







目录
fio工具参数解释
–filename
待测试的文件或块设备
若为文件,则代表测试文件系统的性能;例:–filename=/opt/test.img 若为块设备,则代表测试裸设备的性能; 例:–filename=/dev/sda
–bs
单次IO的块大小(测试磁盘的io,尽量使用小文件)
–ioengine
采用的文件读写方式
-
–sync:采用read,write,使用fseek定位读写位置。
-
–psync:采用pread、pwrite进行文件读写操作
-
–vsync:采用readv(2) orwritev(2)进行文件读写操作
read()和write()系统调用每次在文件和进程的地址空间之间传送一块连续的数据。但是,应用有时也需要将分散在内存多处地方的数据连续写到文件中,或者反之。在这种情况下,如果要从文件中读一片连续的数据至进程的不同区域,使用read()则要么一次将它们读至一个较大的缓冲区中,然后将它们分成若干部分复制到不同的区域,要么调用read()若干次分批将它们读至不同区域。同样,如果想将程序中不同区域的数据块连续地写至文件,也必须进行类似的处理。UNIX提供了另外两个函数—readv()和writev(),它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。readv()称为散布读,即将文件中若干连续的数据块读入内存分散的缓冲区中。writev()称为聚集写,即收集内存中分散的若干缓冲区中的数据写至文件的连续区域中。
-
–libaio:Linux异步读写IO(Linuxnative asynchronous I/O)
-
–posixaio: glibc POSIX 异步IO读写,使用aio_read(3)and aio_write(3)实现IO读写。
–rw
读写模式。
-
read:顺序读测试,使用方式–rw=read
-
write:顺序写测试,使用方式–rw=write
-
randread:随机读测试,使用方式–rw=randread
-
randwrite:随机写测试,使用方式–rw=randwrite
-
randrw:随机读写,–rw=randrw;默认比率为5:5,通过参数–rwmixread设定读的比率,如–rw=randrw-rwmixread=70,说明读写比率为70:30。或rwmixwrite
–time_based
如果设置的job已被完全读写或写完,也会执行完runtime规定的时间。它是通过循环执行相同的负载来实现的。加上这个参数可以防止job提前结束。
–refill_buffers
每次提交后都重复填充io buffer
–norandommap
在进行随机 I/O 时,FIO 将覆盖文件的每个块。若给出此参数,则将选择新的偏移量而不查看 I/O 历史记录。
–group_reporting
关于显示结果的,汇总每个进程的信息
–name
测试结果输出的文件名称
–size
测试的文件大小
– nrfiles
每个进程生成的文件数量
– zero_buffers
用0初始化系统buffer
– randrepeat
随机序列是否可重复,True(1)表示随机序列可重复,False(0)表示随机序列不可重复。默认为 True(1)。
