







数据集介绍
数据集代码可以看博客:验证码图片生成
图像数据集为10000张验证码图片,图片每次为验证码内容加数字(后面加入0-10000的数字是为了防止出现一样的验证码):



数据集读取
读取文件使用os模块:
from os import listdir
pics = listdir('./data')
for i in pics:
print(i)
接下来需要加上路径,这样一会处理的话就可以直接读取每张图片:
dirs = []
pics = listdir('./data')
for i in pics:
path = './data/' + i
dirs.append(path)
print(dirs)

图片读取功能完成了。
使用onehot编码
首先验证码范围为(0-9,a-z,A-Z),这些装入列表中:
captcha_array = list(string.ascii_letters + string.digits)
图片类型为./data/00Ei_2196.png,需要获取其中的00Ei,我将使用正则表达式:
import re
name = re.search(r'data/(.*?)_', dirs[0])
print(name.group(1))

后续为转为数字(就是每个符号在符号列表的位置):
for i in name.group(1):
x.append(captcha_array.index(i))
print(x)

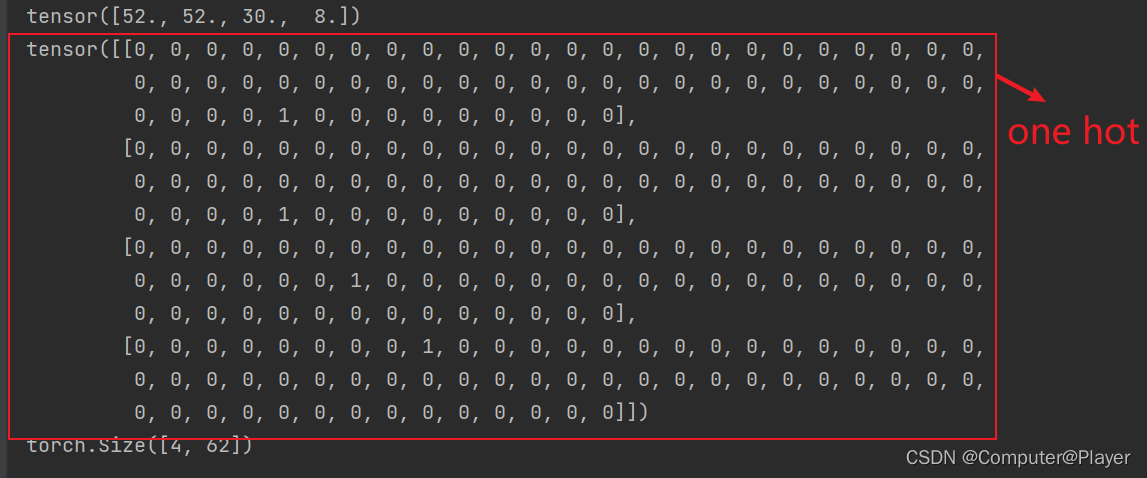
转为one hot编码:
print(x)
x = torch.Tensor(x)
print(x)
y = F.one_hot(x.to(torch.int64), len(captcha_array))
print(y)
print(y.shape)
数据集读取和数据转为one hot封装:
dataset.py
import torch
import torch.nn.functional as F
import string
from os import listdir
import re
import os
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class my_dataset(Dataset):
def __init__(self, dir):
super(my_dataset, self).__init__()
pics = listdir('./data')
self.paths = [os.path.join(dir, image_name) for image_name in pics]
self.transforms = transforms.Compose(
[
transforms.ToTensor(), # 转为tensor类型
]
)
self.captcha_array = list(string.ascii_letters + string.digits)
self.url = dir
def __len__(self):
return self.paths.__len__()
def __getitem__(self, index):
path = self.paths[index]
image = Image.open(path).convert("RGB")
data = self.transforms(image)
