







文章目录
前言
python学习笔记 (仅供学习使用)
一、XPath解析数据
1.XPath
全称: XML Path Language是一种小型的查询语言
是一门在XML文档中查找信息的语言
XPath的优点
可在XML中查找信息
支持HTML的查找
可通过元素和属性进行导航
Xpath需要依赖lxml库
安装方式 : pip3 install lxml
2.xml的树形结构
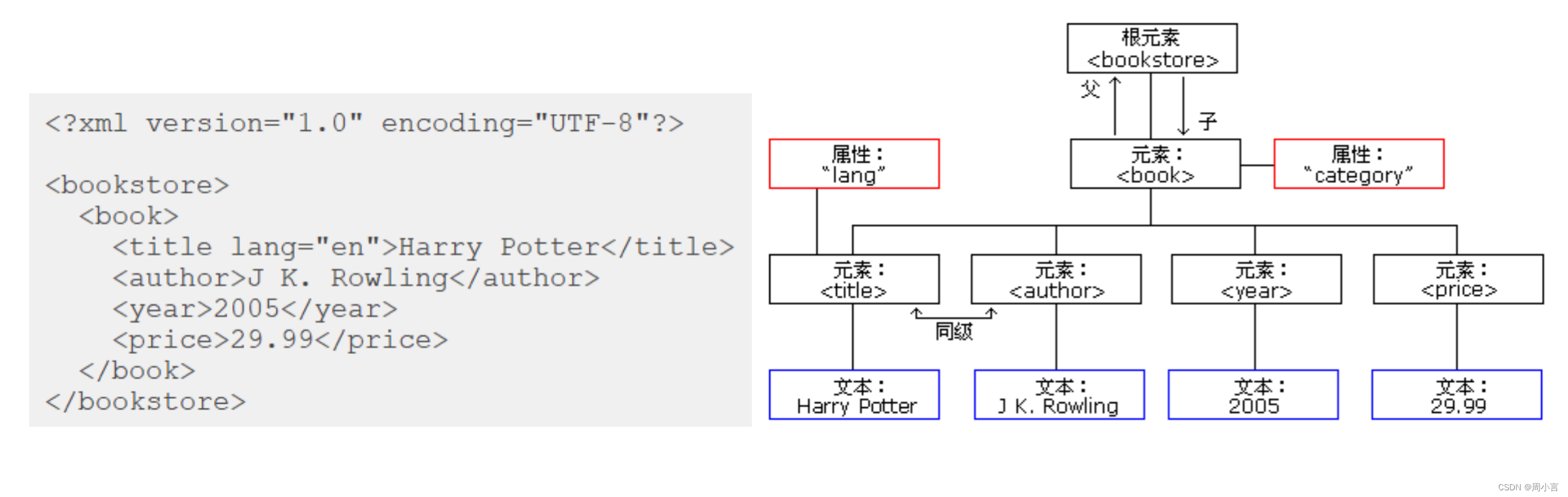
3.使用XPath选取节点
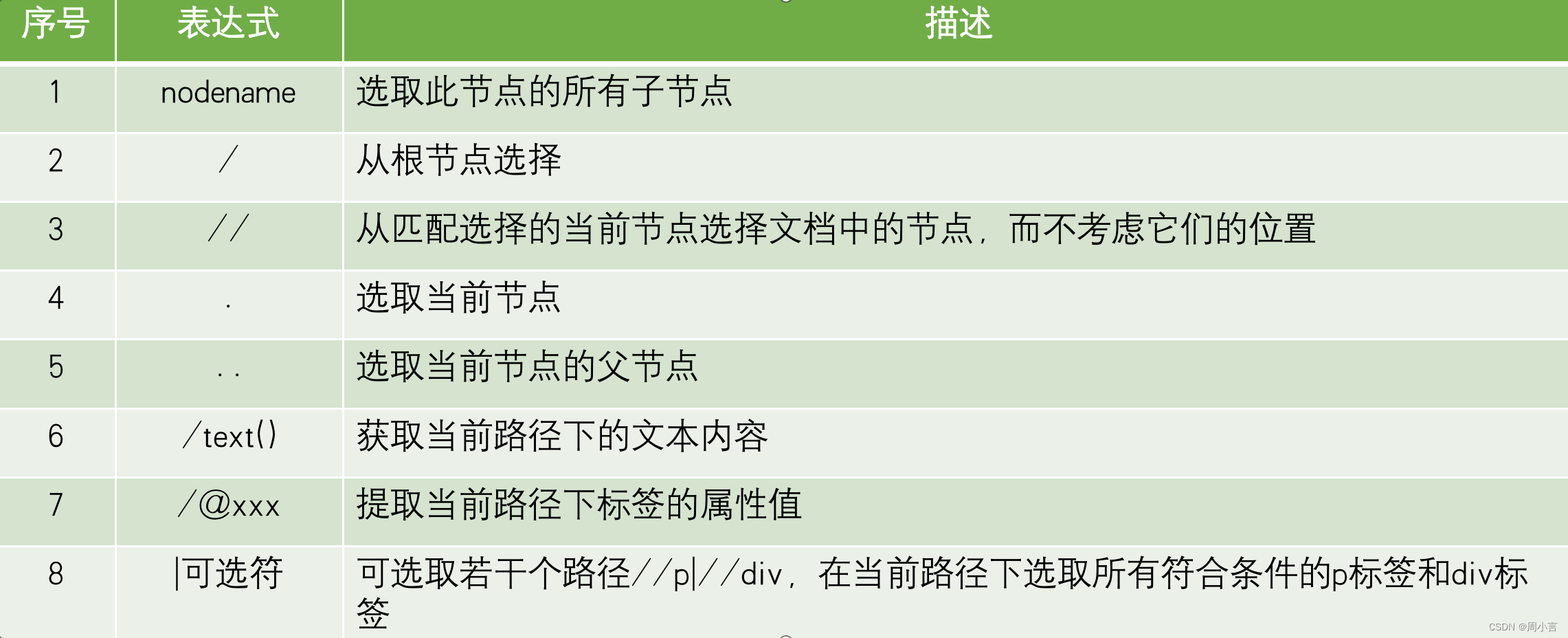
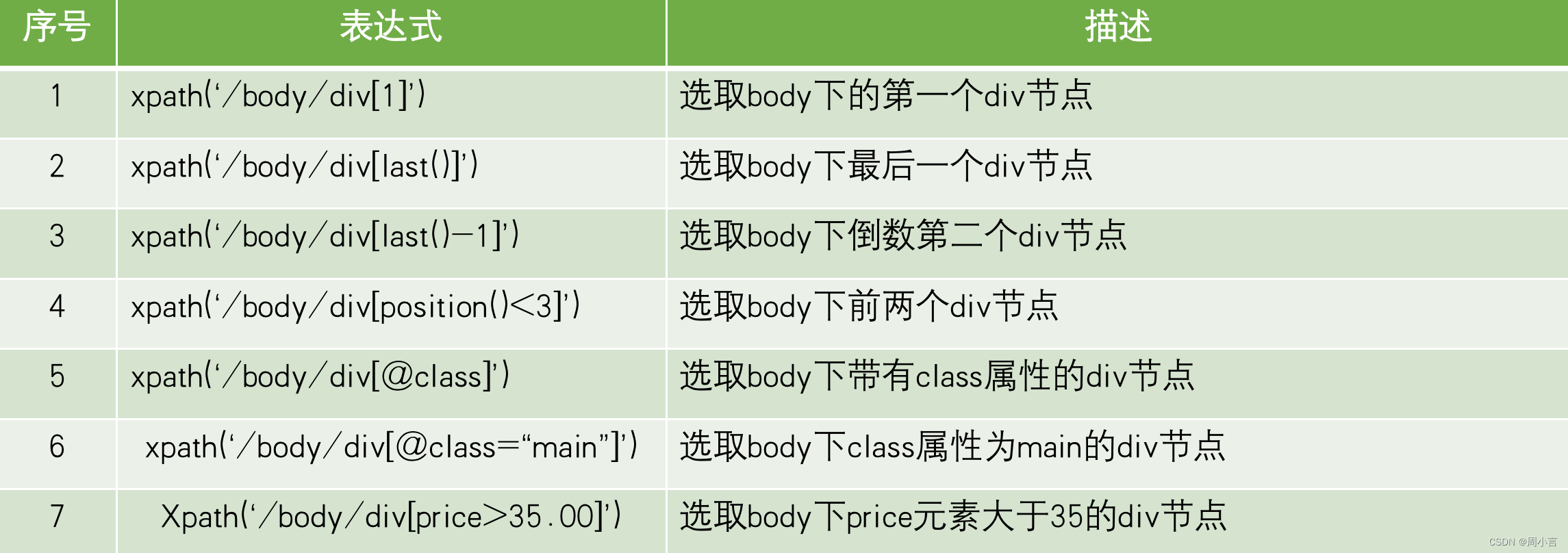
xpath的使用:
import requests
from lxml import etree
# url='https://www.qidian.com/rank/yuepiao'
url = 'https://m.qidian.com/'
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'}
#发送请求
resp=requests.get(url,headers)
e=etree.HTML(resp.text) #类型转换 将str类型转换成class 'lxml.etree._Element'
#print(type(e))
print(resp.text)
# names=e.xpath('//div[@class="book-mid-info"]/h4/a.txt/text()')
# authors=e.xpath('//p[@class="author"]/a.txt[1]/text()')
names=e.xpath('//div[@class="module-slide"]/ol/li/a[1]/figcaption[1]/text()')
print(names)
# print(authors)
# for name,author in zip(names,authors):
# print(name,":",author)
# //div[@class="module-slide"]/ol/li/a[1]/figcaption[1]/text()
# https://m.qidian.com/
二、BeautifulSoup解析数据
1.BeautifulSoup简介
BeautifulSoup
是一个可以从HTML或XML文件中提取数据的Python库。其功能简单而强大、容错能力高、文档相对完善,清晰易懂
非Python标准模块,需要安装才能使用
安装方式
pip3 install bs4
测试方式
import bs4
2.解析器
