






code:
Abstract
图像处理检测(IMD)至关重要,因为伪造图像和传播错误信息可能是恶意的,并危害我们的日常生活。IMD是解决这些问题的核心技术,主要面临两个方面的挑战:(1)数据的不确定性,即被操纵的工件通常难以被人类识别,导致有噪声的标签,这可能会干扰模型训练;(2)模型不确定性,即同一对象可能由于操纵操作而持有不同的类别(篡改或未篡改),这可能会混淆模型训练,导致结果不可靠。以往的工作主要集中在通过设计细致的特征和网络来解决模型的不确定性问题,而很少考虑数据的不确定性问题。在本文中,我们通过引入不确定性引导学习框架来解决这两个问题,该框架通过一种新的不确定性估计网络(UEN)来测量数据和模型不确定性。UEN在动态监督下进行训练,并输出估计的不确定性映射以改进操作检测结果,显著缓解了学习困难。据我们所知,这是第一次将不确定性建模嵌入到IMD中。在各种数据集上进行的大量实验证明了最先进的性能,验证了我们方法的有效性和可泛化性。
1. Introduction
眼见为实不再可信!随着现代图像编辑工具的发展,如Photoshop, Snapseed等,编辑和分享图像变得更加容易和流行。然而,滥用操纵图像也会造成各种问题,对我们的日常生活产生负面影响。此外,经过处理的图像通常看起来很逼真,这使得人类很难识别它们。因此,开发有效的图像处理检测方法至关重要。
IMD任务的主要挑战有两个方面:数据的不确定性和模型的不确定性。前者是由于被操纵的伪影往往难以识别,这给标注带来了很大的挑战,并导致有噪声的标签。人类可以通过比较原始图像和被处理过的图像毫不费力地区分被处理过的内容,例如比较图1中的(a)和(b),它们之间的不同区域就是被处理过的区域。然而,在真实世界的标注过程中,原始图像通常是不可用的,这使得标注容易出错。如第一行所示,红色边界框表示子节点已被删除,这很容易被注释者忽略,并标记为未篡改。在第二行中,我们在被操纵的图像上用红色绘制掩模边界。模糊操作使边界难以识别,导致边界不准确。这样的数据不确定性问题给模型学习带来了很大的挑战。
对于模型的不确定性,是由于同一视觉内容的标签在不同的图像中可能不一致。如图1的上一行所示,对于传统的语义分割任务,子任务总是在不同的图像上被标记为相同的类别,这在语义上是一致的。而在这个任务中,根据对象是否被修改,同一子对象可以被标记为被篡改和未被篡改,这可能会混淆模型学习并导致不可靠的输出。


对于IMD研究界来说,许多方法的主要重点是设计精细的网络结构和特征,以减轻模型的不确定性。已经提出了多种技术来检测数字图像操作,例如基于重采样[5]、彩色滤波器阵列[29]和SRM[43]的伪影。MVSSNet[11]进一步通过学习被操纵的区域边缘来抑制图像内容。然而,这些方法倾向于隐式地处理模型的不确定性,并且一些操作工件太微小而无法捕获,这可能导致在模型预测过程中过度分割、分割不足和虚幻分割。此外,很少有研究关注数据的不确定性。传统方法[44,9,2]和基于深度学习的方法[41,35]能够生成具有准确标签的操纵数据,并可能在一定程度上缓解数据不确定性问题。然而,生成的数据与真实世界操作数据的分布并不相同。因此,这些方法在实际应用中无法解决数据的不确定性问题。