– sync
设置同步模式,同步–sync=1,异步–sync=0
– fsync
设置数据同步模式,同步-fsync=1,异步-fsync=0(有一个io就同步)
– numjobs
测试进程的并发数,默认为16(这个值和cpu数量有关)
Glusterfs 和NFS 性能测试
顺序写:
fio --filename=/mnt/test-volume/sunwenbo-testing --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=write --time_based --runtime=600 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randwrite-iops --size=10G 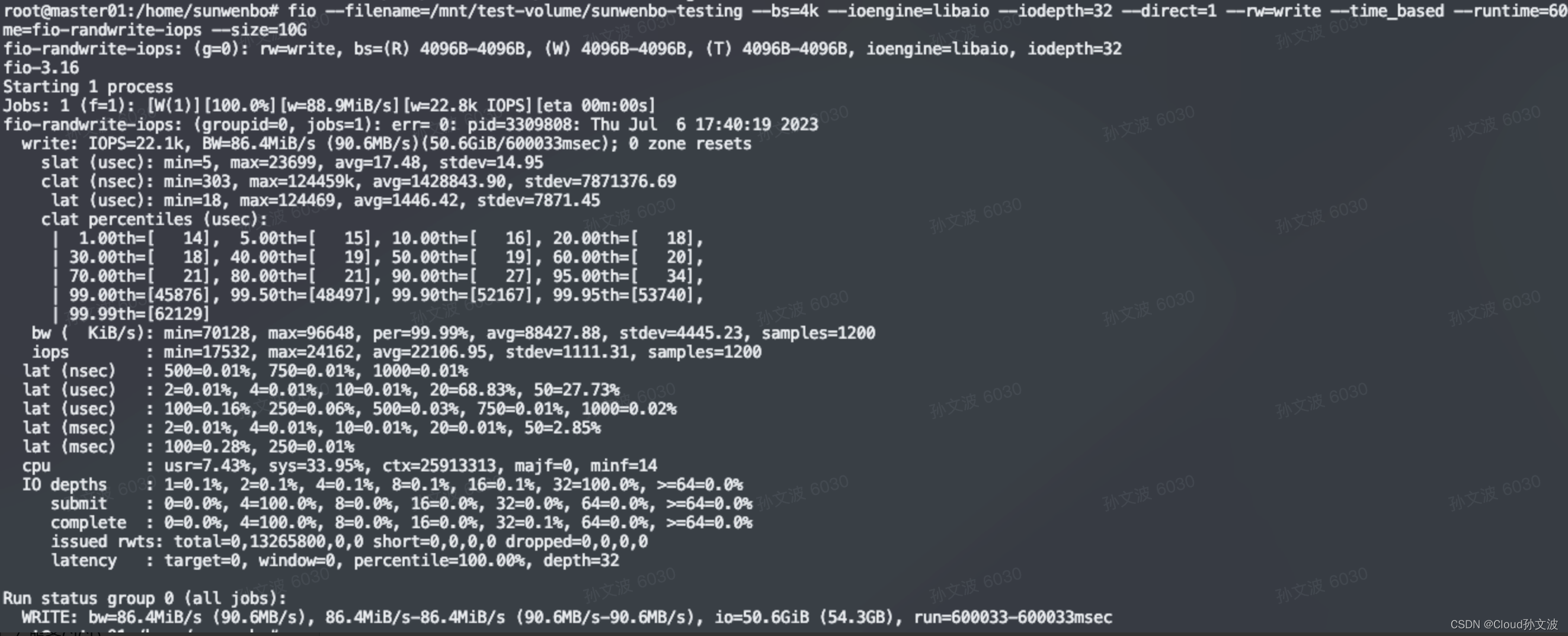
随机写:
fio --filename=/mnt/test-volume/sunwenbo-testing --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=randwrite --time_based --runtime=200 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randwrite-iops --size=10G 
顺序读:
fio --filename=/mnt/test-volume/sunwenbo-testing --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=read --time_based --runtime=600 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randwrite-iops --size=10G随机读:
fio --filename=/mnt/test-volume/sunwenbo-testing --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=randread --time_based --runtime=200 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randread-iops --size=10G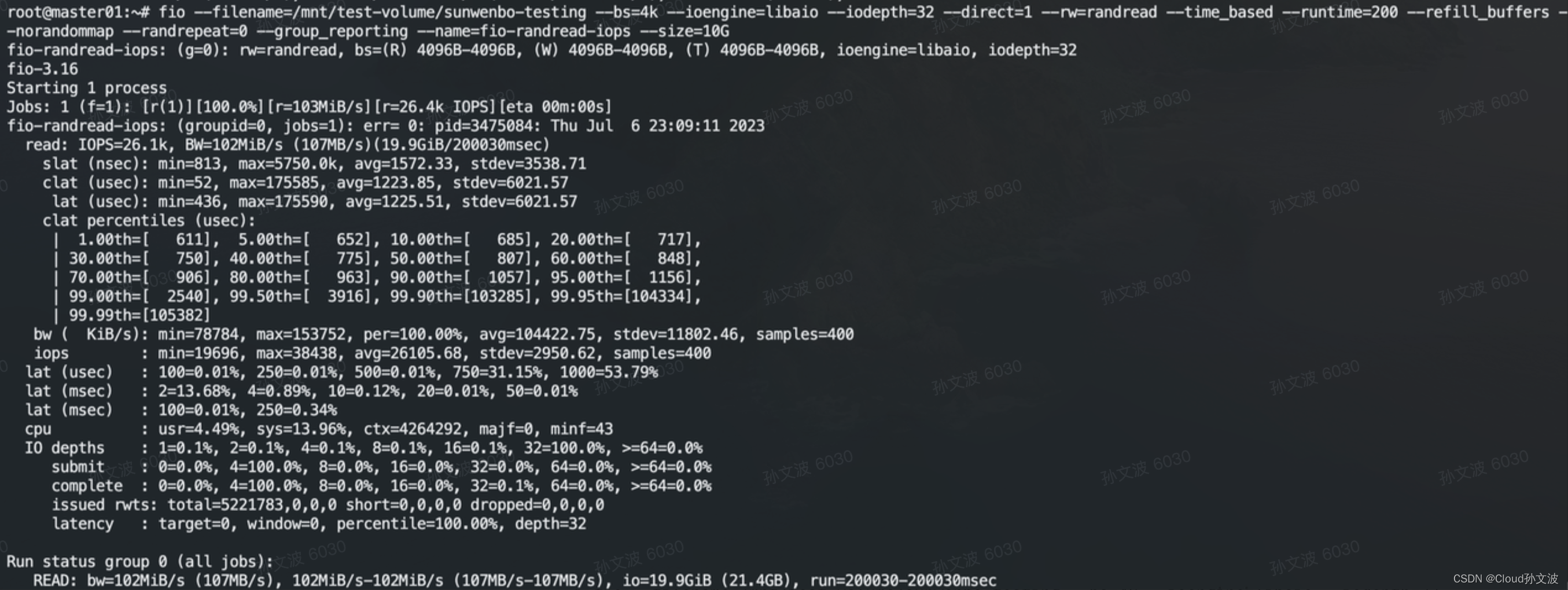
随机读写:
fio --filename=/mnt/test-volume/sunwenbo-testing --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=randrw --time_based --runtime=300 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randwriteread-iops --size=10G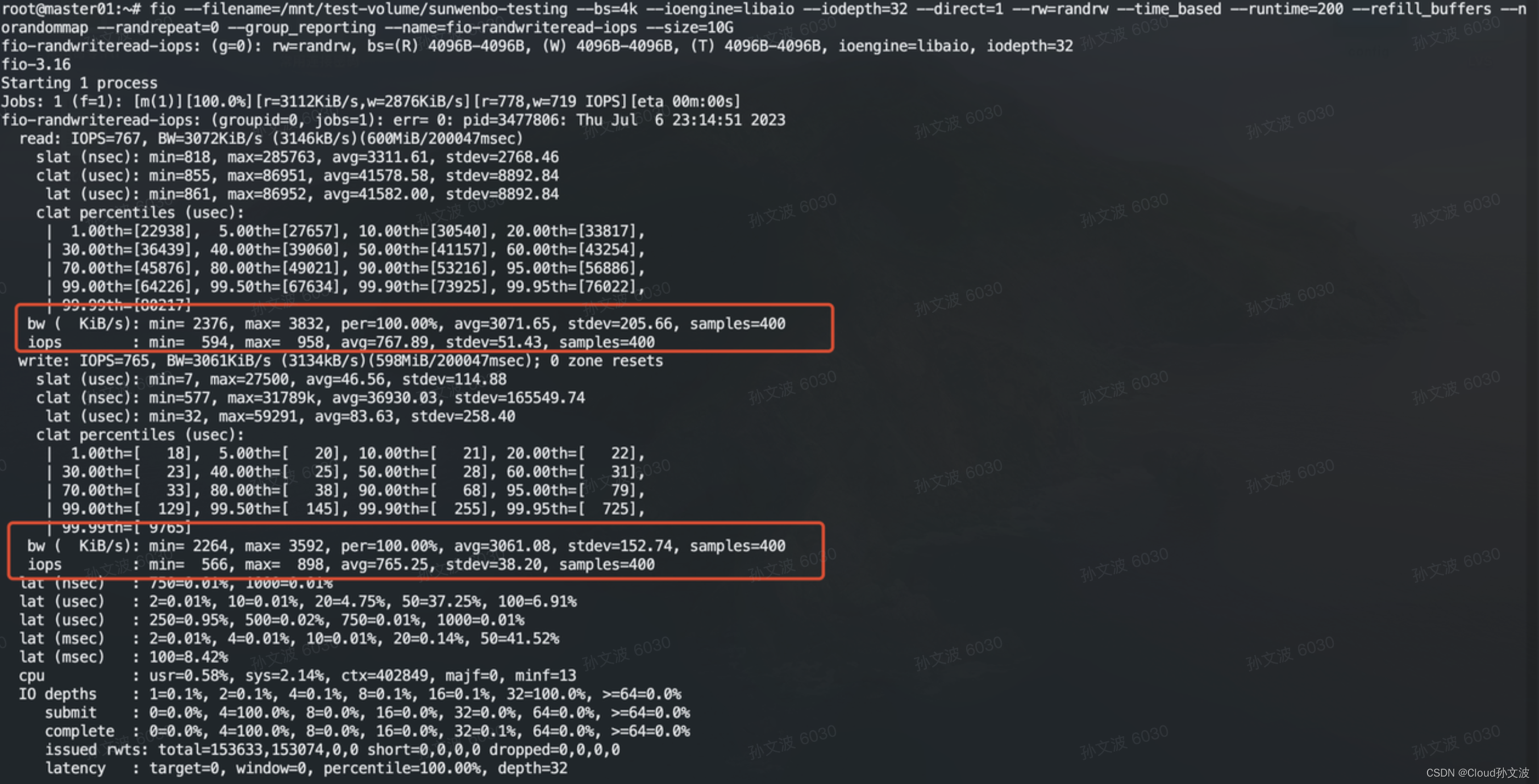