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果不安装第三方解析器,则Python会使用默认解析器
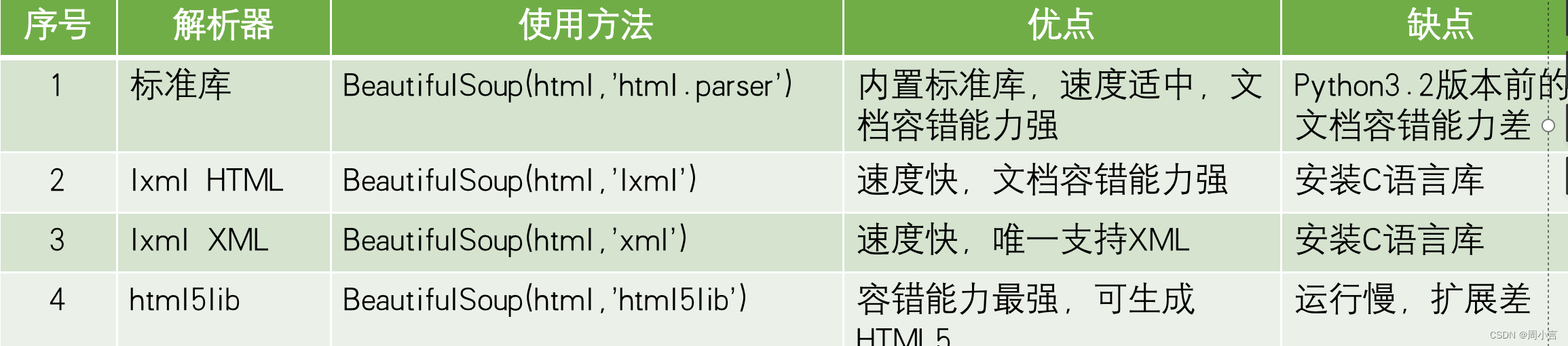
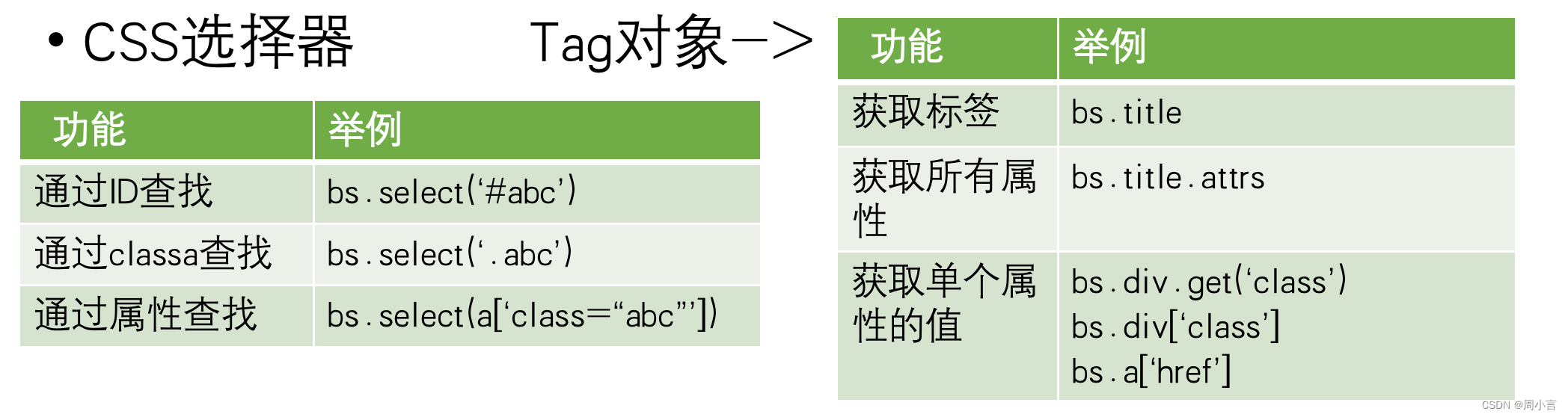
3.代码:
from bs4 import BeautifulSoup
html='''
<html>
<head>
<title>小周周</title>
</head>
<body>
<h1 class="info bg" float='left'>欢迎大家来到马士兵教育</h1>
<a href="http://www.baidu.com"> 百度</a.txt>
<h2><!--注释的内容--></h2>
</body>
</html>
'''
#bs=BeautifulSoup(html,'html.parser')
bs=BeautifulSoup(html,'lxml')
print(bs.title) #获取标签
print(bs.h1.attrs) #获取h1标签的所有属性
#获取单个属性
print(bs.h1.get('class'))
print(bs.h1['class'])
print(bs.a['href'])
#获取文本内容
print(bs.title.text)
print(bs.title.string)
#获取内容
print('--------',bs.h2.string) #获取到h2标签中的注释的文本内容 获取所有内容
print(bs.h2.text) #因为h2标签中没有正而八经的文本内容 获取文本内容
run:
<title>小周周</title>
{'class': ['info', 'bg'], 'float': 'left'}
['info', 'bg']
['info', 'bg']
http://www.baidu.com
小周周
小周周
-------- 注释的内容
two:
from bs4 import BeautifulSoup
html='''
<title>你好啊</title>
<div class="info" float="left">欢迎来到异世界</div>
<div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div>
<span>你好,Python</span>
'''
bs=BeautifulSoup(html,'lxml')
print(bs.title,type(bs.title))
print(bs.find('div',class_='info'),type(bs.find('div',class_='info'))) #获取第一个满足条件的标签