label = re.search(rf'{self.url}(.*?)_', path).group(1)
x = list()
for i in label:
x.append(self.captcha_array.index(i))
x = torch.Tensor(x)
label = F.one_hot(x.to(torch.int64), len(self.captcha_array))
return data, label
if __name__ == '__main__':
train_data = my_dataset("./data/")
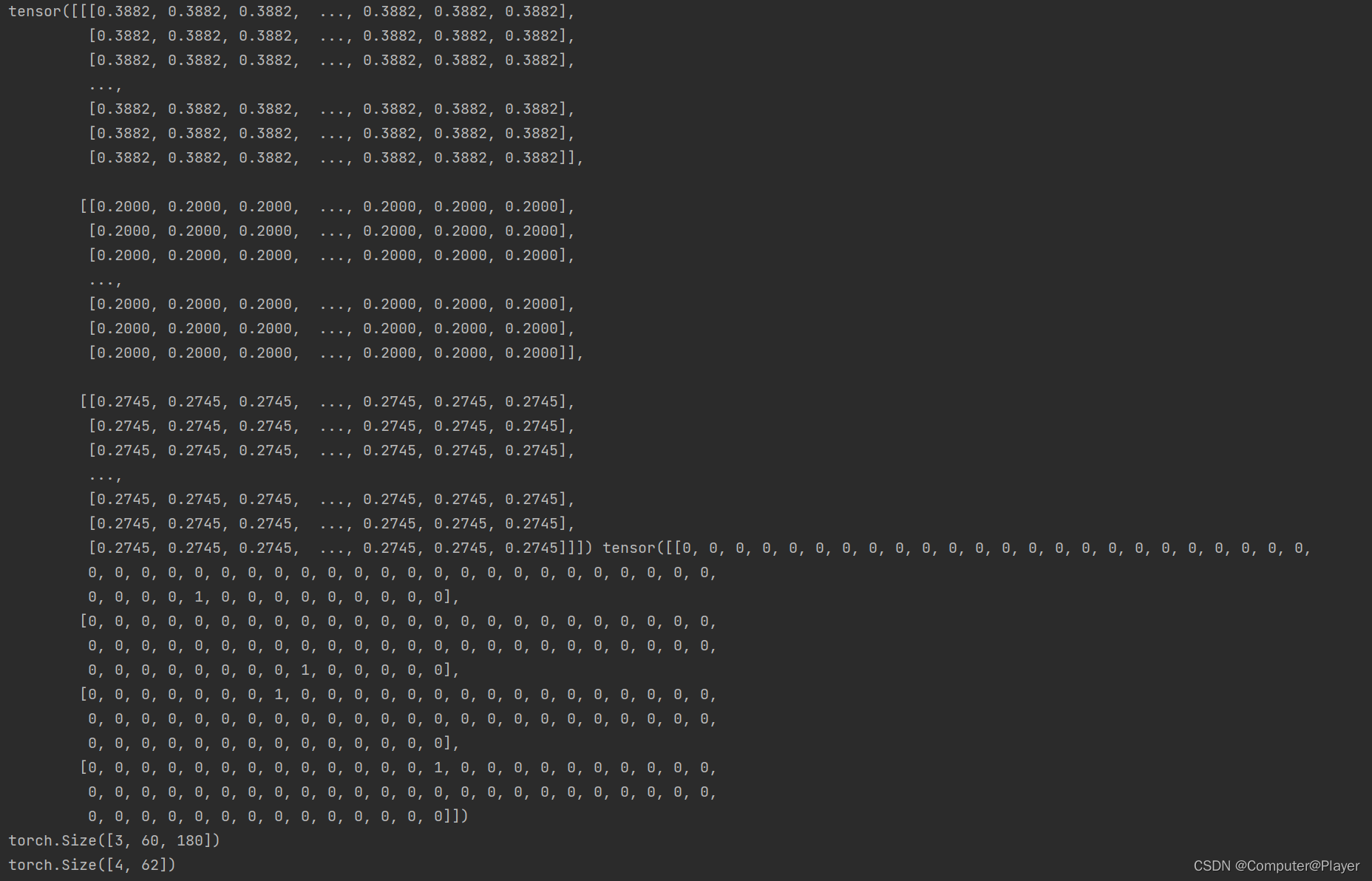
data, label = train_data[8]
print(data, label)
print(data.shape)
print(label.shape)
编写神经网络
model_one.py
import torch
from torch import nn
from dataset import my_dataset
from torch.utils.data import DataLoader
from torch import nn
from torch.optim import Adam
import time
import tqdm
class mymodel(nn.Module):
def __init__(self):
super(mymodel, self).__init__()
self.layer1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)#[64, 64, 30, 90]
)
self.layer2=nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer3 = nn.Sequential(
nn.Flatten(),#[6, 2560] [64, 15360]
nn.Linear(in_features=86400,out_features=4096),
nn.Dropout(0.2), # drop 20% of the neuron
nn.ReLU(),
nn.Linear(in_features=4096, out_features=62 * 4)
)
def forward(self,x):
x=self.layer1(x)
#print('layer1:',x.shape)
x=self.layer2(x)
#print('layer2:', x.shape)
x=self.layer3(x)
#print('layer3:', x.shape)
x = x.view(x.size(0), -1)
return x;
训练:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import my_datasets
from model import mymodel
if __name__ == '__main__':
train_datas= my_datasets.mydatasets("./dataset/train")
test_data= my_datasets.mydatasets("./dataset/test")
