS、MySQL)的时候rt飙升最明显(C组数据),如果只是LVS、MySQL有压力,服务节点没有压力的时候可以看到数据还是很好的(B组数据)
分析宿主机资源竞争
perf分析
只压单个服务节点
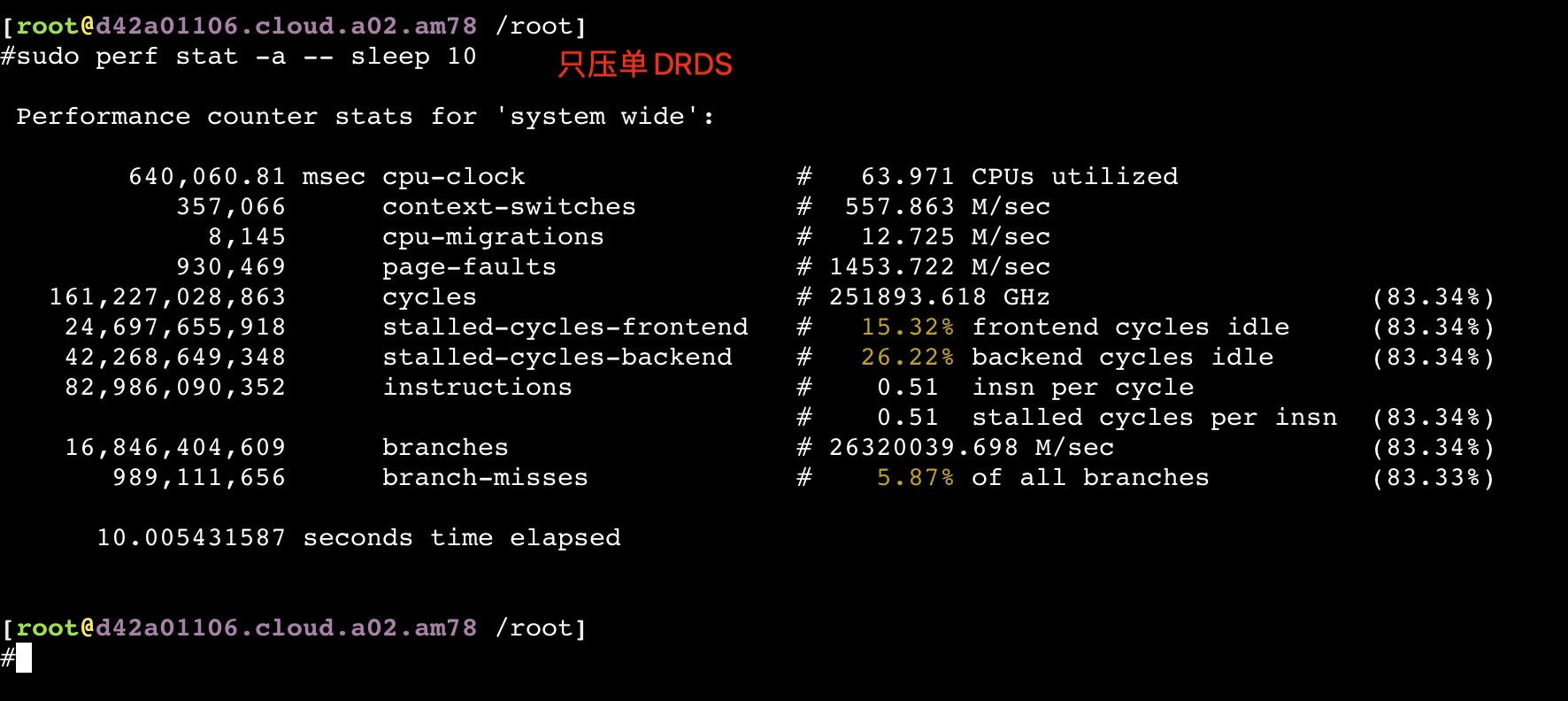
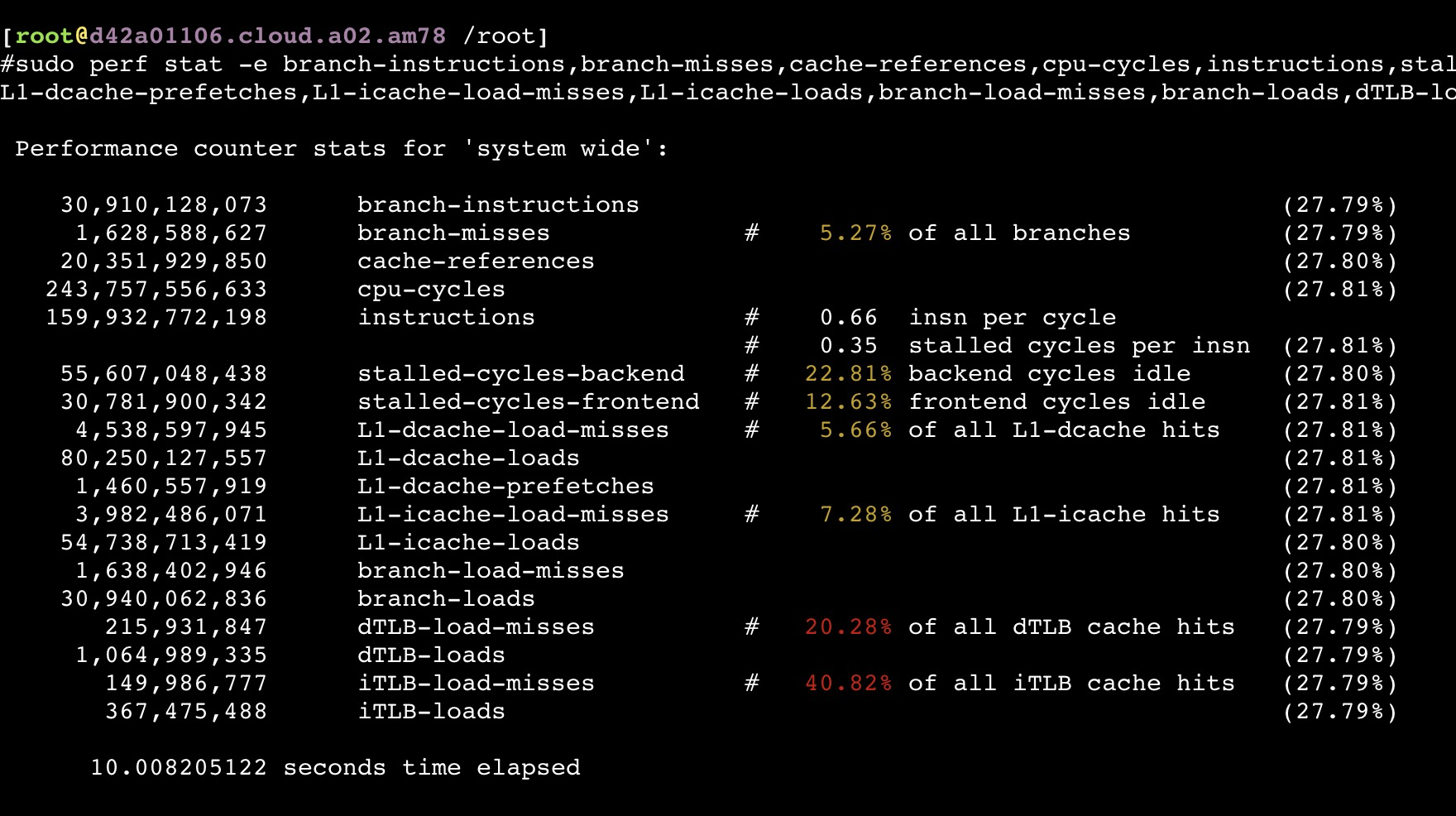
从以上截图,可以看到关键的 insn per cycle 能到0.51和0.66(这个数值越大性能越好)
如果同时压物理机上的所有服务节点