print('--------------------------------------')
print(bs.find_all('div',class_='info')) #得到的是一个标签的列表
print('--------------------------------------')
for item in bs.find_all('div',class_='info'):
print(item,type(item))
print('--------------------------------------')
print(bs.find_all('div',attrs={'float':'right'}))
print('===============CSS选择器=======================')
print(bs.select("#gb"))
print('--------------------------------------')
print(bs.select('.info'))
print('--------------------------------------')
print(bs.select('div>span')) #div下面的span
print('--------------------------------------')
print(bs.select('div.info>span'))
for item in bs.select('div.info>span'):
print(item.text)
run:
<title>你好啊</title> <class 'bs4.element.Tag'>
<div class="info" float="left">欢迎来到异世界</div> <class 'bs4.element.Tag'>
--------------------------------------
[<div class="info" float="left">欢迎来到异世界</div>, <div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div>]
--------------------------------------
<div class="info" float="left">欢迎来到异世界</div> <class 'bs4.element.Tag'>
<div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div> <class 'bs4.element.Tag'>
--------------------------------------
[<div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div>]
===============CSS选择器=======================
[<div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div>]
--------------------------------------
[<div class="info" float="left">欢迎来到异世界</div>, <div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a.txt href="http://www.baidu.com">官网</a.txt>
</div>]
--------------------------------------
[<span>好好学习,天天向上</span>]
--------------------------------------
[<span>好好学习,天天向上</span>]
好好学习,天天向上
三、用beautifulsoup爬淘宝首页
import requests
from bs4 import BeautifulSoup
url='https://www.taobao.com/'
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'}
resp=requests.get(url,headers)
# print(resp.text)
bs=BeautifulSoup(resp.text,'lxml')
a_list=bs.find_all('a')
#print(len(a_list))
for a in a_list:
url=a.get('href')
#print(url)
if url==None:
continue
if url.startswith('http') or url.startswith('https'):
print(url)
run:
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=T恤&refpid=420462_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f67
https://s.taobao.com/search?q=%E5%A5%B3%E9%9E%8B&refpid=420466_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f68
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=短裤&refpid=430145_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f69
