







机器学习实验报告
一、数据工程意义及其内容(自创名词,勿怪)
现如今,机器学习在越来越多的领域中凸显出其不可替代的重要性,人们开始从各领域渗透机器学习的典型案例,希望其大规模投入使用,而好的训练结果与坏的训练结果的区别并不在于你的模型好坏,而往往是取决于你拥有多少、多好的数据来训练你的模型。这就是为什么现在很多的互联网公司(诸如BAT、Google、Amazon)十分注重机器学习中大数据来源这一领域的原因。
建立成功的AI / ML模型有3个方面:**算法,数据和计算。**虽然建立准确的算法和计算技能的应用是过程的一部分,但一个优秀的机器学习项目,从编写模型到落地测试,投入使用,这期间都是以使用正确的数据集为基础, 无论是从自动驾驶汽车等基于AI的大规模技术革命还是到构建非常简单的算法,我们都需要正确格式的数据。
根据Cognilytica的最新研究,其中记录并分析了组织,机构和最终用户企业的响应,以识别在标记,注释,清理,扩充和丰富机器学习模型的数据上花费了大量时间,下图充分地说明了这一点:
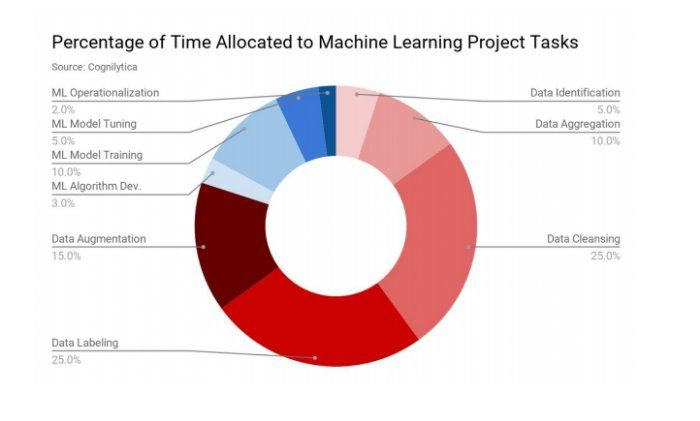
这告诉我们:
数据科学家80%以上的时间都花在准备数据上。尽管这是一个好兆头,但考虑到随着良好的数据进入建立分析模型,准确的人会得到输出。但是,理想情况下,数据科学家应该将更多的时间花在与数据交互,高级分析,培训和评估模型以及部署到生产上。
只有20%的时间进入流程的主要部分。为了克服时间限制,组织需要利用用于数据工程,标记和准备的专家解决方案来减少在清理,扩充,标记和丰富数据上花费的时间(取决于项目的复杂性)。
这就意味着,对于一个机器学习模型而言,很大程度上,输出的质量取决于输入的质量。
准备好的数据也是一门值得研究的学问,数据是每个机器学习项目的宝贵资源。但是,如果我们不进一步分析,它可能失去应有的价值。 从广义上讲,正确格式可以用于制定明智的业务决策,执行成功的销售和营销活动等。但是,这些不能仅用原始数据来实现。数据只有经过清洗,贴标签,注释和准备后,才能成为宝贵的资源。数据经过适应性测试的各个阶段后,便最终具备进行进一步处理的资格。处理可以采用多种方法-将数据提取到BI工具,CRM数据库,开发用于分析模型的算法,数据管理工具等。无论我们是构建自己的模型还是从第三方那里获得模型,都必须确保标记,扩充,干净,结构化的整个过程背后的数据都经过标记,概括,即数据准备。正如维基百科中定义的,数据准备是将原始数据(可能来自不同的数据源)操纵(或预处理)为可以方便,准确地进行分析的形式的行为,例如出于商业目的。数据准备是数据分析项目的第一步,可以包括许多离散任务,例如加载数据或数据摄取,数据融合,数据清理,数据扩充和数据交付。
在这里,我提出一个**“数据工程”**的概念,当然是我自创的,嘿嘿,我觉得其实对我现阶段我们ML学习的过程中,数据工程是包括但不只限于以下内容:
数据提取:数据工作流程的第一阶段是提取过程,通常是从非结构化源(如网页,PDF文档,假脱机文件,电子邮件等)中检索数据。部署从网络中提取信息的过程称为网络刮。
数据概要分析:检查现有数据以提高质量并通过格式带来结构的过程。这有助于评估质量和对特定标准的一致性。当数据集不平衡且配置不当时,大多数机器学习模型将无法正常工作。