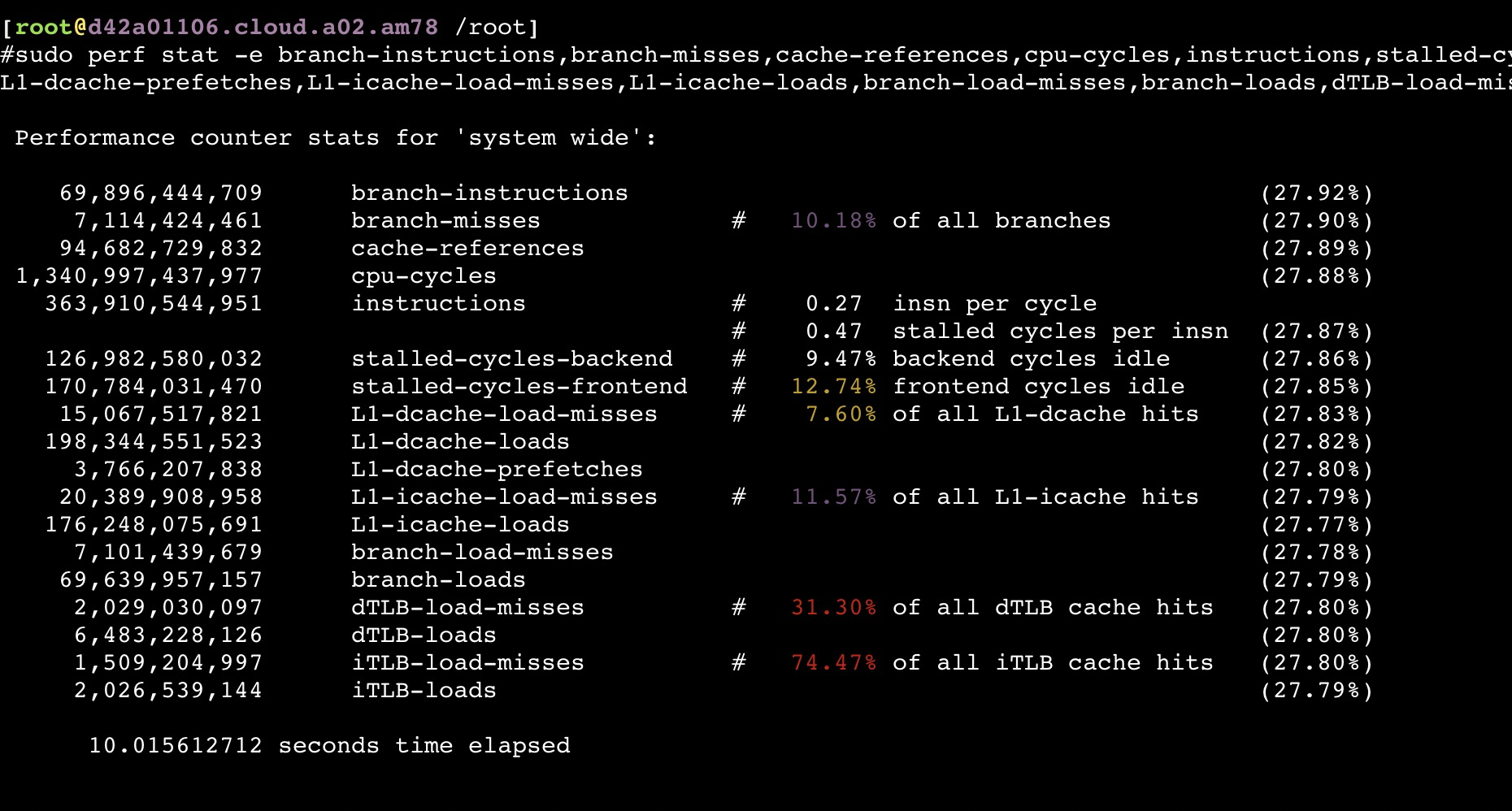
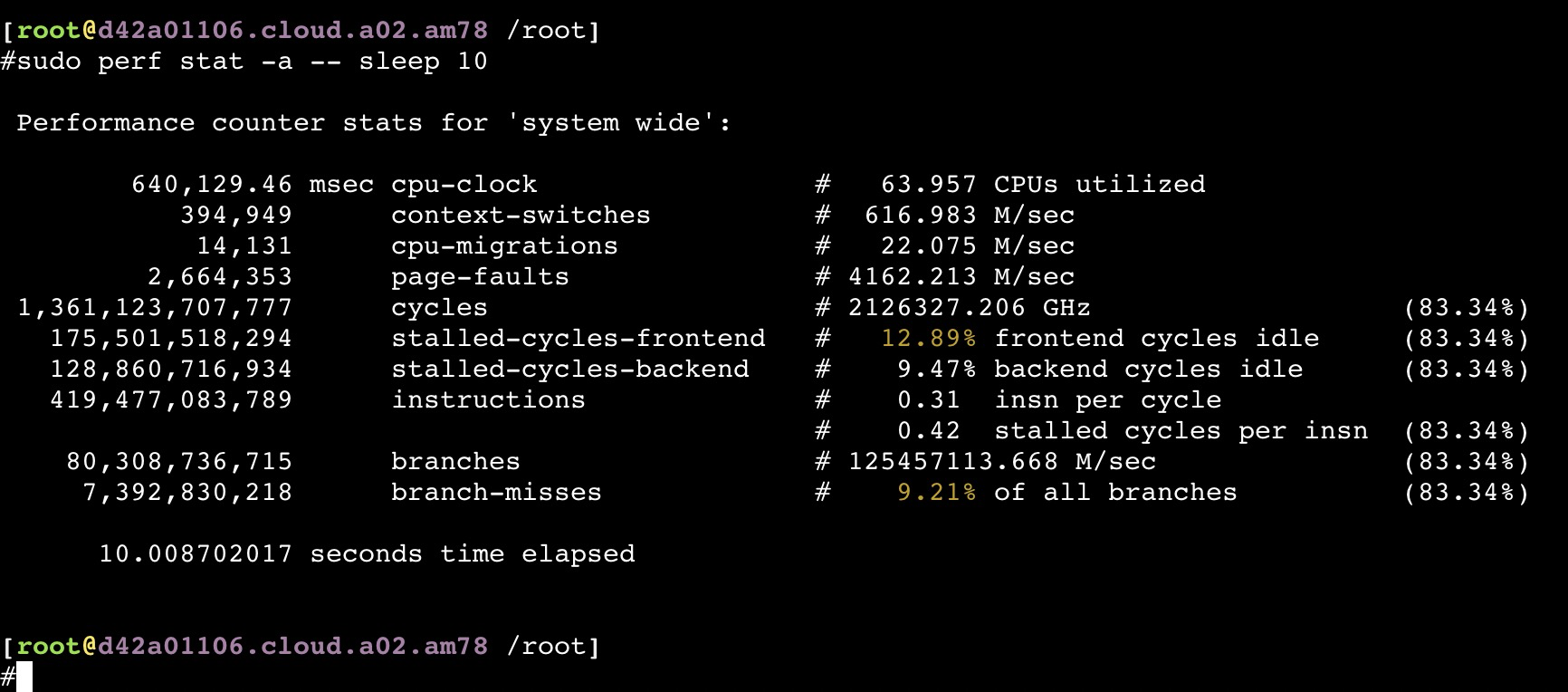
从以上截图,可以看到关键的 insn per cycle 能降到了0.27和0.31(这个数值越大性能越好),基本相当于单压的5折
通过 perf list 找出所有Hardware event,然后对他们进行perf:
1 | sudo perf stat -e branch-instructions,branch-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads -a -- `pidof java` |
尝试不同的绑核后的一些数据
通过以上perf数据以及numa结构,尝试将不同服务进程绑定到指定的4个核上
试了以下三种绑核的办法:
1)docker swarm随机绑(以上测试都是用的这种默认方案);
2)一个服务节点绑连续4个core,这4个core都在同一个node;
3)一个服务节点绑4个core,这个4个core都在在同一个node,同时尽量HT在一起,也就是0,1,32,33 ; 2,3,34,35 这种绑法
结果是绑法2性能略好.
