







CUDA学习:GPU硬件连接模型
一、基本的CPU与GPU连接模型

-
CPU与GPU之间的连接是通过PCI-Express总线进行连接的。GPU不是一个独立运行的平台而是CPU的协处理器。因此,GPU必须通过PCIe总线与基于CPU的主机相连来进行操作
- 一个典型的异构计算节点,如下所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kMCzj1kc-1657876706120)(ReferImage\典型的异构计算结点.png)]
- 一个典型的异构计算节点包括两个多核CPU插槽和两个或更多个的众核GPU。
- CPU中的多核指的是其中的算术逻辑单元(Arithmetic Logic Unit)。
- 多处理器指的是具有多个CPU
- 由存储器的层次结构可知,CPU直接与寄存器(Register)进行数据交换。由于主存读写数据的速度与CPU计算速度不在一个数量级,因此在主存(DRAM)和CPU寄存器之间存在着高速缓存(SRAM)来作为过渡。高速缓存通常被封装在CPU中。
-
CPU通过北桥来与主存通信并控制主存。
-
GPU通过对应的内存控制器来与显存进行通信并控制显存
二、多处理器(对称多处理器)连接模型

- 对称多处理器是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享一个地址空间(共享内存),并对所有资源具有同等访问权限
- 在对称多处理器系统中,所有处理器的地位都是相同的,所有的资源,特别是存储器,中断及I/O空间都具有相同的可访问性,消除了结构上的障碍
三、多处理器(非统一内存访问,NUMA)连接模型
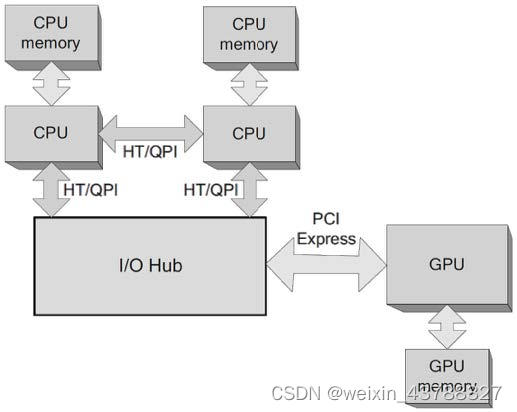
- 非统一内存访问的结构是多个统一内存访问体系结构通过总线互联在一起
- 某个节点的处理器可以直接访问到其他节点的全局地址内存,但是某个节点的处理器访问其他节点的全局地址内存的访问时间会慢于其访问本地节点的全局地址内存,因此这种体系结构叫做非统一内存访问。
- 多处理器共用一个I/O端口
四、多处理器(集成PCIe总线)连接模型
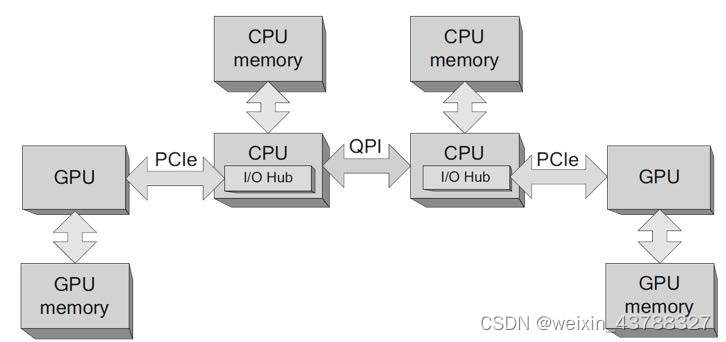
- I/O端口直接集成在CPU中,不同CPU使用不同的I/O端口。
- CPU与CPU之间可以进行通信
五、集成GPU连接模型
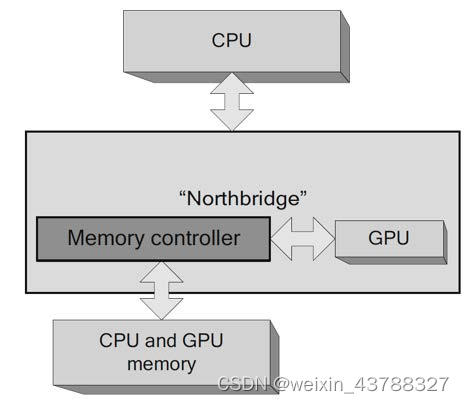
- 集成显卡
六、集显与独显综合的连接模型

- 独显存在自己独立的显存
七、多插槽GPU连接模型
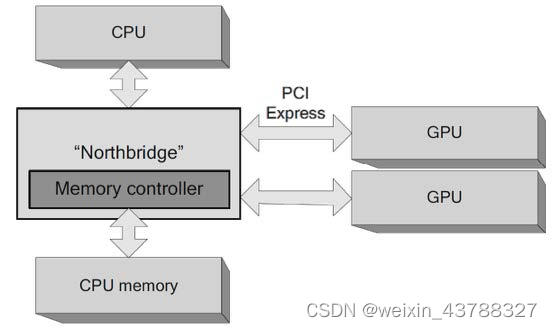
- 每块GPU存在自己独立的显存
- GPU与GPU之间的通信需要占用主板的PCIe总线资源
八、Multi-GPU board连接模型
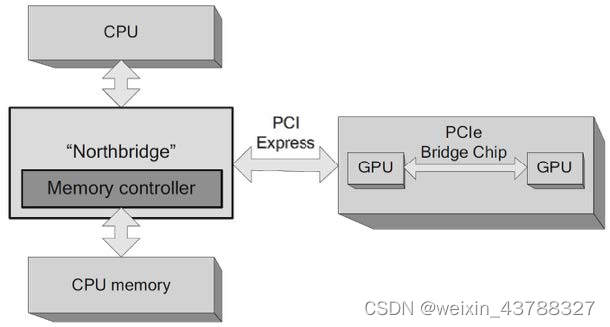
- GPU与GPU之间的通信不需要占用主板的PCIe总线资源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8601
8601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









