







本文以干豆数据集为例,数据集下载位置如下:干豆数据集
import pandas as pd
import sklearn
import numpy as np
数据读取与预处理
dry = pd.read_csv("Dry_Bean.csv")
在info返回的信息中的non-null也能看出数据集不存在缺失值。
dry.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13611 entries, 0 to 13610
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 13611 non-null int64
1 Perimeter 13611 non-null float64
2 MajorAxisLength 13611 non-null float64
3 MinorAxisLength 13611 non-null float64
4 AspectRation 13611 non-null float64
5 Eccentricity 13611 non-null float64
6 ConvexArea 13611 non-null int64
7 EquivDiameter 13611 non-null float64
8 Extent 13611 non-null float64
9 Solidity 13611 non-null float64
10 roundness 13611 non-null float64
11 Compactness 13611 non-null float64
12 ShapeFactor1 13611 non-null float64
13 ShapeFactor2 13611 non-null float64
14 ShapeFactor3 13611 non-null float64
15 ShapeFactor4 13611 non-null float64
16 Class 13611 non-null object
dtypes: float64(14), int64(2), object(1)
memory usage: 1.8+ MB
dry.head()
| Area | Perimeter | MajorAxisLength | MinorAxisLength | AspectRation | Eccentricity | ConvexArea | EquivDiameter | Extent | Solidity | roundness | Compactness | ShapeFactor1 | ShapeFactor2 | ShapeFactor3 | ShapeFactor4 | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 28395 | 610.291 | 208.178117 | 173.888747 | 1.197191 | 0.549812 | 28715 | 190.141097 | 0.763923 | 0.988856 | 0.958027 | 0.913358 | 0.007332 | 0.003147 | 0.834222 | 0.998724 | SEKER |
| 1 | 28734 | 638.018 | 200.524796 | 182.734419 | 1.097356 | 0.411785 | 29172 | 191.272751 | 0.783968 | 0.984986 | 0.887034 | 0.953861 | 0.006979 | 0.003564 | 0.909851 | 0.998430 | SEKER |
| 2 | 29380 | 624.110 | 212.826130 | 175.931143 | 1.209713 | 0.562727 | 29690 | 193.410904 | 0.778113 | 0.989559 | 0.947849 | 0.908774 | 0.007244 | 0.003048 | 0.825871 | 0.999066 | SEKER |
| 3 | 30008 | 645.884 | 210.557999 | 182.516516 | 1.153638 | 0.498616 | 30724 | 195.467062 | 0.782681 | 0.976696 | 0.903936 | 0.928329 | 0.007017 | 0.003215 | 0.861794 | 0.994199 | SEKER |
| 4 | 30140 | 620.134 | 201.847882 | 190.279279 | 1.060798 | 0.333680 | 30417 | 195.896503 | 0.773098 | 0.990893 | 0.984877 | 0.970516 | 0.006697 | 0.003665 | 0.941900 | 0.999166 | SEKER |
dry["Class"].unique()
array(['SEKER', 'BARBUNYA', 'BOMBAY', 'CALI', 'HOROZ', 'SIRA', 'DERMASON'],
dtype=object)
dry["Class"].nunique()
7
dry.columns
Index(['Area', 'Perimeter', 'MajorAxisLength', 'MinorAxisLength',
'AspectRation', 'Eccentricity', 'ConvexArea', 'EquivDiameter', 'Extent',
'Solidity', 'roundness', 'Compactness', 'ShapeFactor1', 'ShapeFactor2',
'ShapeFactor3', 'ShapeFactor4', 'Class'],
dtype='object')
dry.index
RangeIndex(start=0, stop=13611, step=1)
重复值检查
dry.duplicated().sum()
68
数据缺失值检验
dry.isnull().sum()
Area 0