如果是绑法2,压单个服务节点 QPS能到2.3万;绑法1和3,压单个服务节点性能差别不明显,都是2万左右。
尝试将Java进程开启HugePage
从perf数据来看压满后tlab miss比较高,得想办法降低这个值
修改JVM启动参数
JVM启动参数增加如下三个(-XX:LargePageSizeInBytes=2m, 这个一定要,有些资料没提这个,在我的JDK8.0环境必须要):
-XX:+UseLargePages -XX:LargePageSizeInBytes=2m -XX:+UseHugeTLBFS
修改机器系统配置
设置HugePage的大小
cat /proc/sys/vm/nr_hugepages
nr_hugepages设置多大参考如下计算方法:
If you are using the option
-XX:+UseSHMor-XX:+UseHugeTLBFS, then specify the number of large pages. In the following example, 3 GB of a 4 GB system are reserved for large pages (assuming a large page size of 2048kB, then 3 GB = 3 * 1024 MB = 3072 MB = 3072 * 1024 kB = 3145728 kB and 3145728 kB / 2048 kB = 1536):echo 1536 > /proc/sys/vm/nr_hugepages
透明大页是没有办法减少系统tlab,tlab是对应于进程的,系统分给进程的透明大页还是由物理上的4K page组成。
Java进程用上HugePages后iTLB-load-misses从80%下降到了14%左右, dTLB也从30%下降到了20%,但是ipc变化不明显,QPS有不到10%的增加(不能确定是不是抖动所致)
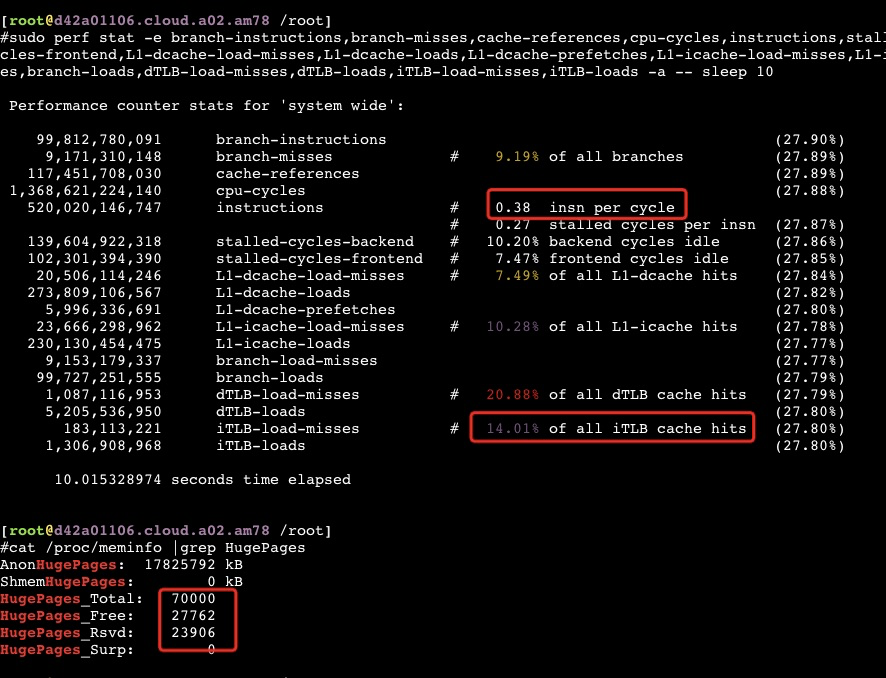
在公有云ecs虚拟机上测试对性能没啥帮助,实际看到用掉的HuagPage不多,如果/proc/sys/vm/nr_hugepages 设置比较大的话JVM会因为内存不足起不来,两者内存似乎是互斥的
用sysbench验证一下海光服务器的多core能力
Intel E5 2682 2.5G VS hygon 7280 2.0G(Zen1)