为了揭示这两种不确定性,一种直接的解决方法是通过不确定性估计技术对它们进行估计。在这些技术中,数据不确定性和模型不确定性也分别被称为任意不确定性和认知不确定性[21,19]。前者指的是观测中固有的噪声,即使收集更多的数据也无法减少。后者解释了模型中的不确定性,并抓住了模型缺乏代表性的问题,这可以通过增加训练数据来解释。已经提出了大量的工作来模拟这两种类型的不确定性。他们通常利用贝叶斯神经网络(BNN)来学习从输入数据到数据不确定性的映射,并将其与模型不确定性近似组合在一起[21]。BNN用于不确定性估计的主要问题是难以处理的后验推理,因此大多数现有的不确定性估计技术都侧重于设计近似后验推理[13,21,14,17,4]。[13]利用dropout变分推理作为在大型复杂模型中进行近似推理的实用方法。[21]使用蒙特卡罗采样近似后验推理。根据[21],我们采用蒙特卡罗萨姆林进行不确定性近似。
在我们的工作中,我们提出了一个不确定性引导的学习框架,该框架结合了一个新的不确定性估计网络(UEN)来捕获数据和建模不确定性。UEN由动态不确定性监督(DUS)和不确定性预测精化(UPR)两个关键部分组成。具体来说,我们推导出预测结果与GT之间的差值作为UEN的动态不确定性监督。由于DUS的精心设计,数据不确定性和模型不确定性图被精确估计,并在UPR中进一步整合,以完善篡改预测。通过上述设计,我们的方法能够通过为错误分类的区域分配高不确定性和为正确分类的区域分配低不确定性来识别过度分割、欠分割和虚幻分割区域。大量的实验证明了该方法的有效性和可推广性。
•我们开发了一种新的图像处理检测学习框架,该框架适用于现有的基于分割的图像处理检测方法。据我们所知,我们是第一个将不确定性建模引入图像处理检测以解决挑战的人。
•我们通过明确建模来解决数据不确定性和模型不确定性。在动态监督下,我们的方法能够输出准确的不确定性估计结果,并进一步与UPR模块集成以改进操作预测。
•我们在图像处理检测的四个基准上实现了最先进的结果。在多个基准测试上的大量实验证明了我们的方法的优越性和通用性。
2. Related work
图像处理检测。许多现有的IMD方法都是基于分割的[25,41,11,40]。与一般的语义分割相比,IMD更具挑战性,因为精细的图像伪造几乎无法区分。为了检测操作,人们开发了许多算法来提取篡改特征和抑制语义特征。Zhou等人[42,43]利用噪声特征来发现被操纵图像中的不一致性。RGB-N[43]引入了一种用于操作检测的双流网络,其中一个流提取RGB特征以捕获视觉伪像,另一个流利用噪声特征对被操作区域和原始区域之间的不一致性进行建模。PSCC-Net [25]通过自顶向下的路径提取层次特征,检测输入图像是否使用自底向上路径进行了操作。Zhou等[41]提出了一种基于语义分割的GSR-Net模型,该模型由生成、分割和细化三个部分组成。Hu等[20]提出了一种所谓的SPAN模型,通过基于注意的设计来关注目标图像中的重要区域。