参数说明:
bs:单次io的块文件大小为4k
size:本次的测试文件大小为10G,以每次4k的io进行测试。
runtime:测试时间 秒
rw:顺序写/读 随机读/写 随机读写
direct:=1 测试过程绕过机器自带的buffer。使测试结果更真实。
ioengine: =libaio Linux异步读写IO
iodepth:队列深度,只有使用libaio时才有意义。这是一个可以影响IOPS的参数。
numjobs: 测试进程的并发数,默认为16(这个值和cpu数量有关)
| bs | 4k | 8k | 32k | 64k | 256k | 1024k |
|---|---|---|---|---|---|---|
| 顺序写 iops/bw | 22938/91753 | 11301/90513 | 2819/90223 | 1411/90363 | 352.15/90154 | 87.76/89919 |
| 随机写 iops/bw | 1200/4802 | 1156/9251 | 1003/32116 | 825/52826 | 328/83997 | 87.87/90029 |
| 顺序读 iops/bw | 26035/104140 | 26017/208140 | 8356/267403 | 4177/267387 | 1044/267401 | 261/267285 |
| 随机读 iops/bw | 26105/104422 | 26222/209779 | 8390/268495 | 4193/268390 | 1055/270179 | 266/272840 |
| 随机读写 iops/bw | read:767/3071 write: 765/3061 | 717/5754 719/5758 | 589.22/18856 586/18775 | 465/29776 481/30839 | 182.79/46838 197/49789 | 55/57018 56/57953 |
测试结论:
顺序写:随着bs越大,iops每秒的读写次数越少。bw没有太大变化
随机写:随着bs越大,iops每秒的读写次数越少。bw增长一倍
顺序读:随着bs越大,iops每秒的读写次数越少。bw在bs 4k - 32k的情况下增长比较明显 32k以上达到了一定的瓶颈
随机读:随着bs越大,iops每秒的读写次数越少。bw在bs 4k - 32k的情况下增长比较明显 32k以上达到了一定的瓶颈
随机读写:随着bs越大,iops每秒的读写次数越少。bw随着bs的增大而增大
与NFS对比
10G文件
第一行是glusterfs的压测数据
第二行为nfs的压测数据
Iops: 每秒的读写次数
bw (KiB/s): 每秒读/写 KB
| bs | 4k | 8k | 32k | 64k | 256k | 1024k |
|---|---|---|---|---|---|---|
| 顺序写 iops/bw | 22938/91753 7596/30384 | 113012/90513 6668/53347 | 2819/90223 4548/145558 | 1411/90363 3035/194252 | 352.15/90154 725/185792 | 87.76/89919 205/209920 |