数据清理:可确保数据干净,全面,无错误,并提供准确的信息,因为它不仅可以检测文本和数字的异常值,还可以检测图像中无关的像素。您可以消除偏见和过时的信息,以确保您的数据是干净的。
数据转换:对数据进行转换以使其均匀。地址,名称和其他字段类型之类的数据以不同的格式表示,数据转换有助于对此进行标准化和规范化。
数据匿名化:从数据集中删除或加密个人信息以保护隐私的过程。
数据扩充:用于使可用于训练模型的数据多样化。在不提取新信息的情况下引入其他信息包括裁剪和填充以训练神经网络。
数据采样:识别大型数据集中的代表性子集,以分析和处理数据。
特征工程:将机器学习模型分类为好模型还是坏模型的主要决定因素。为了提高模型的准确性,您可以将数据集合并以将其合并为一个。
二、机器学习中的数据偏见、伦理问题的思考(个人观点)
数据偏见带来的大祸
在模式识别的某一次实验课中,老师谈及了数据歧视这个问题,诚然,这是一个很严重的问题,因为编写机器学习模型的人出于原本对样本中某个特征的偏爱和憎恨,可能会在训练模型的时候将其代入倒是神经网络带有这一类判断的"精神影子",导致类型判决出现较大的偏差,举几个简单的例子:
案例研究1:招聘,解雇和刑事司法系统软件
深度学习算法越来越多地被用于制定影响生命的决策,例如雇用和解雇员工以及刑事司法系统。编码偏差会给决策过程带来陷阱和风险。
COMPAS 再犯算法 ,该算法用于预测囚犯或被控犯罪者如果被释放可能会犯下更多罪行的可能性。该算法用于授予保释,判刑和确定假释。但这个算法在实际使用时,对于白人被告(24%),误报率(标记为“高风险”但未重新犯罪)几乎是黑人被告(错误率45%)的两倍。
种族不是这个算法的明确变量,但种族和性别在很多其他变量中潜伏编码,比如我们居住的地方,我们的社交网络和我们的教育。即使是不注意种族或性别的有意识的努力并不能保证缺乏偏见尽管人们对COMPAS的准确性存有疑虑,但威斯康星州最高法院去年仍坚持使用它。该公司拥有美国80%的警用摄像机市场,因此他们拥有大量的视频数据。此外,新奥尔良警方过去六年一直在使用Palantir的预测性警务软件进行绝密计划,即使是市议会成员也不知道。像这样的应用程序是值得关注的,因为没有透明度。因为这些是私营公司,所以它们不像警察部门那样受制于州/公共记录法。通常,他们在法庭上受到保护,不必透露他们正在做的事情。此外,现有的警方数据存在很多种族偏见,因此这些算法将要从中学习的数据集从一开始就存在偏见。
最后,计算机视觉在实际测试中反复失败,并没有达到应有的效果,无法准确地预测有色人种在未来的犯罪动向,这是一次很失败的机器学习项目投入生产生活实际的例子,由于初始的数据偏见。
案例研究2:计算机视觉
另外一个臭名昭着的例子来自2015年。谷歌照片,自动标记照片,有用地分类毕业照片和建筑物的图像。它还将黑人称为大猩猩。
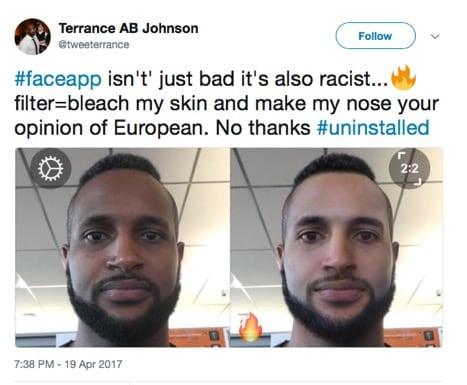
2016年, Beauty.AI 网站使用人工智能机器人作为选美比赛的评委。研究发现,皮肤较浅的人比黑皮肤的人更有吸引力。而在2017年, FaceApp使用神经网络为照片创建过滤器,创建了一个温度过滤器,可以减轻人们的皮肤并赋予它们更多的欧洲特色。Rachel展示了用户实际面部的推文和应用程序创建的更热门的版本。