模型不确定性估计。模型不确定性估计的目的是估计模型参数集p(θ|D)的分布,其中θ遵循某种特定的分布导致贝叶斯神经网络(BNN), D为训练数据集。BNN的主要研究重点是如何实现有效的后验推理p(θ|D),这在实践中是一个棘手的问题。在这种情况下,现有的技术主要是近似后验推理。一项工作提出使用马尔可夫链蒙特卡罗(MCMC)方法[26]及其变体[37,16,7]作为近似解[21]。另一项工作采用基于dropout的方法[13]。例如,通过在测试时应用dropout[30],可以从近似后验中采样多个网络,并且输出的方差可以用作不确定性的度量[14]。
数据不确定性估计。数据不确定性估计的基本假设是模型参数θ是固定且未知的,这导致了基于非贝叶斯神经网络的框架。SDE-Net[22]提出了一个生成概率分布作为输出的网络,以捕捉这种不确定性。[23]使用对抗摄动技术生成额外的训练数据来捕获数据的不确定性。此外,捕获的数据不确定性可以用来指导不同任务的训练流程。Wang等[36]利用数据不确定性指导半监督目标检测多阶段训练的数据选择。Subedar等[31]利用不确定性帮助视觉模态和音频模态融合进行视听活动识别。Chang等[6]对数据不确定性进行建模,以减少噪声样本对人脸识别的不利影响。
3. Proposed method
为了测量不确定性,我们提出了一个带有DUS的不确定性估计网络,该网络生成准确的不确定性图,然后将它们集成到网络中,通过称为UPR的特征细化模块来减轻学习困难。在本节中,我们将详细描述所提出的方法。
3.1. Uncertainty estimation network 不确定性估计网络
对于图像处理检测,给定输入图像I∈RH×W ×3,首先由特征提取器Fθe提取特征嵌入E = Fθe(I)∈Rh×w×c。
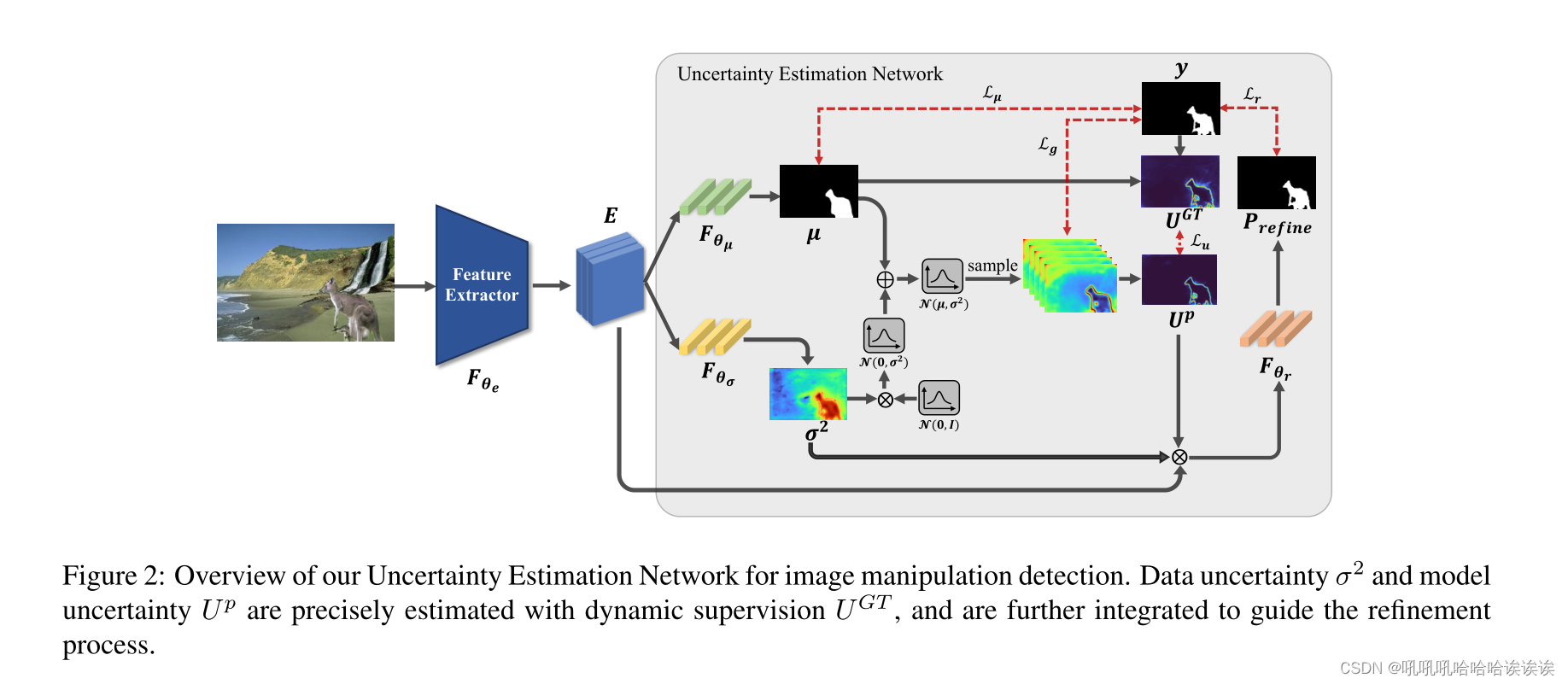
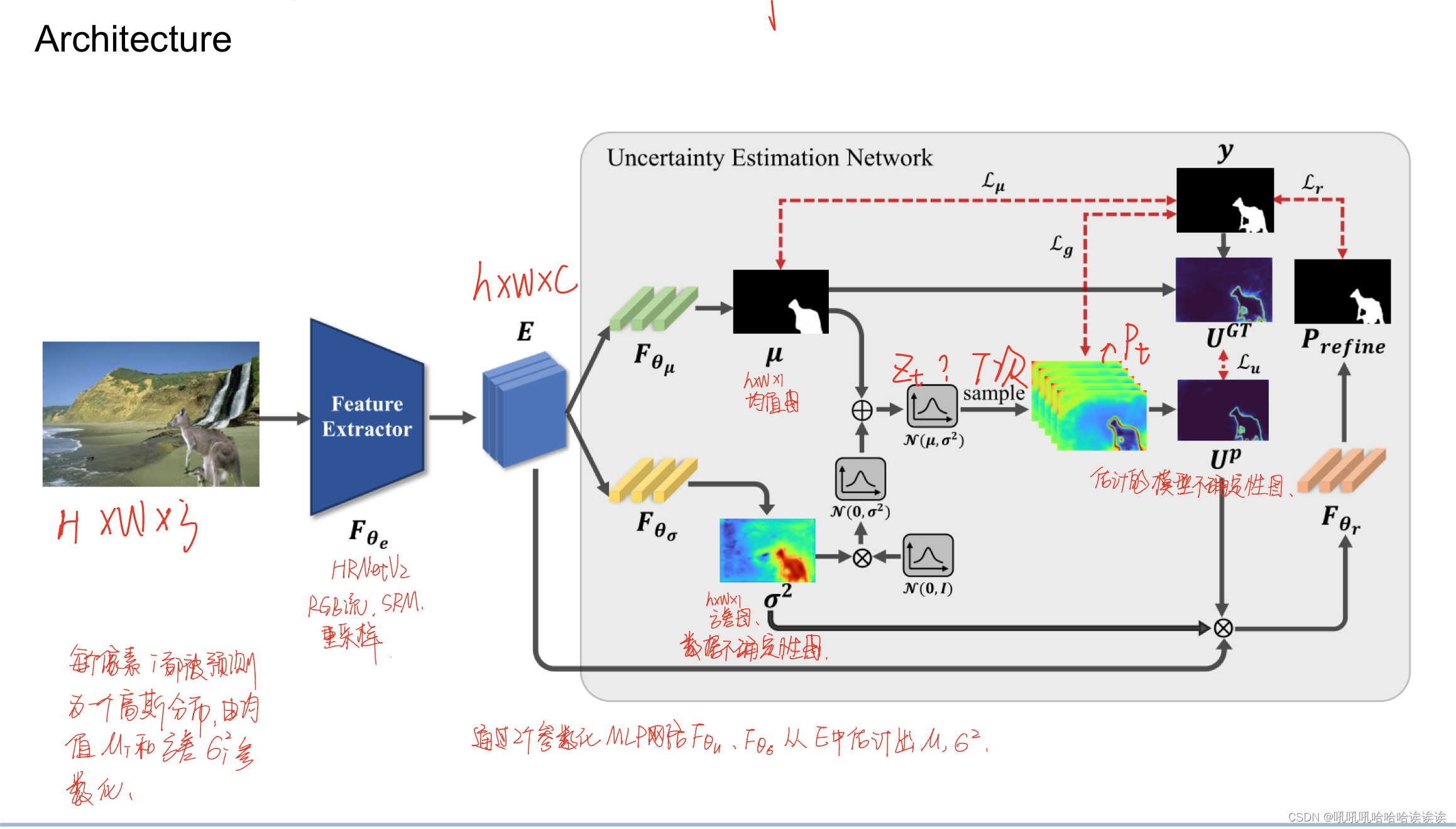
在这项工作中,我们建立了我们的不确定性估计网络(UEN)作为一个概率表示模型来测量不确定性,如图2所示。与传统方法[20,25,8]不同的是,传统方法通过单参数化MLP网络简单地将特征E映射到不确定性预测,我们通过两个参数化MLP网络(Fθµ和Fθσ)从特征E中估计出µ和σ2。流程制定如下:
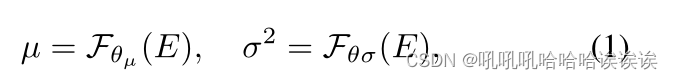
其中µ∈Rh×w×1, σ2∈Rh×w×1分别为均值图和方差图。具体来说,每个像素i被预测为一个高斯分布,由平均值µi和方差σ2i参数化。平均图µ相当于传统方法的预测结果,在我们的模型中作为粗预测,而方差图σ2是高斯噪声,捕获数据的不确定性。我们将在3.2节详细说明方差图σ2是如何表示数据不确定性的。
如前所述,每个像素的输出是一个服从高斯分布的随机变量。我们定义概率对数zi,t为第i个像素点从学习分布中抽取的第t个样本,概率分数pi,t就是sigmoid函数的输出:
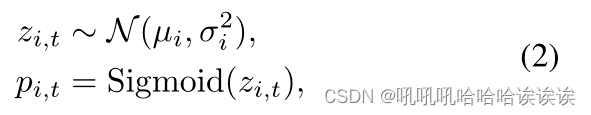
其中µi和σ2i由式(1)产生。由于在训练过程中,直接从高斯分布中采样zi,t不能反向传播梯度,因此我们采用重参数化技巧[3]进行采样。具体来说,我们首先从标准高斯分布N (0, I)中随机抽取一个变量ϵt,即ϵt ~ N (0, I),然后通过以下计算得到一个样本zi,t:
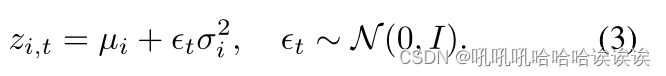
其中t表示第t次抽样。通过这样做,反向传播正常工作。通过式(3),平均映射µ被高斯噪声σ2破坏。我们最后将估计的模型不确定性总结为T次蒙特卡罗抽样的熵的期望:
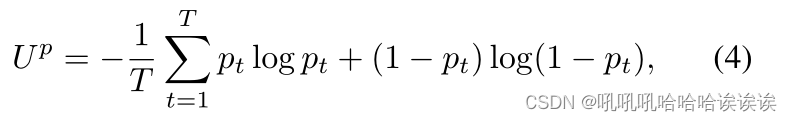
其中Up为估计的模型不确定性图,归一化为[0,1],pt为第t次抽样估计的篡改分数图。直观的感觉是,当采样的pt趋向于其上限或下限时,说明模型的预测可信度较高,模型不确定性Up较低。当pt接近其合法范围的中间值时,说明模型对结果的不确定性较大,导致模型不确定性Up较高。

3.2. Dynamic uncertainty supervision 动态不确定性监督
我们利用动态不确定性监督(DUS)对不确定性估计进行优化,其推导为:
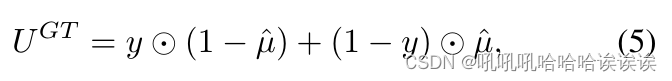 其中⊙为Hadamard积,µ由Sigmoid(µ)计算,y为输入图像I对应的GT,UGT捕获真值y与µ的差值。当网络做出不确定预测时,式(5)赋予UGT较高的不确定性,反之亦然。例如,第i个像素的标签为1,表示被操纵的像素,而预测结果为0.4,表示假的不确定的像素,即yi = 1, μ i = 0.4,为U GTi赋值0.6,表示该像素上的高不确定性。µ随着模型迭代而变化,因此UGT也根据µ动态适应,以提供更准确的监督。
其中⊙为Hadamard积,µ由Sigmoid(µ)计算,y为输入图像I对应的GT,UGT捕获真值y与µ的差值。当网络做出不确定预测时,式(5)赋予UGT较高的不确定性,反之亦然。例如,第i个像素的标签为1,表示被操纵的像素,而预测结果为0.4,表示假的不确定的像素,即yi = 1, μ i = 0.4,为U GTi赋值0.6,表示该像素上的高不确定性。µ随着模型迭代而变化,因此UGT也根据µ动态适应,以提供更准确的监督。
在动态监督下,不确定性估计通过以下目标函数进行优化:
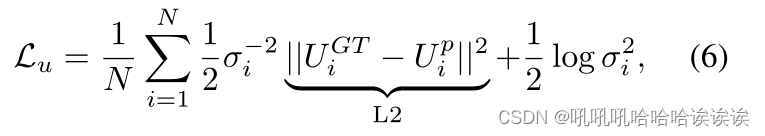
其中N为预测结果中总像素数,L2 loss 用于动态模型不确定性监督。为了理解Lu的设计理念,让我们考虑两种可能会增加UGTi的情况: 1.GT yi是正确的,我们的粗略预测µi是错误的; 2. GT yi是错误的,而预测µi是完全正确的。前者预计将被我们的模型不确定性Upi捕获,因为模型给出了错误的预测,其置信度普遍较低,导致L2值相对较小。后者是数据不确定性的来源。在这种情况下,U GTi仍然很大,因为yi和μ i之间的差异很大,而Upi很小,因为模型的预测是正确的。然后将方差σ2i最大化,以减小由于U GTi与Upi之间的差异而导致的较大的L2值,这完全符合数据不确定性的定义,因为当数据不确定性发生时,σ2i就会增大。1/2log σ2i是防止σ2i变得无限大的正则化项。由此可知,σ2是测量数据不确定性的一个很好的方法。式(6)为不确定性估计提供了直接监督,提高了不确定性估计的可靠性。