Perimeter 0
MajorAxisLength 0
MinorAxisLength 0
AspectRation 0
Eccentricity 0
ConvexArea 0
EquivDiameter 0
Extent 0
Solidity 0
roundness 0
Compactness 0
ShapeFactor1 0
ShapeFactor2 0
ShapeFactor3 0
ShapeFactor4 0
Class 0
dtype: int64
我们也可以通过定义如下函数来输出更加完整的每一列缺失值的数值和占比
def missing (df):
"""
计算每一列的缺失值及占比
"""
missing_number = df.isnull().sum().sort_values(ascending=False) # 每一列的缺失值求和后降序排序
missing_percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False) # 每一列缺失值占比
missing_values = pd.concat([missing_number, missing_percent], axis=1, keys=['Missing_Number', 'Missing_Percent']) # 合并为一个DataFrame
return missing_values
missing(dry)
| Missing_Number | Missing_Percent | |
|---|---|---|
| Area | 0 | 0.0 |
| Solidity | 0 | 0.0 |
| ShapeFactor4 | 0 | 0.0 |
| ShapeFactor3 | 0 | 0.0 |
| ShapeFactor2 | 0 | 0.0 |
| ShapeFactor1 | 0 | 0.0 |
| Compactness | 0 | 0.0 |
| roundness | 0 | 0.0 |
| Extent | 0 | 0.0 |
| Perimeter | 0 | 0.0 |
| EquivDiameter | 0 | 0.0 |
| ConvexArea | 0 | 0.0 |
| Eccentricity | 0 | 0.0 |
| AspectRation | 0 | 0.0 |
| MinorAxisLength | 0 | 0.0 |
| MajorAxisLength | 0 | 0.0 |
| Class | 0 | 0.0 |
dry.describe()
| Area | Perimeter | MajorAxisLength | MinorAxisLength | AspectRation | Eccentricity | ConvexArea | EquivDiameter | Extent | Solidity | roundness | Compactness | ShapeFactor1 | ShapeFactor2 | ShapeFactor3 | ShapeFactor4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 | 13611.000000 |
| mean | 53048.284549 | 855.283459 | 320.141867 | 202.270714 | 1.583242 | 0.750895 | 53768.200206 | 253.064220 | 0.749733 | 0.987143 | 0.873282 | 0.799864 | 0.006564 | 0.001716 | 0.643590 | 0.995063 |
| std | 29324.095717 | 214.289696 | 85.694186 | 44.970091 | 0.246678 | 0.092002 | 29774.915817 | 59.177120 | 0.049086 | 0.004660 | 0.059520 | 0.061713 | 0.001128 | 0.000596 | 0.098996 | 0.004366 |
| min | 20420.000000 | 524.736000 | 183.601165 | 122.512653 | 1.024868 | 0.218951 | 20684.000000 | 161.243764 | 0.555315 | 0.919246 | 0.489618 | 0.640577 | 0.002778 | 0.000564 | 0.410339 | 0.947687 |
| 25% | 36328.000000 | 703.523500 | 253.303633 | 175.848170 | 1.432307 | 0.715928 | 36714.500000 | 215.068003 | 0.718634 | 0.985670 | 0.832096 | 0.762469 | 0.005900 | 0.001154 | 0.581359 | 0.993703 |
| 50% | 44652.000000 | 794.941000 | 296.883367 | 192.431733 | 1.551124 | 0.764441 | 45178.000000 | 238.438026 | 0.759859 | 0.988283 | 0.883157 | 0.801277 | 0.006645 | 0.001694 | 0.642044 | 0.996386 |
| 75% | 61332.000000 | 977.213000 | 376.495012 | 217.031741 | 1.707109 | 0.810466 | 62294.000000 | 279.446467 | 0.786851 | 0.990013 | 0.916869 | 0.834270 | 0.007271 | 0.002170 | 0.696006 | 0.997883 |
| max | 254616.000000 | 1985.370000 | 738.860154 | 460.198497 | 2.430306 | 0.911423 | 263261.000000 | 569.374358 | 0.866195 | 0.994677 | 0.990685 | 0.987303 | 0.010451 | 0.003665 | 0.974767 | 0.999733 |