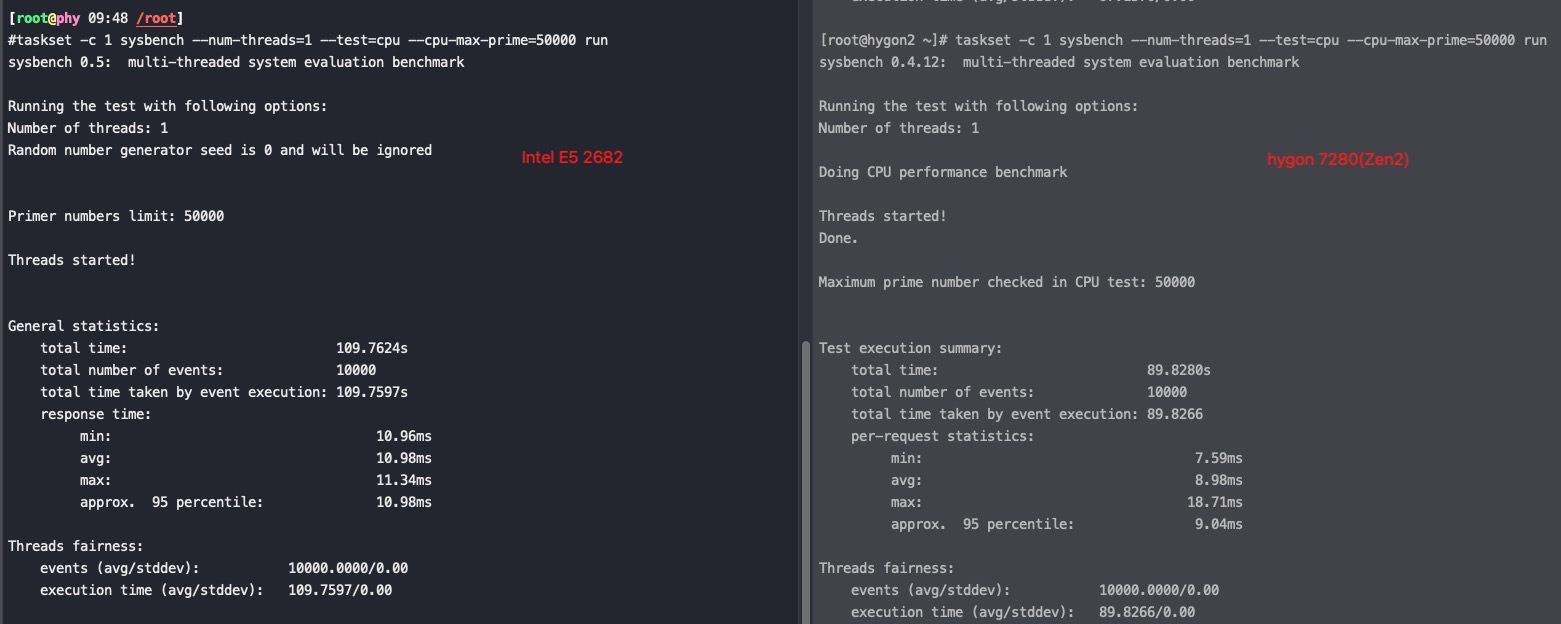
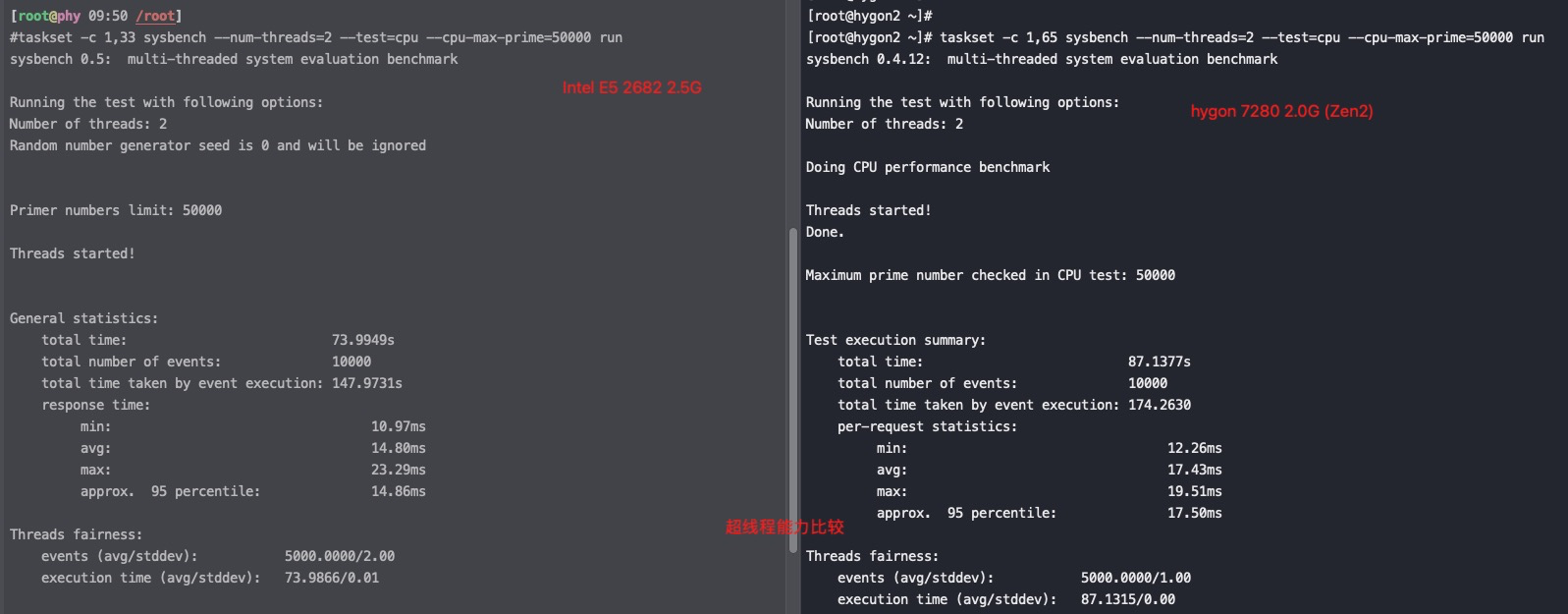
由以上两个测试结果可以看出单核能力hygon 7280 强于 Intel 2682,但是hygon超线程能力还是没有任何提升。Intel用超线程计算能将耗时从109秒降到74秒。但是hygon(Zen1) 只是从89秒降到了87秒,基本没有变化。
再补充一个Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz 对比数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | #taskset -c 1,53 /usr/bin/sysbench --num-threads=2 --test=cpu --cpu-max-prime=50000 run
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 2
Random number generator seed is 0 and will be ignored
Primer numbers limit: 50000
Threads started!
General statistics:
total time: 48.5571s
total number of events: 10000
total time taken by event execution: 97.0944s
response time:
min: 8.29ms
avg: 9.71ms
max: 20.88ms
approx. 95 percentile: 9.71ms
Threads fairness:
events (avg/stddev): 5000.0000/2.00
execution time (avg/stddev): 48.5472/0.01
#taskset -c 1 /usr/bin/sysbench --num-threads=1 --test=cpu --cpu-max-prime=50000 run
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1
Random number generator seed is 0 and will be ignored
Primer numbers limit: 50000
Threads started!