3.3. Uncertainty-guided prediction refinement 不确定性导向的预测精化
图像处理检测在整个图像中具有不同的学习困难。首先,被操纵的内容通常与背景很好地融合,并且沿着被操纵的mask边界的像素相当难以区分。其次,在模型预测过程中,被操纵的伪影是微妙的,更容易出现过分割、欠分割和虚幻分割。我们打算通过设计不确定性引导预测精化(UPR)来解决这些困难。具体来说,我们提出将特征嵌入E与加权不确定性映射耦合起来。公式如下:
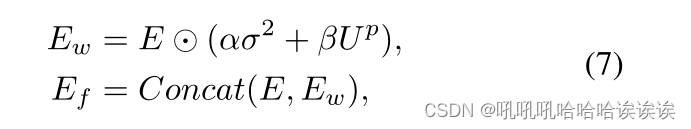

⊙表示Hadamard乘积运算,α和β是调节估计的数据不确定映射σ2与模型不确定映射Up之间的权值的超参数,E和Ew在通道维度上连接,形成精细化特征Ef。然后通过Pref fine = Fθr(Ef))得到最终预测结果。Fθr由两个卷积核大小为1 × 1的连续卷积层组成,每个卷积层后面都有一个批归一化层和一个ReLU[15]激活函数。整个训练过程在算法1中进行了说明,该方法适用于其他现有的基于分割的IMD方法。
 3.4. Loss functions
3.4. Loss functions
我们UEN的总损失由四个部分组成。
首先,对于式(2)中为估计模型不确定性而组成的样本,我们的期望对数似然为:
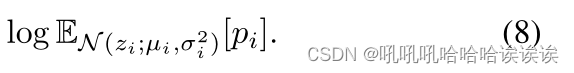
然而,直接计算期望是棘手的,因此我们通过T次蒙特卡罗采样近似目标,并制定如下损失,使训练更稳定:
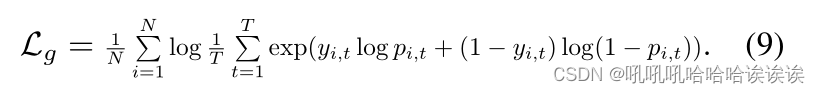
其次,采用二元交叉熵(binary Cross Entropy, BCE)损失函数通过GT y对粗预测µ和精预测Prefine进行监督;
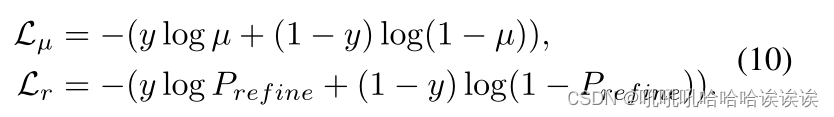
最后,我们用一个总损失函数来训练我们的框架:
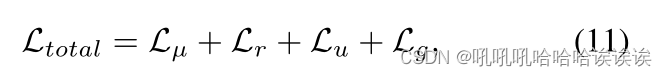
其中Lu为式(6)中引入的监督不确定性估计的损失函数。

4. Experimental results
4.1. Experimental settings
数据集。在这项工作中,我们在四个标准数据集上评估了我们的方法,即CASIA [12], NIST16 [18], Columbia[27]和COVERAGE[38]。CASIA有两个版本。CASIA v1.0包含921张经过处理的图像,以及原始建设者提供的GT[12]。CASIA v2.0包含5123个被操纵的样本,这些样本由Pham等[28]生成GT,尽管分布广泛,但被认为是有噪声的。两个版本都包含拼接和复制移动图像,其中伪造区域是精心选择的。继[25,34,41]之后,我们使用CASIA v2.0进行训练,CASIA v1.0进行测试。NIST16是由564个拼接,复制移动,或删除的操纵样本组成。根据[25,34],我们使用404个样本进行训练,160个样本进行测试。Columbia提供180张拼接图像。这些图像大多是室内场景,一小部分是室外拍摄的。COVERAGE数据集包含100张通过复制-移动技术生成的图像。Columbia和COVERAGE都只用于测试CASIA v2.0上训练的模型。除CASIA v2.0外,上述数据集的掩码标签由数据集构建者提供。我们相信标签是准确的,测试结果是值得信赖的。为了公平比较,数据集的训练和测试方案与[25]相同。