dry.groupby("Class").mean()
| Area | Perimeter | MajorAxisLength | MinorAxisLength | AspectRation | Eccentricity | ConvexArea | EquivDiameter | Extent | Solidity | roundness | Compactness | ShapeFactor1 | ShapeFactor2 | ShapeFactor3 | ShapeFactor4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | ||||||||||||||||
| BARBUNYA | 69804.133132 | 1046.105764 | 370.044279 | 240.309352 | 1.544395 | 0.754665 | 71025.729198 | 297.311018 | 0.749273 | 0.982804 | 0.800200 | 0.805001 | 0.005357 | 0.001394 | 0.649144 | 0.995739 |
| BOMBAY | 173485.059387 | 1585.619079 | 593.152075 | 374.352547 | 1.585550 | 0.770518 | 175813.116858 | 468.941426 | 0.776559 | 0.986902 | 0.864421 | 0.792622 | 0.003442 | 0.000844 | 0.629195 | 0.991841 |
| CALI | 75538.211043 | 1057.634282 | 409.499538 | 236.370616 | 1.733663 | 0.814804 | 76688.503067 | 309.535280 | 0.758953 | 0.985021 | 0.845934 | 0.756703 | 0.005459 | 0.001107 | 0.573022 | 0.990584 |
| DERMASON | 32118.710942 | 665.209536 | 246.557279 | 165.657143 | 1.490471 | 0.736632 | 32498.435138 | 201.683813 | 0.752953 | 0.988226 | 0.908114 | 0.819110 | 0.007755 | 0.002161 | 0.671636 | 0.996914 |
| HOROZ | 53648.508817 | 919.859676 | 372.570290 | 184.170663 | 2.026119 | 0.867443 | 54440.091805 | 260.730715 | 0.706393 | 0.985480 | 0.794420 | 0.700880 | 0.007007 | 0.001048 | 0.491791 | 0.991926 |
| SEKER | 39881.299951 | 727.672440 | 251.291957 | 201.909653 | 1.245182 | 0.584781 | 40269.567341 | 224.948441 | 0.771674 | 0.990351 | 0.944508 | 0.896841 | 0.006334 | 0.002541 | 0.805149 | 0.998383 |
| SIRA | 44729.128604 | 796.418737 | 299.380258 | 190.800250 | 1.570083 | 0.767277 | 45273.099772 | 238.335316 | 0.749445 | 0.987971 | 0.884652 | 0.797345 | 0.006720 | 0.001683 | 0.636358 | 0.995385 |
查看标签字段的取值分布情况
import seaborn as sns
import matplotlib.pyplot as plt
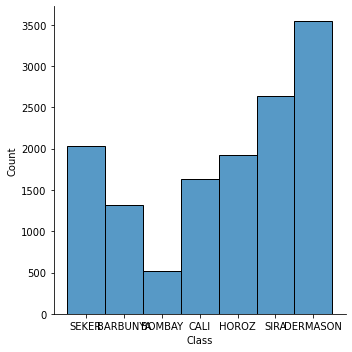
dry["Class"].value_counts()
DERMASON 3546
SIRA 2636
SEKER 2027
HOROZ 1928
CALI 1630
BARBUNYA 1322
BOMBAY 522
Name: Class, dtype: int64
sns.displot(dry['Class'])
数据标准化与归一化
当然,除了离散变量的重编码外,有的时候我们也需要对连续变量进行转化,以提升模型表现或模型训练效率。在之前的内容中我们曾介绍了关于连续变量标准化和归一化的相关内容,对连续变量而言,标准化可以消除量纲影响并且加快梯度下降的迭代效率,而归一化则能够对每条数据进行进行范数单位化处理,我们可以通过下面的内容进行标准化和归一化相关内容回顾。
标准化与归一化
从功能上划分,sklearn中的归一化其实是分为标准化(Standardization)和归一化(Normalization)两类。其中,此前所介绍的Z-Score标准化和0-1标准化,都属于Standardization的范畴,而在sklearn中,Normalization则特指针对单个样本(一行数据)利用其范数进行放缩的过程。不过二者都属于数据预处理范畴,都在sklearn中的Preprocessing data模块下。
需要注意的是,此前我们介绍数据归一化时有讨论过标准化和归一化名称上的区别,在大多数场景下其实我们并不会对其进行特意的区分,但sklearn中标准化和归一化则各指代一类数据处理方法,此处需要注意。
标准化 Standardization
sklearn的标准化过程,即包括Z-Score标准化,也包括0-1标准化,并且即可以通过实用函数来进行标准化处理,同时也可以利用评估器来执行标准化过程。接下来我们分不同功能以的不同实现形式来进行讨论:
- Z-Score标准化的评估器实现方法