train_dataloader=DataLoader(train_datas,batch_size=64,shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
writer=SummaryWriter("logs")
m=mymodel().cuda()
loss_fn=nn.MultiLabelSoftMarginLoss().cuda()
optimizer = torch.optim.Adam(m.parameters(), lr=0.001)
w=SummaryWriter("logs")
total_step=0
for i in range(10):
for i,(imgs,targets) in enumerate(train_dataloader):
imgs=imgs.cuda()
targets=targets.cuda()
# print(imgs.shape)
# print(targets.shape)
outputs=m(imgs)
# print(outputs.shape)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.close()
torch.save(m,"model.pth")
测试
我的测试集是5000张验证码图片
from tqdm import tqdm
from dataset import my_dataset
from torch.utils.data import DataLoader
import torch
import string
captcha_array = list(string.ascii_letters + string.digits)
def Text(vec):
"""
将onehot编码转为标注文本
:return text
"""
text = ""
for i in vec:
text += captcha_array[i]
return text
if __name__ == '__main__':
test_dataset = my_dataset("./ce/")
# print(test_dataset[0])
test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=True)
# 定义网络
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#cnn.pth Verification_resnet34_4w.pth
model = torch.load("cnn.pth").cuda(device)
total = len(test_dataset)
yuce = 0
bar = tqdm(enumerate(test_dataloader), total=len(test_dataloader))
for i, (images, labels) in bar:
images = images.cuda(0)
labels = labels.cuda(0)
outputs = model(images)
# outputs = outputs.reshape(1, 4, 62)
outputs = outputs.view(-1, 62)
labels = labels.view(-1, 62)
pred = torch.max(outputs, 1)[1].cpu().detach().numpy()