一位叫Thomas的美国人谈到了 Joy Buolamwini和Timnit Gebru撰写的一篇 研究论文,他评估了微软,IBM和Face ++(一家中国公司)的几款商用计算机视觉分类器。他们发现分类器在男性上比在女性上更好,对于皮肤较浅的人而言比在深色皮肤上的人更好。有一个相当明显的差距:浅肤色男性的错误率基本上为0%,但对于深色皮肤的女性,错误率在20%到35%之间。Buolamwini和Gebru也通过皮肤阴影分解了女性的错误率。随着皮肤的黑暗,错误增加。最黑暗皮肤的类别错误率分别为25%和47%。
侵犯隐私?伦理何在,信息安全何在?
这里有个典型例子:某个日用品超市给一个17岁女孩发送了一个孕期女性的购物单,但是这个女孩其实不希望让父亲知道自己怀孕了。这个例子就是一个公共关系灾难,说明了法律,伦理以及商业目标之间的区别。法律上来说,该确实有权发送这些。尽管有人认为推荐薯条还是推荐个人医疗信息相关的产品是有区别的,不过也并不能说这个超市在伦理道德方面越界了。它顶多算是没有考虑客户或者公众是否能接受这个行为,但其造成的伦理隐私问题的损失是不好估计的。
类似的情况很有可能随着ML的发展而逐渐出现,比如利用个人信息来判断个人的素质好坏、推断家族病史、性格分析、家庭信息预测,这样种种很有可能会导致个人信息的大量泄漏,造成隐私问题。
综上,我们可以看到,所谓数据歧视、隐私泄露、伦理问题造成的损失是巨大的,但其实这些是当前存在且常见的现象,我们提到"bias"的时候,都是指日常生活中针对种族性别收入等社会属性的偏见、歧视。公众媒体的文章都着重这一方面。但是在数学和科学领域,bias是一个中性词,特指数据处理不合理,或者选错数据来源。ML里面这个风险更大,bias可能会导致错误结果。大家需要注意bias不要真的演化成社会歧视,或者导致损失一些商业机会和金钱,而这些就需要清楚上文中提到的"数据工程"的具体含义,并落实好每一个数据处理的步骤。
当然,我们都喜欢ML(Machine Learning)能够真的为人类造福,有人说,通过解释电脑学习的模式中的错误,就可以改进技术来消除人的偏见。瑞士 AI 实验室 Dalle Molle 人工智能研究所的科学主任 Jürgen Schmidhuber 说,人工智能系统在学习时会犯错。事实上这是肯定的,所以称之为“学习”。他指出,电脑只会从你给出的数据中学习。“你不能消除所有这些偏见的来源,就像你不能消除人类中的偏见来源,”。我觉得我们应该首先承认问题,然后确保使用好的数据,并把算法设计好;提出正确的问题至关重要,或者记住程序员的一句老话:“垃圾进,垃圾出(Garbage in, garbage out)”(当然,这好像也是吴德文老师在linux课上提过的,貌似?)。
的一句老话:“垃圾进,垃圾出(Garbage in, garbage out)”(当然,这好像也是吴德文老师在linux课上提过的,貌似?)。**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