评价指标。我们使用基准指标:F1分数和曲线下面积(AUC)在像素级别评估我们的模型。F1分数和AUC衡量每个像素的二值分类性能,分数越高表示性能越好。
实现细节。我们的方法是一个通用的范例,可以很容易地扩展到现有的IMD方法。在不失通用性的前提下,我们提出了一个具有通用设计的特征提取器作为基准,并将我们的方法集成到其中。具体而言,我们采用HRNetV2[33]作为主骨干网络,分4个阶段提取RGB特征。我们的特征提取器还包括实用的SRM[43]和重采样特征[1]。具体地说, SRM分支采用并行结构作为骨干网,在相应阶段结束时与RGB分支融合。重采样分支在第4阶段开始,并在第4阶段结束时与其他两个分支融合。
我们以端到端方式训练我们的方法。特征提取器的RGB流网络使用ImageNet[10]分类预训练权值进行初始化,随机初始化SRM流和重采样流的权值。在训练过程中,首先调整输入图像的大小,使较短的长度为512,然后随机裁剪为512 × 512。为了避免由于训练和测试之间的大小不匹配导致的性能下降,我们在测试阶段将图像大小调整为512 × 512。在接下来的实验中,除非另有说明,否则采样频率T设为100,超参数α和β设为0.5。采用SGD作为优化器,初始学习率设置为5×10−5,并呈指数衰减。该模型采用PyTorch深度学习框架实现,在8台NVIDIA V100 GPU上进行了240次epoch的训练,每台GPU的批处理大小为8个。所有的训练都以相同的批大小和随机种子进行。
4.2. Comparison with state-of-the-art approaches
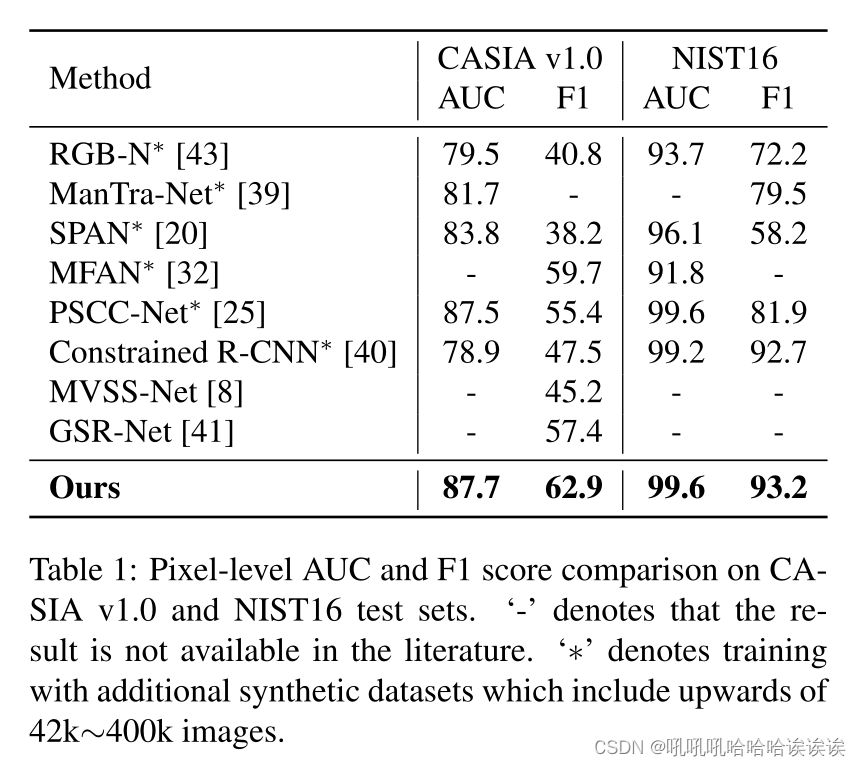
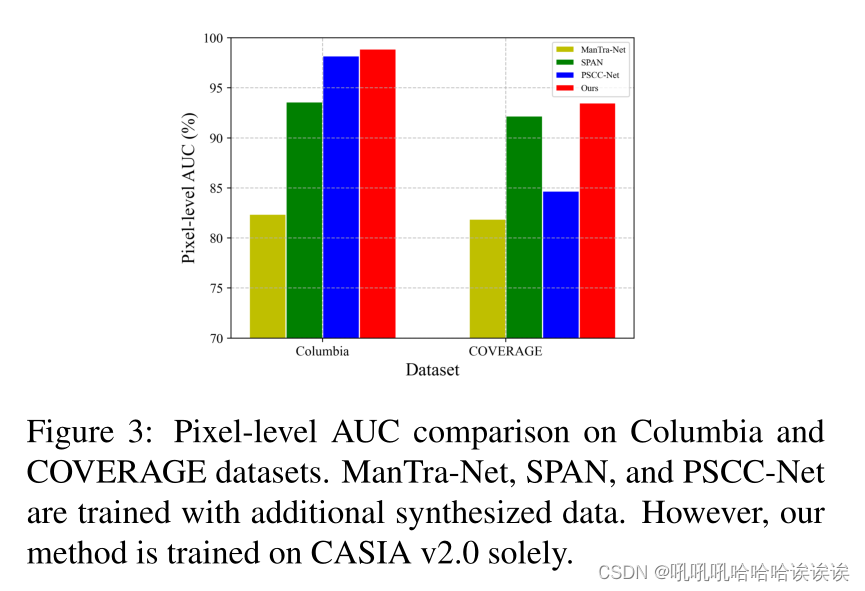
我们将我们的方法与现有的最先进的方法在四个标准基准上进行比较。表1显示了CASIA和NIST16数据集上的性能比较。我们的方法在两个数据集上实现了两个指标的最高性能。具体来说,我们的F1分数在CASIA v1.0上比第二名高出3.2%,在NIST16上比第二名高出0.5%。此外,在Columbia和COVERAGE数据集上,由于其他方法只报告AUC度量,我们在图3中报告像素级的AUC结果。显然,我们的方法比其他的方法要好得多。值得注意的是,许多方法都是用额外的合成数据来训练的,以达到有竞争力的表现。例如,PSCC-Net使用COCO[24]中的分割注释,随机选择对象,然后将其拼接到其他图像中,创建了一个包含400k张操纵图像的合成数据集。由于训练数据丰富,PSCC-Net在Columbia数据集上的像素级AUC达到了98.2%。我们认为,为训练添加额外的合成数据可能会进一步提高我们方法的性能,但这不是我们工作的重点。由于不确定性建模和不确定性引导学习设计,我们的方法优于这些方法,这表明了我们的方法的优越性。