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=半身裙&refpid=430146_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f70
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=男士外套&refpid=430147_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f70
https://s.taobao.com/search?q=墙纸&refpid=430148_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f70
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=行车记录仪&refpid=420467_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f69
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=男鞋&refpid=430144_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f69
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=耳机&refpid=420463_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f67
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=女包&refpid=420464_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f68
http://s.taobao.com/search?spm=1.7274553.1997520241-2.2.TpEKPQ&q=沙发&refpid=420465_1006&source=tbsy&style=grid&tab=all&pvid=d0f2ec2810bcec0d5a16d5283ce59f68
https://market.m.taobao.com/app/fdilab/download-page/main/index.html
四、re正则表达式
是一个特殊的字符序列,它能帮助用户便捷地检查一个字符串是否与某种模式匹配。
Python的正则模块是re,是Python的内置模块,不需要安装,导入即可
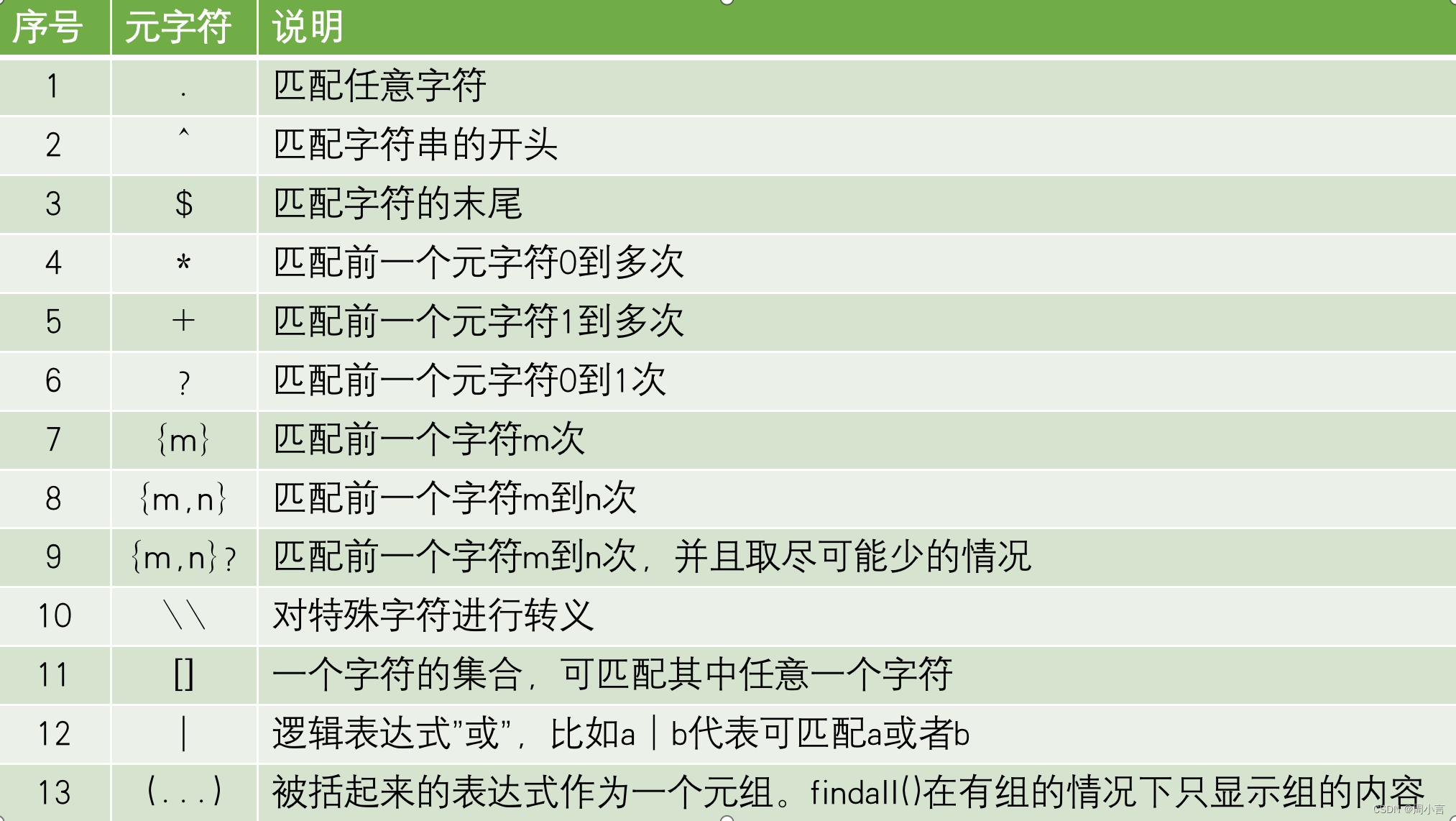
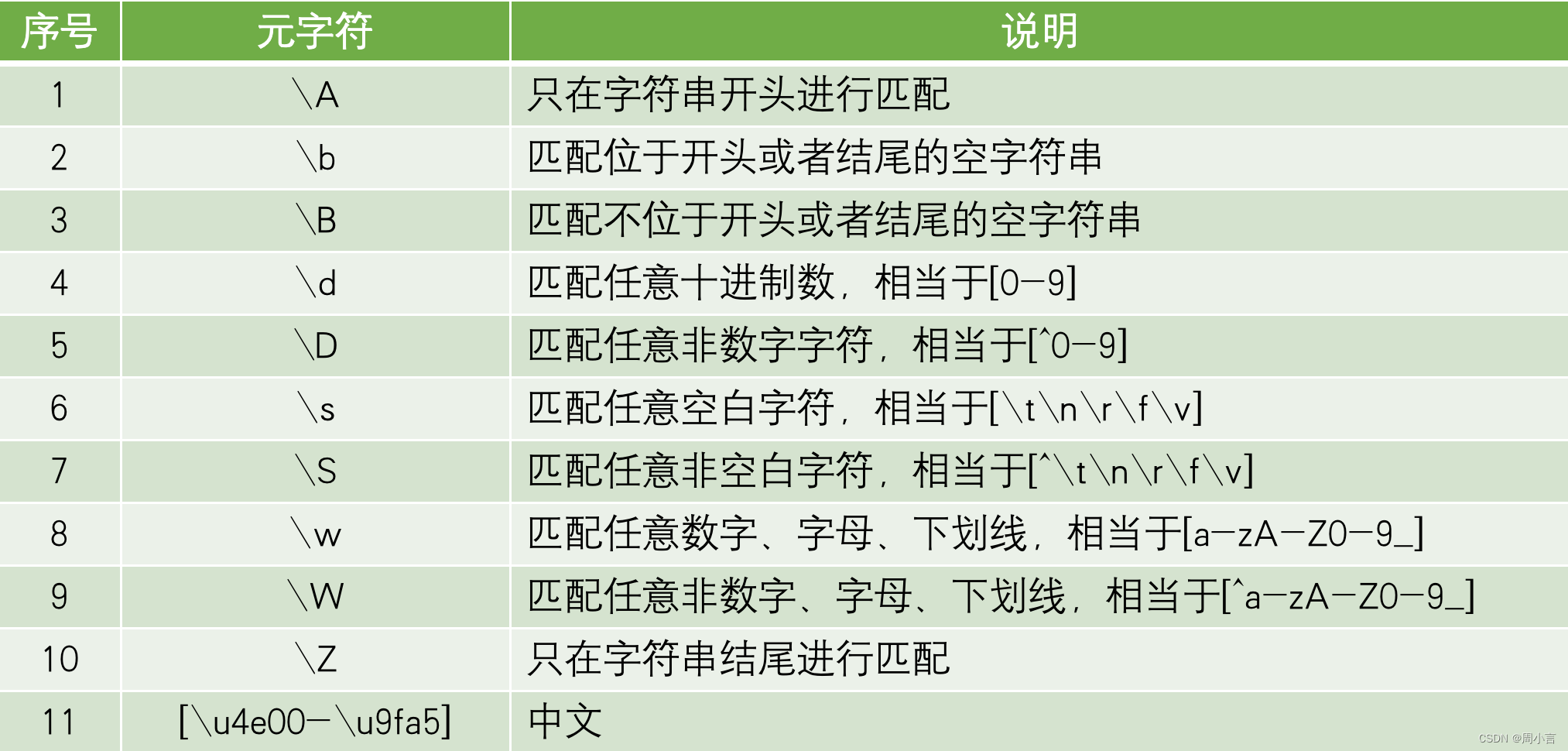
特殊序列:
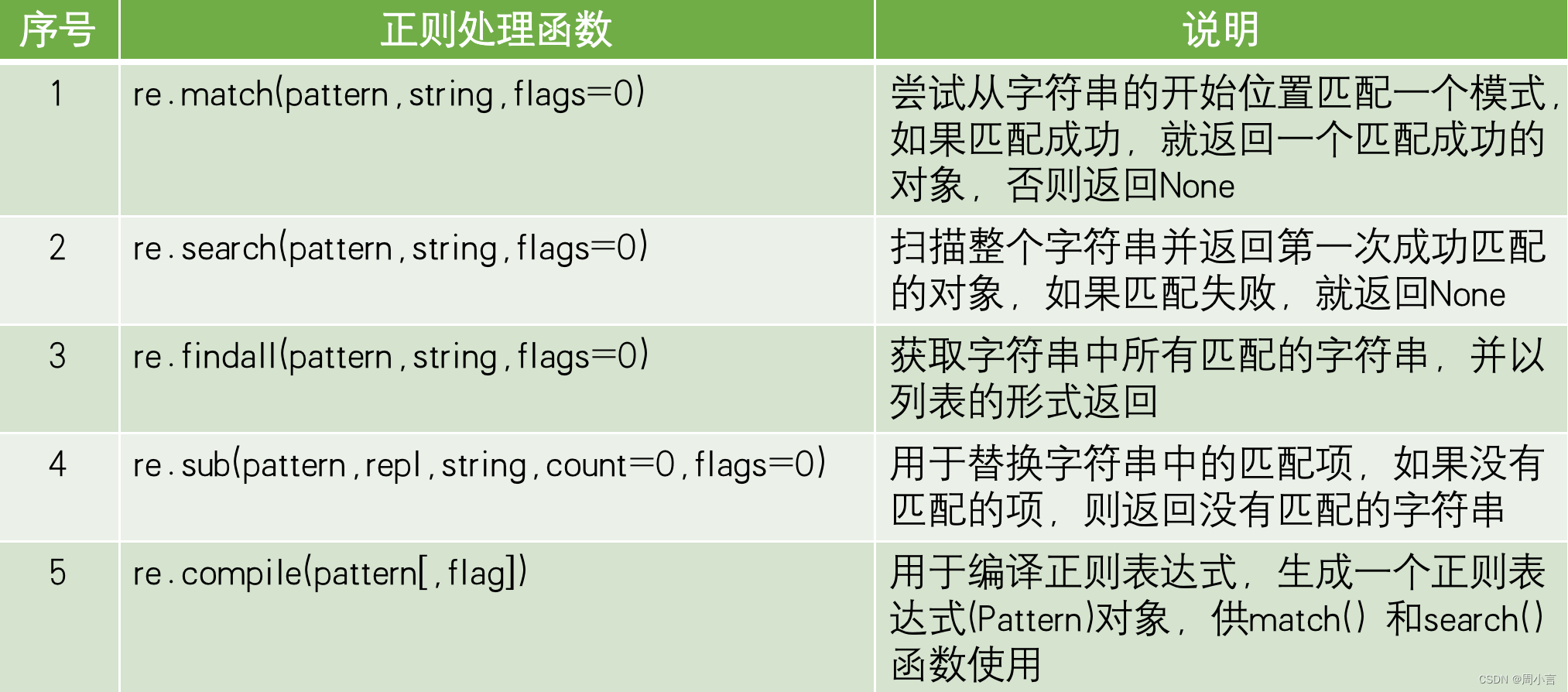
正则处理函数:
import re
s='Istudy study Python3.8 every day'
print('----------------match方法,从起始位置开始匹配------------')
print(re.match('I',s).group())
print(re.match('\w',s).group())
print(re.match('.',s).group())
print('---------------search方法,从任意位置开始匹配,匹配第一个---------------')
print(re.search('study',s).group())
print(re.search('s\w',s).group())
print('---------------findall方法,从任意位置开始匹配,匹配多个-----------------')
print(re.findall('y',s)) #结果为列表
print(re.findall('Python',s))
print(re.findall('P\w+.\d',s))
print(re.findall('P.+\d',s))
print('--------------sub方法的使用,替换功能-------------------------')
print(re.sub('study','like',s))
print(re.sub('s\w+','like',s))
爬虫糗事百科中的视频:
import requests
import re
url='https://www.qiushibaike.com/video/'
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'}
resp=requests.get(url,headers=headers)
#print(resp.text)
info=re.findall('<source src="(.*)" type=\'video/mp4\' />',resp.text)
#print(info)
lst=[]
for item in info:
lst.append('https:'+item)
#print(lst)
count=0
for item in lst:
count+=1
resp=requests.get(item,headers=headers)