General statistics:
total time: 83.2642s
total number of events: 10000
total time taken by event execution: 83.2625s
response time:
min: 8.27ms
avg: 8.33ms
max: 10.03ms
approx. 95 percentile: 8.36ms
Threads fairness:
events (avg/stddev): 10000.0000/0.00
execution time (avg/stddev): 83.2625/0.00
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Stepping: 7
CPU MHz: 3200.097
CPU max MHz: 3800.0000
CPU min MHz: 1200.0000
BogoMIPS: 4998.89
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-25,52-77
NUMA node1 CPU(s): 26-51,78-103
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch ida arat epb invpcid_single pln pts dtherm spec_ctrl ibpb_support tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt avx512f avx512dq rdseed adx smap clflushopt avx512cdavx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local cat_l3 mba
|
用sysbench 测试Hygon C86 5280 16-core Processor,分别1、8、16、24、32、40、48、56、64 个thread,32个thread前都是完美的线性增加,32core之后基本不增长了,这个应该能说明这个服务器就是32core的能力
sysbench –threads=1 –cpu-max-prime=50000 cpu run
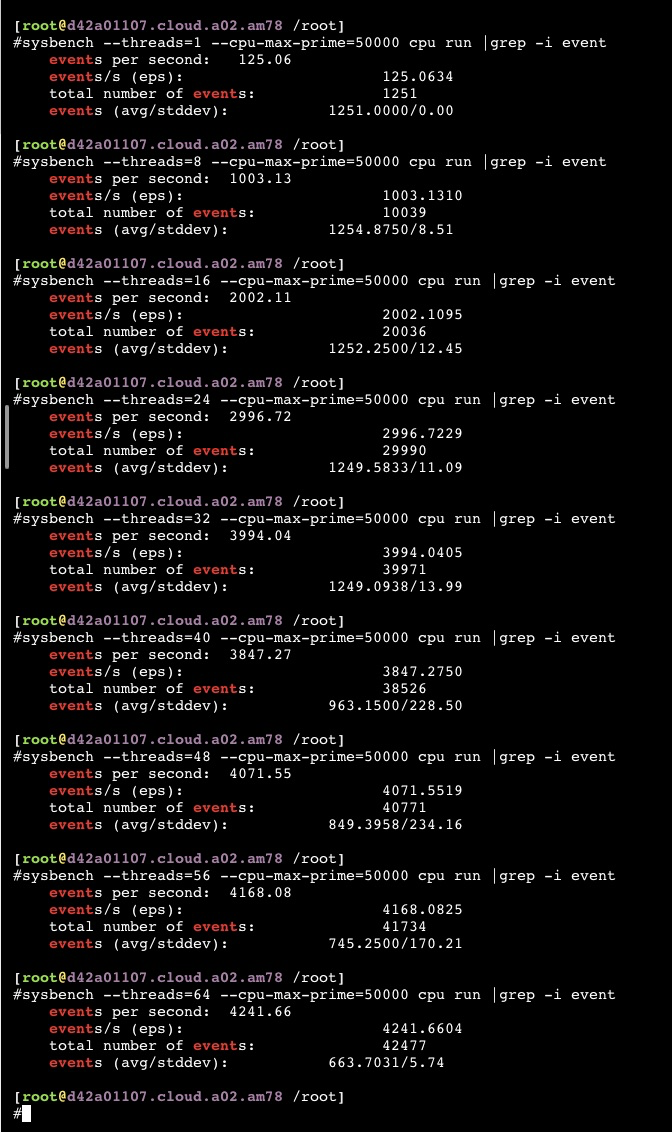