4.3. Ablation study
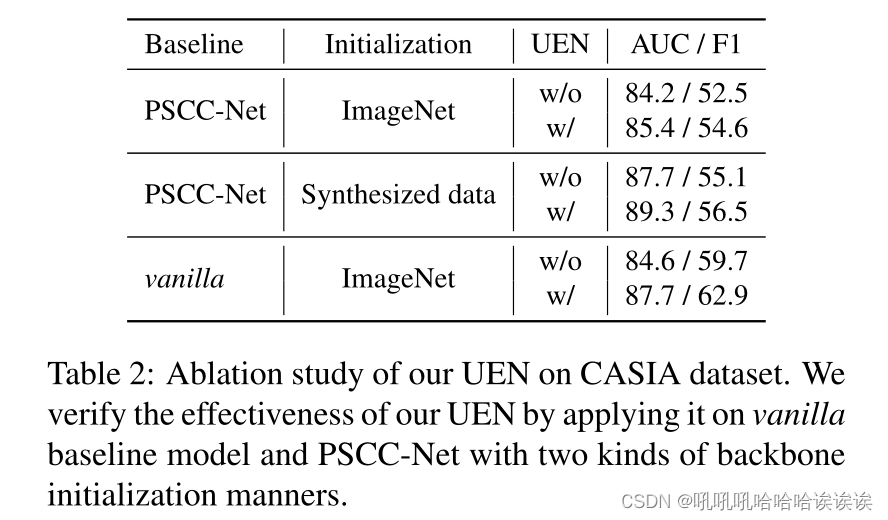
UEN的有效性和通用性。我们的UEN是一个可插拔模块,可以很容易地扩展到其他基于分割的IMD方法。因此,除了在基线上消融UEN外,我们还将UEN进一步部署到PSCC-Net1上,以验证其通用性。消融研究和结果见表2。当不使用UEN时,基线是传统的基于分割的IMD模型,F1/AUC的结果为84.6%/59.7%。我们的UEN进一步提高了性能,比AUC和F1分别提高了3.1%/3.2%,证明了它的有效性。此外,我们采用两种骨干初始化方式将UEN集成到PSCC-Net中,即使用ImageNet分类权值初始化或使用大规模合成数据集预训练权值初始化。对于在大规模合成数据集上使用预训练权值的PSCC-Net,我们再现了结果,得到AUC和F1的比值为87.7%/55.1%,与文献中的87.5%/55.4%接近。我们的UEN进一步提高了结果,F1和AUC分别提高了1.6%和1.4%。当使用ImageNet预训练权值时,PSCC-Net的性能分别提高了1.2%和2.1%。值得注意的是,在没有大量合成数据预训练的情况下,PSCC-Net通过整合UEN实现了具有竞争力的F1(54.6%对55.1%)。它证明了模型和数据的不确定性对于IMD任务是必不可少的,我们的UEN是一个通用的、适应性强的模块,可以提高性能,而不受框架和初始化差异的影响。
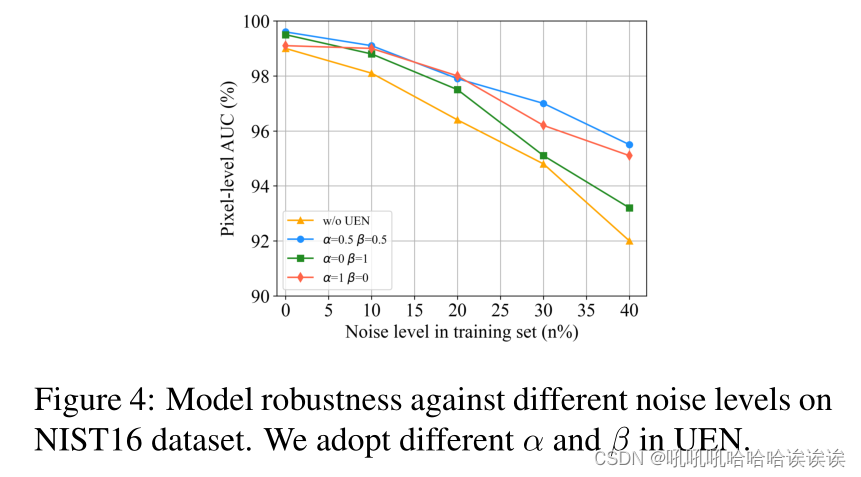
UEN的鲁棒性。为了验证UEN对标签噪声的鲁棒性,我们报告了我们的方法的结果,其训练集被不同程度的标签噪声破坏,如图4所示。考虑到NIST16数据集的标签是由数据集生成器提供的,我们认为该数据集的噪声水平为0%。我们在训练集中随机选择n%的图像,并将其被操纵区域的标签反向设置为未篡改。这样,我们得到了一个噪声水平为n%的训练集,涉及不同程度的数据不确定性。此外,我们采用不同的α和β来决定精细特征中的成分。如图4所示,我们可以看到,使用和不使用UEN的训练,其结果都随着噪声水平的增加而逐渐降低。然而,当噪声数据在整个训练集中占主导地位时,我们的UEN提供了更明显的改进,证明了UEN对训练噪声的鲁棒性。此外,当α = 0, β = 1,表明在精化中没有考虑数据不确定性图,当噪声水平大于30%时,性能会差很多,证明了数据不确定性建模在抗噪声训练中的有效性。
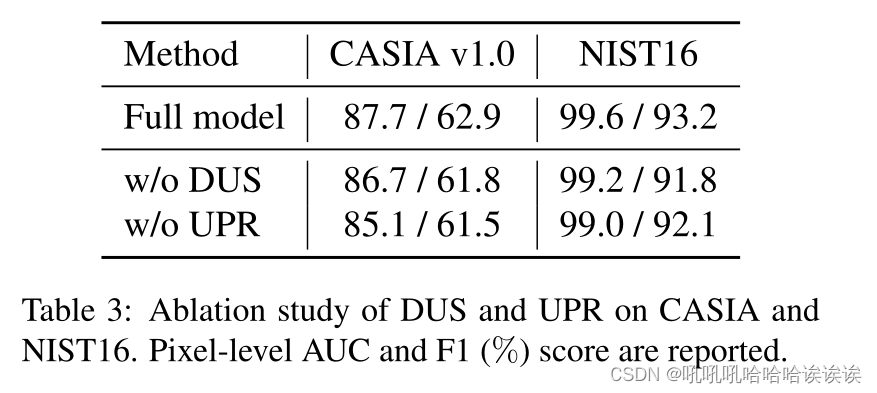
DUS和UPR的有效性。我们对DUS和UPR进行了多次消融研究,如表3所示。对于DUS消融研究,我们在训练期间丢弃了式(6)中的Lu,并观察到CASIA v1.0和NIST16数据集上AUC和F1的显著下降。例如,在没有DUS的情况下,我们的方法F1得分下降到91.8%,NIST16下降了1.4%,这反过来证明了我们的DUS方法的有效性。对于UPR消融研究,我们在训练和测试过程中删除了细化过程,并选择预测的平均图µ作为预测结果进行评估。去掉UPR后,CASIA v1.0的AUC下降了2.6%,这两个数据集的严重恶化表明了UPR的有效性。更多定性分析结果见4.4节。