with open('video/'+str(count)+'.mp4','wb') as file:
file.write(resp.content)
print('视频下载完毕')
五、pyquery解析数据
pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好
前提条件:
你对CSS选择器与JQuery有所了解
非Python标准模块,需要安装
安装方式
pip3 install pyquery
测试方式
Import pyquery
1.第一种创建方式
from pyquery import PyQuery as py
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<h1>PyQuery</h1>
</body>
</html>
'''
doc=py(html) #创建PyQuery的对象,实际上就是在进行一个类型转换,将str类型转成PyQuery类型
print(doc)
print(type(doc))
print(type(html))
print(doc('title'))
run:
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<h1>PyQuery</h1>
</body>
</html>
<class 'pyquery.pyquery.PyQuery'>
<class 'str'>
<title>PyQuery</title>
2.第二种创建方式
from pyquery import PyQuery
doc=PyQuery(url='http://www.baidu.com',encoding='utf-8')
print(doc('title'))
run:
<title>百度一下,你就知道</title>
3.第三种创建方式
from pyquery import PyQuery
doc=PyQuery(filename='demo.html')
print(doc)
print(doc('h1'))
run:
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<h1>PyQuery</h1>
</body>
</html>
<h1>PyQuery</h1>
六、pyquery的使用
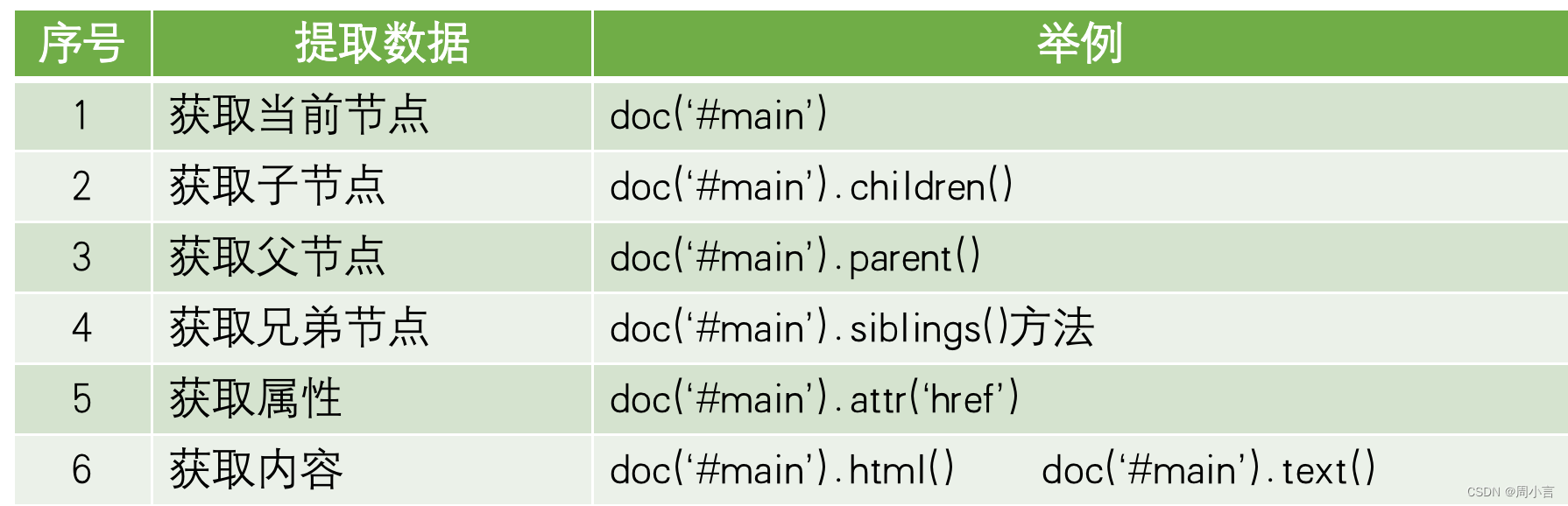
from pyquery import PyQuery
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<div id="main">
<a href="http://www.baidu.com">小周周</a.txt>
<h1>欢迎来到异世界</h1>
我是div中的文本