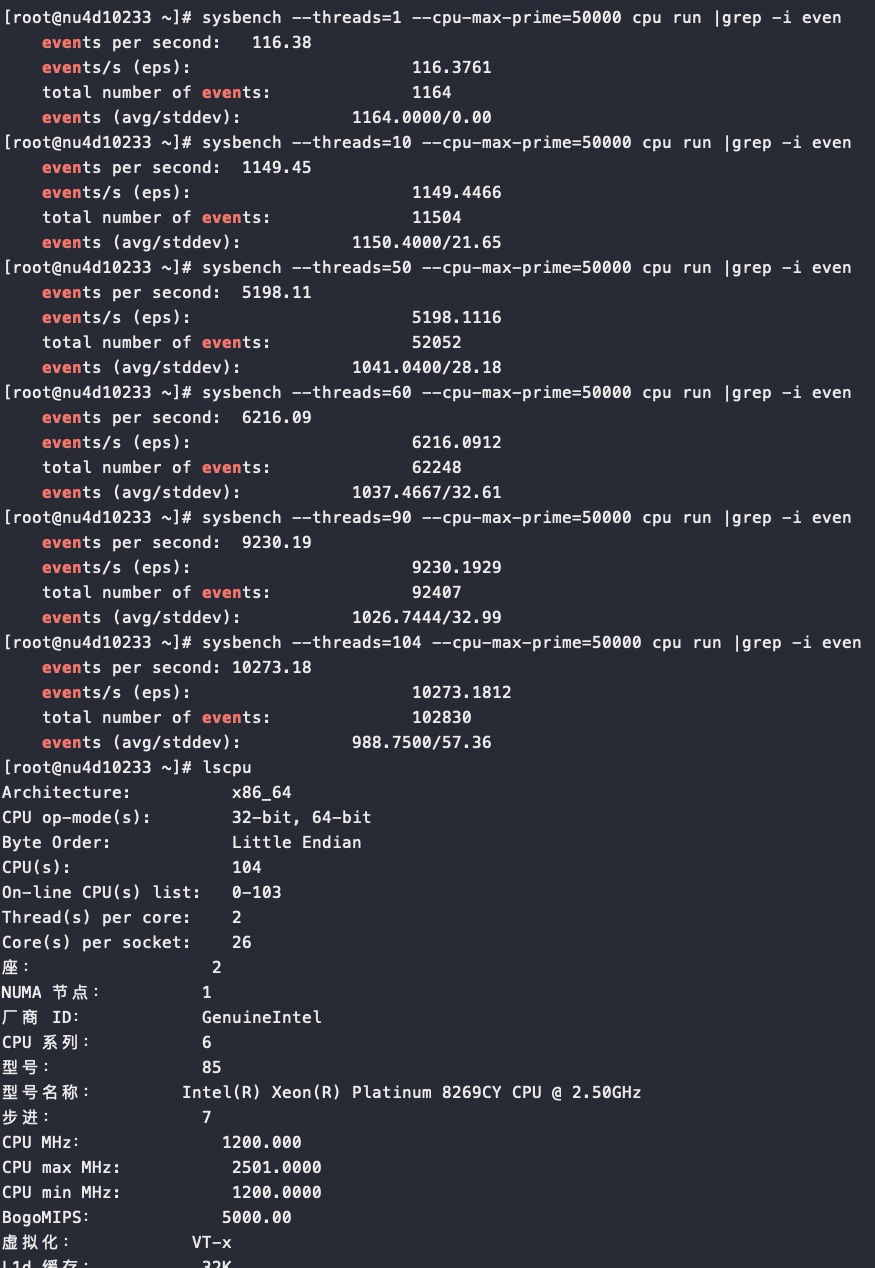
对比下intel的 Xeon 104core,也是物理52core,但是性能呈现完美线性
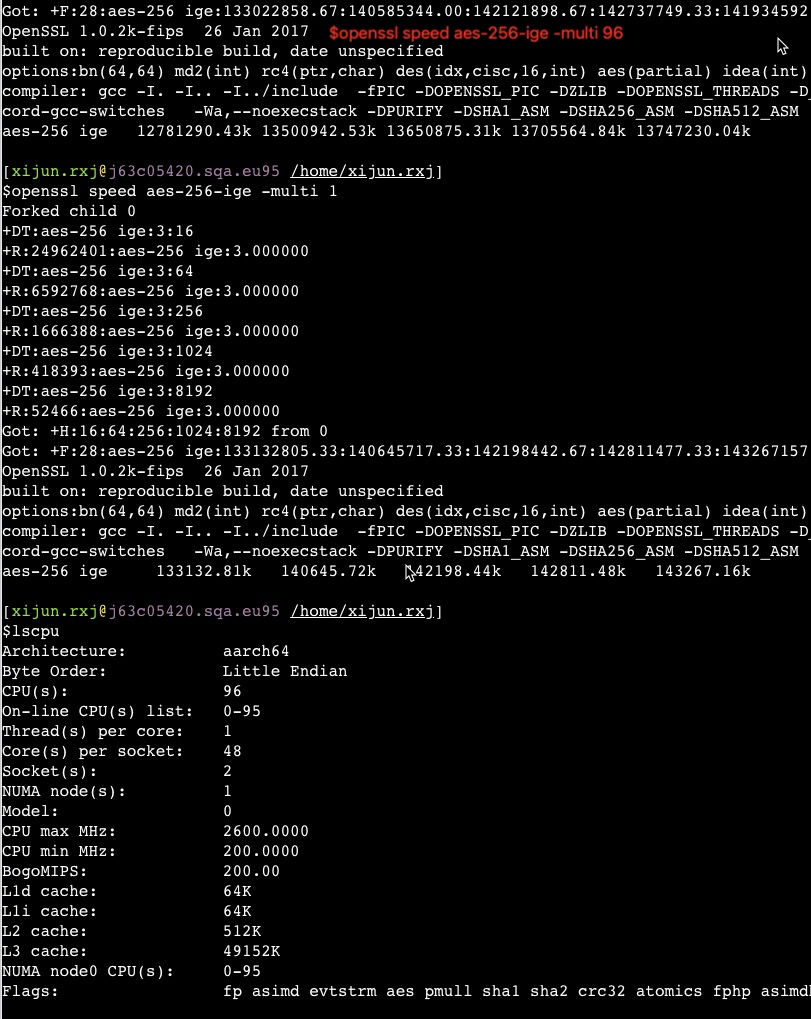
openssl场景多核能力验证
1 | openssl speed aes-256-ige -multi N |
intel 52 VS 26,可以看到52个线程的性能大概是26个的1.8倍

intel 104 VS 52 线程,性能还能提升1.4倍

海光32 VS 16, 性能能提升大概1.8倍,跟intel一致

海光64 VS 32, 性能能提升大概1.2倍

总结下就是,在物理core数以内的线程数intel和海光性能基本增加一致;但如果超过物理core数开始使用HT后海光明显相比Intel差了很多。
intel超线程在openssl场景下性能能提升40%,海光就只能提升20%了。
对比一下鲲鹏920 ARM架构的芯片
1 2 3 4 5 6 7 8 | #numactl -H available: 1 nodes (0) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 node 0 size: 773421 MB node 0 free: 756092 MB node distances: node 0 0: 10 |
96核一起跑openssl基本就是1核的96倍,完美线性,这是因为鲲鹏就没有超线程,都是物理核。如果并发增加到192个,性能和96个基本一样的。
用Sysbench直接压MySQL oltp_read_only的场景
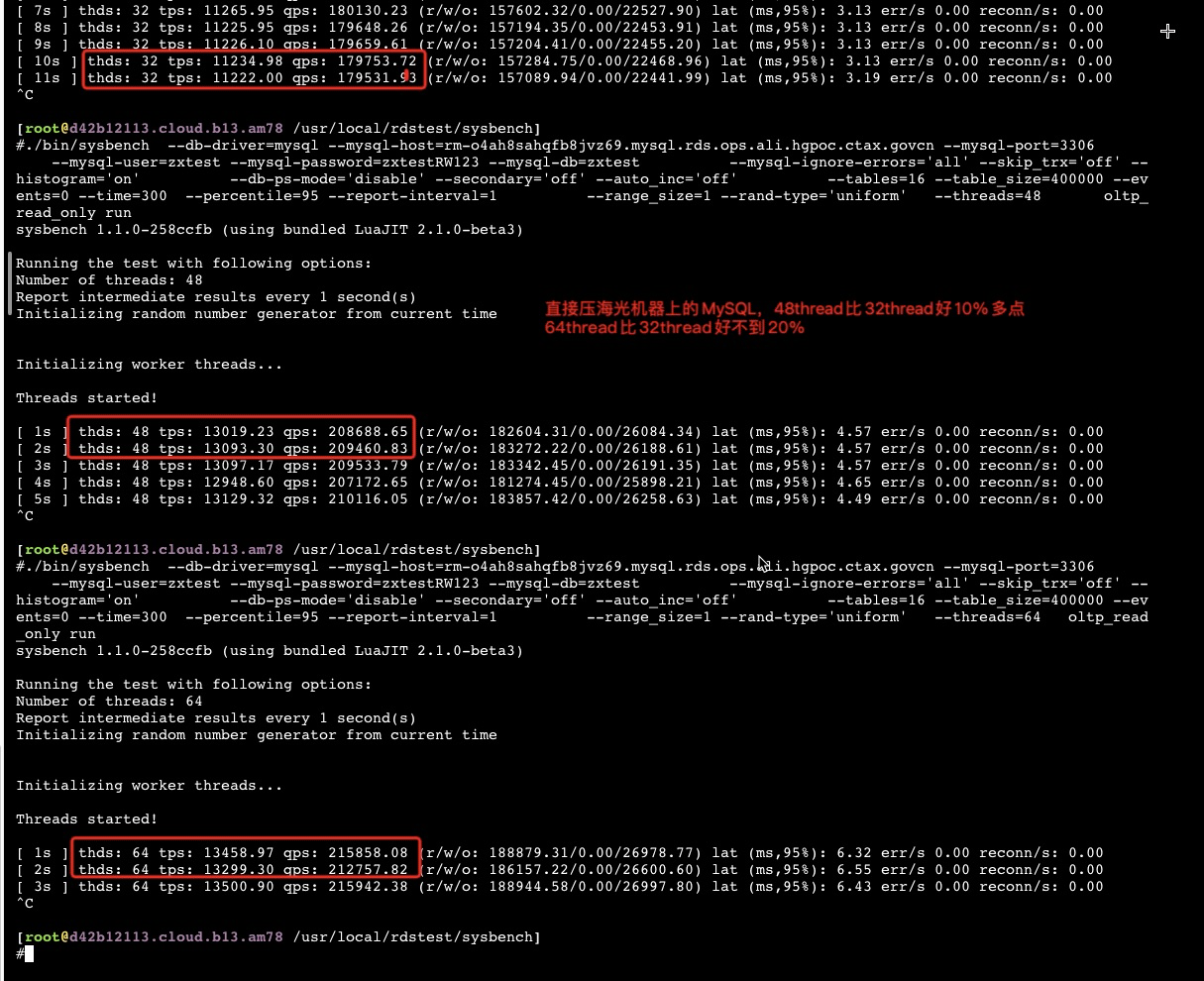
从1到10个thread的时候完美呈现线性,到20个thread就只比10个thread增加50%了,30thread比20增加40%,过了32个thread后增加10个core性能加不到10%了。
在32thread前,随着并发的增加 IPC也有所减少,这也是导致thread翻倍性能不能翻倍的一个主要原因。
基本也和openssl 场景一致,海光的HT基本可以忽略,做的不是很好。超过32个thread后(物理core数)性能增加及其微弱
结论
海光的一个core只有一个fpu,所以超线程算浮点完全没用.