labels = torch.max(labels, 1)[1].cpu().detach().numpy()
pre = Text(pred)
label = Text(labels)
if pre == label:
yuce += 1
print(pre, label)
else:
# print(pred, labels)
pass
print("正确率: {}%".format(yuce / total * 100))
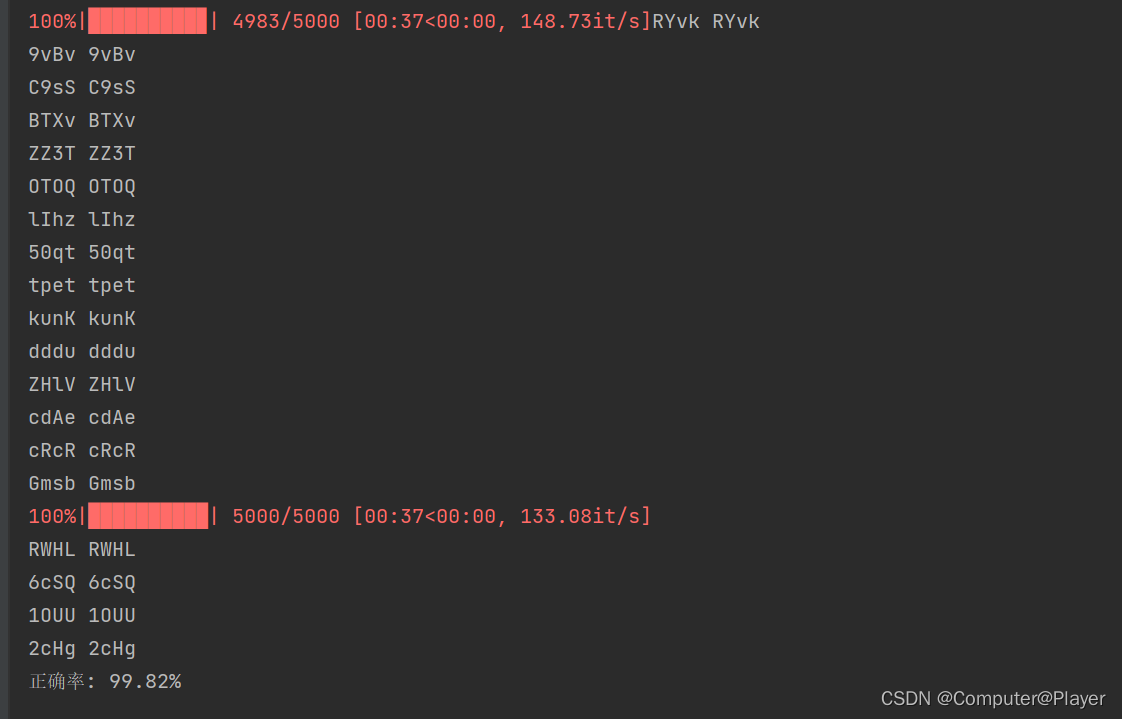
准确率为99.82%,可以效果非常好了。
同时还有一个方法,深度残差网络(ResNet),我是直接调用库里的:
import torch
import time
from tqdm import tqdm
from dataset import my_dataset
from torch.utils.data import DataLoader
from torch import nn
from torch.optim import Adam
import torchvision.models as models
if __name__ == '__main__':
train_dataset = my_dataset("./data/")
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True, drop_last=True, num_workers=4)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
verification = models.resnet34(num_classes=4 * 62).cuda(device)
loss_fn = nn.MSELoss().cuda(device)
optim = Adam(verification.parameters(), lr=0.001)
verification.train()
for epoch in range(50):
now = time.time()
bar = tqdm(enumerate(train_dataloader), total=len(train_dataloader))
for i, (images, labels) in bar:
optim.zero_grad()
images = images.cuda(device)
labels = labels.cuda(device)
outputs = verification(images)
outputs = outputs.reshape(64, 4, 62)
labels = labels.to(torch.float)
loss = loss_fn(outputs, labels)
loss.backward()
optim.step()
torch.save(verification, "resnet34_4w.pth")
print("训练epoch次数{}".format(epoch + 1))
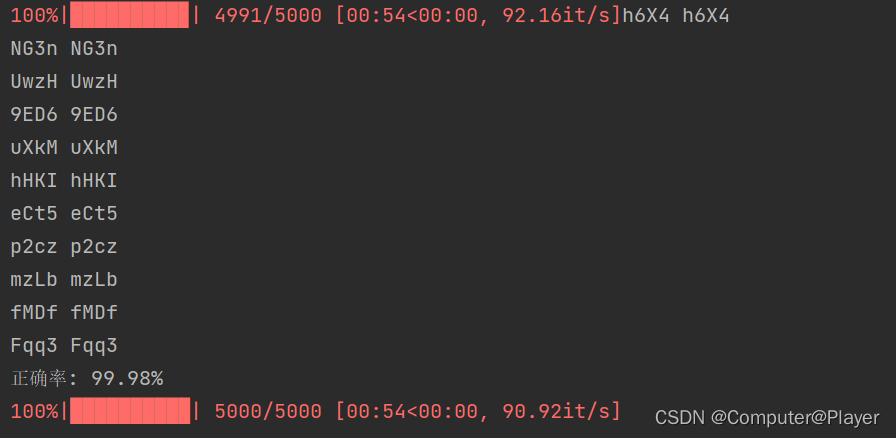
准确率也是极高的:

















 2799
2799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











