









1导入波士顿房价数据
通过sklearn模块自带的数据集,导入波士顿房价数据。以4:1的比例划分出训练集和测试集,特征和标签数据
# 加载数据
def load_data():
X, y = load_boston(return_X_y=True)
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=0)
x_train_pd = pd.DataFrame(x_train)
y_train_pd = pd.DataFrame(y_train)
x_valid_pd = pd.DataFrame(x_valid)
y_valid_pd = pd.DataFrame(y_valid)
return x_train_pd, y_train_pd, x_valid_pd, y_valid_pd
2数据归一化处理
对数据做MinMaxScale归一化操作,统一数据之间的量纲,使得数据能够分布到同一域中
def norm_data(x_train_pd, y_train_pd, x_valid_pd, y_valid_pd):
# 训练集归一化
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(x_train_pd)
x_train = min_max_scaler.transform(x_train_pd)
min_max_scaler.fit(y_train_pd)
y_train = min_max_scaler.transform(y_train_pd)
min_max_scaler.fit(x_valid_pd)
x_valid = min_max_scaler.transform(x_valid_pd)
min_max_scaler.fit(y_valid_pd)
y_valid = min_max_scaler.transform(y_valid_pd)
return x_train, y_train, x_valid, y_valid
3构造MLP神经网络模型
初始化输入层、隐藏层、输出层,定义FFN计算过程
class MLPModule(nn.Module):
def __init__(self, input_size, hidden_size, output_size, device=torch.device('cpu')):
super(MLPModule, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
self.droupout = nn.Dropout(0.2)
self.relu = nn.ReLU()
self.device = device
def forward(self, x):
x = x.to(self.device)
x = self.linear1(x)
x = self.relu(x)
x = self.droupout(x)
x = self.relu(x)
x = self.linear2(x)
return x
4定义训练函数
将前面的步骤整合到一起,导入数据,预处理数据,载入模型,迭代训练,前向传播,计算损失,方向传播,优化处理
def train():
x_train, y_train, x_valid, y_valid = data_loader()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义模型
model = MLPModule(13, 100, 1, device)
model = model.to(device)
# 定义损失函数
loss_fn = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_ls = []
# 训练
for epoch in range(100):
x_train = torch.tensor(x_train).to(device)
x_train = x_train.float()
y_train = torch.tensor(y_train).to(device)
y_train = y_train.float()
# 前向传播
y_pred = model(x_train)
# 计算损失
loss = loss_fn(y_pred, y_train)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch: {}, loss: {}'.format(epoch, loss.item()))
loss_ls.append(loss.item())
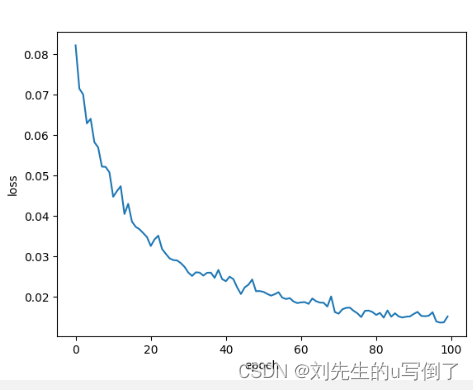
5绘制训练过程图
通过每一次迭代的损失记录,绘制模型训练的过程图
def draw(epoch, loss):
plt.plot(epoch, loss)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
6验证模型
导入训练好的模型,验证模型的泛化性能
# 测试
def test():
x_train, y_train, x_valid, y_valid = data_loader()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load('model.pth')
model.to(device)
x_valid = torch.tensor(x_valid)
x_valid = x_valid.float()
x_valid = x_valid.to(device)
y_valid = torch.tensor(y_valid)
y_valid = y_valid.float()
y_valid = y_valid.to(device)
y_pred = model(x_valid)
y_pred = y_pred.to(device)
loss_fn = nn.MSELoss()
loss = loss_fn(y_pred, y_valid)
print('test loss: {}'.format(loss.item()))
















 5666
5666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