| 随机写 iops/bw | 1200/4802 7219/28876 | 1156/9251 7002/56018 | 1003/32116 5682/181839 | 825/52826 3009/192603 | 328/83997 744/190548 | 87.87/90029 176/181225 |
| 顺序读 iops/bw | 26035/104140 72560/290242 | 26017/208140 65752/526017 | 8356/267403 53503/1671 | 4177/267387 40054/2503 | 1044/267401 16968/4242 | 261/267285 4735/4735 |
| 随机读 iops/bw | 26105/104422 72663/290654 | 26222/209779 66809/534479 | 8390/268495 53342/1666 | 4193/268390 40213/2513 | 1055/270179 16770/4192 | 266/272840 4475/4475 |
| 随机读写 iops/bw | read:767/3071 write: 765/3061 read:5791/23164 write: 5793/23174 | read: 717/5754 write: 719/5758 read: 5744/45956 write: 5733/45869 | read: 589.22/18856 write: 586/18775 read: 5267/84282 write: 5273/84376 | read: 465/29776 write: 481/30839 read: 2802/179387 write: 2811/179916 | read:182.79/46838 write: 197/49789 read: 695/178129 write: 701/179471 | read: 55/57018 write: 56/57953 read: 172/176817 write: 174/179043 |
压测对比结果
顺序写:bs在小于8k时 GlusterFS的iops和bw都高于NFS,bs一旦超过了8k iops 和bw都低于NFS
随机写:NFS整体高于GlusterFS
顺序读:bs低于8k时GlusterFS 每秒写入的字节数低于NFS ,大于8k时bw远远超过NFS。整体iops NFS高于glusterfs(读大文件时,glusterfs性能更优)
随机读:bs低于8k时GlusterFS 每秒写入的字节数低于NFS,大于8k时每秒读取的数据远远超过NFS,但是bw低于glusterfs意。整体iops NFS高于glusterfs (读大文件时,glusterfs性能更优)
随机读写:NFS高于GlusterFs
NFS和GlusterFs的优缺点
NFS
NFS的优点
NFS是Linux操作系统下最常用的网络文件系统之一,它通过网络将一个文件系统挂载在另一台主机上,使得多台主机可以共享同一个文件系统。NFS的优点如下:
(1) 简单易用:NFS的配置和使用都非常简单,只需要在服务端开启NFS服务,然后在客户端进行挂载即可。
(2) 效率高:NFS的数据传输采用RPC协议,传输效率高,数据传输速度快。
(3) 兼容性强:NFS支持跨平台,可以在Linux、Unix、Windows等不同操作系统间进行文件共享。
NFS的缺点
NFS也存在一些缺点,主要表现在以下几个方面:
(1) 安全性较差:由于NFS没有加密机制,所以在使用NFS进行文件共享时,可能会存在数据泄露的风险。
(2) 可靠性不高:NFS对网络环境的要求比较高,如果网络环境不稳定,容易导致文件共享出现故障。
(3) 扩展性差:NFS的扩展性比较差,当需要扩容时,需要手动进行配置,操作比较繁琐。
GlusterFS的优点
GlusterFS是一个分布式文件系统,它可以将多台计算机的硬盘空间组合成一个大的存储空间,并提供统一的访问接口。GlusterFS的优点如下:
(1) 可靠性高:GlusterFS可以将数据进行分布式备份,保证数据的可靠性。
(2) 扩展性强:GlusterFS支持在线扩容,不需要停止服务,可以方便地对存储空间进行扩容。
(3) 灵活性好:GlusterFS的架构设计比较灵活,可以根据不同的需求选择不同的存储方案。
GlusterFS的缺点
GlusterFS也存在一些缺点,主要表现在以下几个方面:
(1) 效率低:由于GlusterFS采用的是分布式存储方案,数据的读写需要通过网络通信,所以效率比较低。
(2) 配置复杂:GlusterFS的配置比较复杂,需要对系统和存储方案进行深入的了解,否则容易导致配置错误。
(3) 兼容性差:GlusterFS只支持Linux操作系统,对其他操作系统的支持比较差。
NFS与GlusterFS对比
1. 功能对比
NFS和GlusterFS都是用于虚拟化存储的解决方案,它们的核心功能都是实现文件共享。但是它们的实现方式不同,NFS是基于网络文件系统的协议实现文件共享,而GlusterFS是基于分布式文件系统的协议实现文件共享。
2. 吞吐量对比
在吞吐量方面,GlusterFS比NFS要慢,因为GlusterFS的数据读写需要经过网络通信,而NFS的数据读写直接在本地磁盘操作,所以相对来说,NFS的吞吐量要高一些。
3. 可靠性对比
在可靠性方面,GlusterFS比NFS要好。GlusterFS可以将数据进行分布式备份,保证数据的可靠性,而NFS没有这个功能,如果其中的某一台服务器出现问题,可能会导致共享文件系统无法正常访问。
4. 扩展性对比
在扩展性方面,GlusterFS比NFS要好。GlusterFS支持在线扩容,可以方便地对存储空间进行扩容,而NFS需要手动进行配置,操作比较繁琐。
综上所述,NFS和GlusterFS各有优缺点,在选择时需要根据自身需求进行选择。如果对吞吐量和操作复杂度有较高要求,可以选择NFS,如果对可靠性和扩展性有较高要求,可以选择GlusterFS。当然,也可以结合两个解决方案的优势,选择适合自己的混合存储方案。















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