实用函数进行标准化处理,尽管从代码实现角度来看清晰易懂,但却不适用于许多实际的机器学习建模场景。其一是因为在进行数据集的训练集和测试集切分后,我们首先要在训练集进行标准化、然后统计训练集上统计均值和方差再对测试集进行标准化处理,因此其实还需要一个统计训练集相关统计量的过程;其二则是因为相比实用函数,sklearn中的评估器其实会有一个非常便捷的串联的功能,sklearn中提供了Pipeline工具能够对多个评估器进行串联进而组成一个机器学习流,从而简化模型在重复调用时候所需代码量,因此通过评估器的方法进行数据标准化,其实是一种更加通用的选择。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit()
将特征和标签分开:
#.提取特征数据、标签数据
cols = [i for i in dry.columns if i not in ['Class']] #获取种特征名称,不包含标签
print(cols)
['Area', 'Perimeter', 'MajorAxisLength', 'MinorAxisLength', 'AspectRation', 'Eccentricity', 'ConvexArea', 'EquivDiameter', 'Extent', 'Solidity', 'roundness', 'Compactness', 'ShapeFactor1', 'ShapeFactor2', 'ShapeFactor3', 'ShapeFactor4']
data = dry[cols]
data.head()
| Area | Perimeter | MajorAxisLength | MinorAxisLength | AspectRation | Eccentricity | ConvexArea | EquivDiameter | Extent | Solidity | roundness | Compactness | ShapeFactor1 | ShapeFactor2 | ShapeFactor3 | ShapeFactor4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 28395 | 610.291 | 208.178117 | 173.888747 | 1.197191 | 0.549812 | 28715 | 190.141097 | 0.763923 | 0.988856 | 0.958027 | 0.913358 | 0.007332 | 0.003147 | 0.834222 | 0.998724 |
| 1 | 28734 | 638.018 | 200.524796 | 182.734419 | 1.097356 | 0.411785 | 29172 | 191.272751 | 0.783968 | 0.984986 | 0.887034 | 0.953861 | 0.006979 | 0.003564 | 0.909851 | 0.998430 |
| 2 | 29380 | 624.110 | 212.826130 | 175.931143 | 1.209713 | 0.562727 | 29690 | 193.410904 | 0.778113 | 0.989559 | 0.947849 | 0.908774 | 0.007244 | 0.003048 | 0.825871 | 0.999066 |
| 3 | 30008 | 645.884 | 210.557999 | 182.516516 | 1.153638 | 0.498616 | 30724 | 195.467062 | 0.782681 | 0.976696 | 0.903936 | 0.928329 | 0.007017 | 0.003215 | 0.861794 | 0.994199 |
| 4 | 30140 | 620.134 | 201.847882 | 190.279279 | 1.060798 | 0.333680 | 30417 | 195.896503 | 0.773098 | 0.990893 | 0.984877 | 0.970516 | 0.006697 | 0.003665 | 0.941900 | 0.999166 |
target = dry["Class"]
target.head()
0 SEKER
1 SEKER
2 SEKER
3 SEKER
4 SEKER
Name: Class, dtype: object
data_Standard = scaler.fit_transform(data)
data_Standard
array([[-0.84074853, -1.1433189 , -1.30659814, ..., 2.4021726 ,
1.92572347, 0.83837102],
[-0.82918764, -1.01392388, -1.39591111, ..., 3.10089364,
2.68970162, 0.77113831],
[-0.80715717, -1.07882906, -1.25235661, ..., 2.23509111,
1.84135576, 0.91675506],
...,
[-0.37203825, -0.44783294, -0.45047814, ..., 0.28920501,
0.33632829, 0.39025106],
[-0.37176543, -0.42702856, -0.42897404, ..., 0.22837456,
0.2489734 , 0.03644007],
[-0.37135619, -0.38755718, -0.2917356 , ..., -0.12777538,
-0.27648141, 0.71371941]])
from sklearn.preprocessing import Normalizer
normlize = Normalizer()
data_normlize.fit_transform(data)
















 3998
3998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