FP处理所有矢量操作。简单的整数向量运算(例如shift,add)都可以在一个周期内完成,是AMD以前架构延迟的一半。基本浮点数学运算具有三个周期的延迟,其中包括乘法(用于双精度需要一个额外周期)。融合乘加是五个周期。
FP具有用于128位加载操作的单个管道。实际上,整个FP端都针对128位操作进行了优化。 Zen支持所有最新指令,例如SSE和AVX1/2。 256位AVX的设计方式是可以将它们作为两个独立的128位操作来执行。 Zen通过将这些指令作为两个操作。也就是说,Zen将256位操作分为两个µOP。同样,存储也是在128位块上完成的,从而使256位加载的有效吞吐量为每两个周期一个存储。这些管道之间的平衡相当好,因此大多数操作将安排至少两个管道,以保持每个周期至少一个这样的指令的吞吐量。暗示着,256位操作将占用两倍的资源来完成操作(即2x寄存器,调度程序和端口)。这是AMD采取的一种折衷方案,有助于节省芯片空间和功耗。相比之下,英特尔的竞争产品Skylake确实具有专用的256位电路。还应注意的是,英特尔的现代服务器级型号进一步扩展了此功能,以纳入支持AVX-512的专用512位电路,而性能最高的型号则具有二个专用的AVX-512单元。
此外,Zen还支持SHA和AES(并实现了2个AES单元),以提高加密性能。这些单位可以在浮点调度程序的管道0和1上找到。
这个也是为什么浮点比Intel X86会弱的原因。
一些其他对比结论
- 对纯CPU 运算场景,并发不超过物理core时,比如Prime运算,比如DRDS(CPU bound,IO在网络,可以加并发弥补)
- 海光的IPC能保持稳定;
- intel的IPC有所下降,但是QPS在IPC下降后还能完美线性
- 在openssl和MySQL oltp_read_only场景下
- 如果并发没超过物理core数时,海光和Intel都能随着并发的翻倍性能能增加80%
- 如果并发超过物理core数后,Intel还能随着并发的翻倍性能增加50%,海光增加就只有20%了
- 简单理解在这两个场景下Intel的HT能发挥半个物理core的作用,海光的HT就只能发挥0.2个物理core的作用了
- 海光5280/7280 是Zen1/Zen2的AMD 架构,每个core只有一个fpu,综上在多个场景下HT基本上都可以忽略


















 2067
2067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