</div>
<h2>Python学习</h2>
</body>
</html>
'''
doc=PyQuery(html)
#获取当前节点
print(doc("#main"))
#获取父节点,子节点,兄弟节点
print('-----------父节点----------------')
print(doc("#main").parent())
print('-----------子节点----------------')
print(doc("#main").children())
print('-------------兄弟节点------------------')
print(doc("#main").siblings())
print('------------------获取属性---------------')
print(doc('a').attr('href'))
print('------------获取标签的内容----------------')
print(doc("#main").html())
print('-------------------------')
print(doc("#main").text())
run:
<div id="main">
<a href="http://www.baidu.com">小周周
<h1>欢迎来到异世界</h1>
我是div中的文本
</a></div>
-----------父节点----------------
<body>
<div id="main">
<a href="http://www.baidu.com">小周周
<h1>欢迎来到异世界</h1>
我是div中的文本
</a></div>
<h2>Python学习</h2>
</body>
-----------子节点----------------
<a href="http://www.baidu.com">小周周
<h1>欢迎来到异世界</h1>
我是div中的文本
</a>
-------------兄弟节点------------------
<h2>Python学习</h2>
------------------获取属性---------------
http://www.baidu.com
------------获取标签的内容----------------
<a href="http://www.baidu.com">小周周
<h1>欢迎来到异世界</h1>
我是div中的文本
</a>
-------------------------
小周周
欢迎来到异世界
我是div中的文本















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











