







个人学习redis的笔记和摘抄,主要来自《Reids设计与实现》一书
Redis-对象
对象
redis定义了一系列基本数据结构,并基于这些数据结构创建了一个对象系统,包括String、List、Set、Hash、Zset。
使用对象的好处
- 针对不同使用场景设置不同的数据结构实现,优化使用效率
- 基于引用计数的内存回收机制,节约内存;多数据库共享一个对象
- 对象带有访问时间信息,空转时间较长的被优先删除
对象的定义
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码方式(数据结构)
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数
int refcount;
// 指向对象的值
void *ptr;
} robj;
- 可以通过TYPE命令查看对象的类型
- 可以通过OBJECT ENCODING查看对象的编码
不同对象的实现
String
字符串对象有int、raw和embstr三种
int:整数值且可以用long类型表示
raw:字符串值且长度>39字节,用SDS表示,通过两次内存分配函数分别创建redisObject和sdshdr结构
embstr:字符串值且长度<=39字节,通过一次内存分配函数分配一块连续的空间。
浮点数也是用raw或者embstr表示的,使用会进行转换
转换
当int使用append操作变成str或者embstr大于39字节或转换成raw编码
List
列表对象有ziplist和linkedlist
- 当所有字符串元素长度小于64字节
- 元素数量小于512个
满足上述用ziplist,其他用linkedlist(可以设定上限值)
Hash
列表对象有ziplist和hashtable
- 当所有键值对键和值长度小于64字节
- 元素数量小于512个
满足上述用ziplist(键和值相邻存储在ziplist),其他用hashtable(可以设定上限值)
Set
列表对象有intset和hashtable
- 当所有元素都是整数
- 元素数量小于512个(可以设定上限值)
满足上述用intset,其他用hashtable,键的值为null
ZSet
列表对象有ziplist和skiplist
- 当所有元素长度小于64字节
- 元素数量小于128个(可以设定上限值)
满足上述用ziplist,其他用skiplist(还包含一个dict保存成员到分值的映射,可以O(1)求分值)
内存回收
对象保存了引用计数,可以通过引用计数在合适的时间进行回收
对象共享
Redis包含且只包含对整数值的字符串对象进行共享,服务器初始化会创建10000个字符串对象,包含0-9999所有整数值
对象空转时长
lru属性记录了对象最后一次被命令程序访问的时间,一些设置maxmemory后可以使空转较长的对象被回收
Redis-数据结构
SDS
SDS(simple dynamic string)作为Redis的默认字符串表示
定义
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};
与C字符串区别
-
常数时间获得字符串长度
-
杜绝了缓冲区溢出(对于字符串拼接操作,会先检查空间是否足够,不够会首先扩展空间)
-
减少修改造成的内存重分配次数
- 空间预分配(扩展时会分配额外空间)
- 惰性空间释放(缩小时不会立即释放空间)
-
二进制安全(利用len判断结束而不是\0)
-
兼容部分C字符串API
链表
一个很典型的双端链表的实现
- 带头尾指针,O(1)访问头尾节点
- 带链表长度计数器
- 顺序访问,增删灵活,缺点就是不能提供随机访问
字典
定义
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
一个字典包含两个hash表,第二个用于扩容rehash时使用
hash表通过开放链地址解决冲突,头插
rehash
和Hashmap类似,扩容或收缩
- 分配新的空间
- 重新计算索引位置
- 释放旧空间,改引用
时机
- 在没有执行BGSAVE或者BGREWRITEAOF命令时,负载因子大于1
- 在执行BGSAVE或者BGREWRITEAOF命令时,负载因子大于5
- 负载因子小于0.1时,收缩
渐进式rehash
1、为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两张哈希表。
2、将字典中的rehashidx设置成0,表示正在rehash。rehashidx的值默认是-1,表示没有在rehash。
3、在rehash进行期间,程序处理正常对字典进行增删改查以外,还会顺带将ht[0]哈希表上,rehashidx索引上,所有的键值对数据rehash到ht[1],并且rehashidx的值加1。
4、当某个时间节点,全部的ht[0]都迁移到ht[1]后,rehashidx的值重新设定为-1,表示rehash完成。
在此期间的删改查将在两个哈希表上进行,增加在新的ht[1]表
跳跃表
为什么使用跳表而不是红黑树?
- 跳表和红黑树性能相仿,但跳表实现简单,易于排错
- 易于实现范围查找,空间局部性能更优
定义
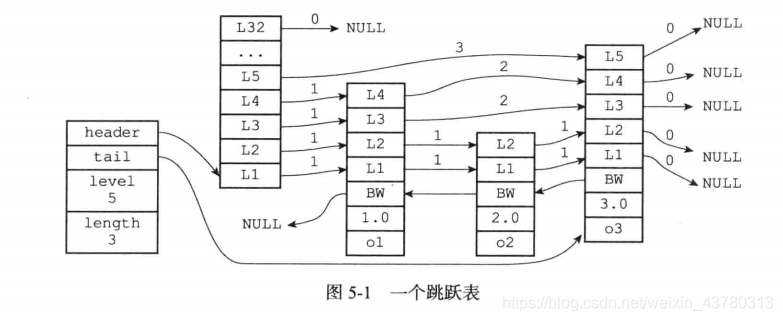
每个点随机一个层高(高度越大出现几率越小)连接前后
整数集合
定义
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
encoding包含16位、32位、64位三种值,数组内元素有序存储
增删操作O(N),查询操作O(logN)
升级
当一个16位编码的整数集合插入一个32位数,就会升级到32位编码
好处:节约内存、提升语言灵活性
压缩列表
定义
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。
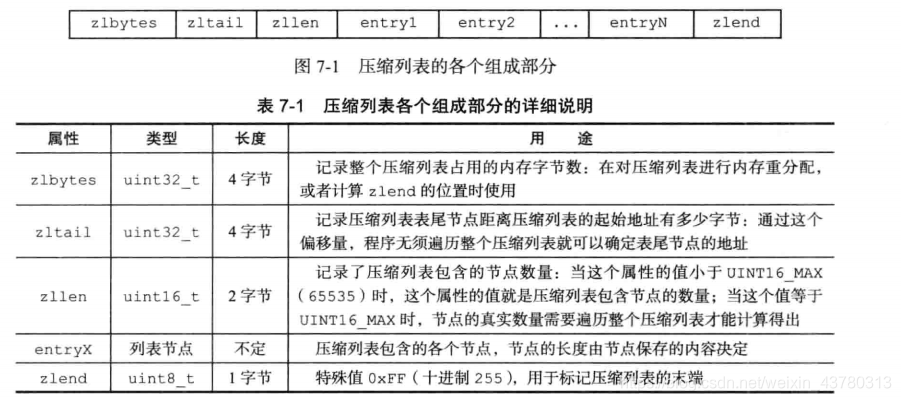
连锁更新
压缩列表每个entry有固定大小值,且记录了上一个entry的长度,可能引发连锁更新















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