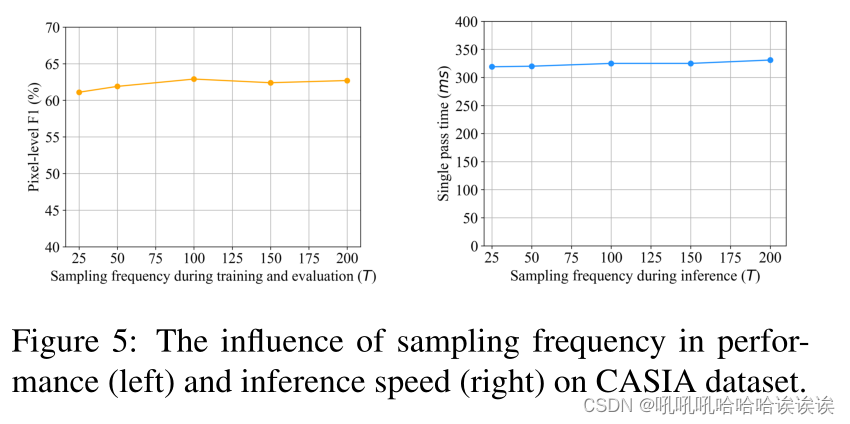
采样频率的影响。我们在图5中研究了采样频率对模型性能的影响。采样频率T设置为25 ~ 200,在训练和评估过程中保持不变。在左图中,当T大于100时,不同采样频率下的F1分数是稳定的,说明我们的方法对采样频率具有鲁棒性。此外,我们在图5的右图中评估了采样频率对推理速度的影响。可以观察到,当T在25 ~ 200范围内时,单次通过时间的增加非常小。这是因为我们只需要从logits中采样,这是网络计算的一小部分,因此不会显着增加推理时间。
4.4. Qualitative analysis
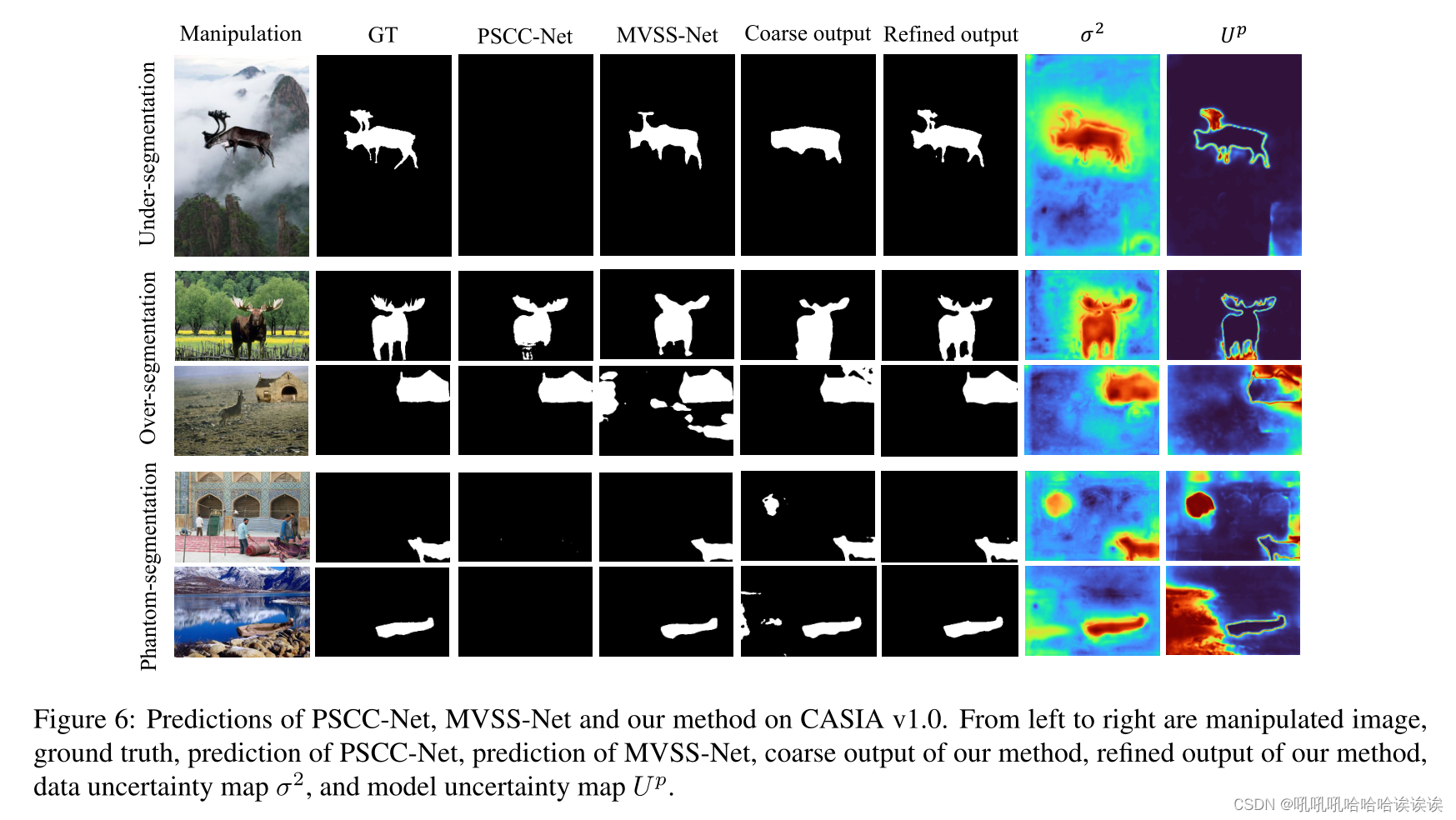
为了进一步证明我们的方法的有效性,在本节中,我们将提供取自CASIA v1.0的定性示例进行演示。在以下的分析中,我们讨论了两个方面:1.UEN是如何工作的? 2.与SOTA方法的比较。定性结果如图6所示。
UEN是如何工作的? 我们将粗预测µ、精预测、数据不确定性映射σ2和模型不确定性映射Up可视化在图6中。由于标注的不一致和边界标注的困难,在被处理的区域经常会产生噪声。因此,数据不确定性信号主要由被操纵对象及其边界控制,这与数据不确定性图σ2中的高亮区域一致。模型的不确定性通常集中在粗预测的错误分类区域和相应的边界上,我们的模型不确定性图Up也捕捉到了这一点。与粗预测和精预测相比,精预测通过整合不确定性图来修正错误分类区域,并输出精细分割结果,验证了UPR的有效性。此外,图6中的第一行说明了粗输出的分割不足情况,第二和第三行显示了过度分割情况,最后两行显示了虚幻分割情况。通过耦合UEN,我们的方法能够通过为错误分类的区域分配高不确定性和为正确分类的区域分配低不确定性来识别上述情况。
与SOTA方法的比较。我们还在图6中显示了我们的方法与其他最先进的方法的定性比较。很明显,我们的方法优于最先进的方法。例如,PSCC-Net在第二行的结果是under-segmented,而MVSS-Net在第三行的结果是phanto-msegmented。相反,我们的结果更准确,边界更精细,说明了我们方法的优越性。
5. Conclusion
在本文中,我们重新审视图像处理检测,并考虑该任务中的两个不确定性问题,即数据不确定性和模型不确定性。为了解决这些问题,我们引入了一种不确定性引导的图像处理检测方法,该方法通过建模数据的不确定性来捕获标注噪声,通过建模模型的不确定性来缓解语义不一致。我们在动态不确定性监督下训练了新的不确定性估计网络,这有利于准确的不确定性估计。此外,我们整合了数据不确定性和模型不确定性映射,以指导操作预测的改进。大量的实验证明了我们的方法的通用性和相对于现有的SOTA方法的优势。在未来,我们计划将UEN扩展到更多的方法和场景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









