








一、整体网络架构:
Dense block:densenet的主要结构
Fusion layer:融合层*2
Convolutional layer:卷积层
摘要:
提出了一种新颖的基于深度学习的解决红外和可见光图像的方法,相较于传统的卷积网络,我们的编码网络结合了卷积层、融合层和dense block。
编码器---提取特征,两个融合层---融合特征,解码器---图像重建
在客观和主观评估上都达到了艺术状态的表现
Introduction:
| muli-scale decomposition-based methods | 基于分解的多尺度方法 |
| Sparse representation(SR) | 稀疏表示 |
| Histogram of Oriented Gradients(HOG)-based fusion method | 方向梯度直方图 |
| Joint Sparse representation(JSR) | 联合稀疏表示 |
| co-sparse representation | |
| Low-rank | 低秩 |
a.许多信号处理方法被应用于在图像融合任务中进行特征提取,比如基于分解的多尺度方法。主要特征同各国图像分解方法被提取,之后使用合适的融合方法获得最后的融合图像
b.近些年,基于学习的表示方法也引起了极大的关注,在稀疏领域的许多方法都被提出,比如稀疏表示、基于方向梯度直方图的融合方法、联合稀疏表示、连接稀疏表示。
c.在低秩领域的方法:基于低秩表示的融合方法,这个方法代替了稀疏表示来提取特征,之后使用L1范数和最大选择策略重建融合图像
d.卷积神经网络被用来提取特征和重建融合图像,但是只有最后一层的结果被作为图像特征,会丢失许多中间层获得的有用信息,这些信息对融合方法十分重要。
为了解决这个问题,我们提出了一张用编码器和解码器重建图像的深度学习方法。编码器用来提取图像特征,解码器获得融合后的图像。
网络架构组成:编码网络encoder+融合层fusion layer+解码网络decoder
编码网络:提取图像特征---卷积层+dense block(每一层的输出=下一层的输入)
每一层的结果都被用来重构特征图谱
解码网络:获取融合图像---四个CNN层
和融合架构一起重构融合图像
Related works:
Decision map:决策图
Addition strategy:
deep residual learning framework:深度残差网络
Gray scale image:灰度图像
Reflection mode:反射模型
最近两年许多融合算法被提出,尤其是基于深度学习的方法,不像基于分阶段多尺度方法和基于学习的表示方法,深度学习算法使用许多图片训练网络,这些网络被用来提取主要特征。
2016年刘宇和其他人提出了基于卷积是稀疏表示的融合方法CSR。CSR和基于CNN的方法不同但是依旧是基于深度学习算法,因为他依然提取深度特征。在这个方法中,作者使用原图片学习包含不同范围的字典,并且使用CSR方法提取多层特征。
2017年刘宇和其他人为了解决多角度图像融合任务也提出了基于CNN的融合方法,包含输入图像不同灰度角度的图像块被用来训练网络,并用此网络来得到决策图。之后,使用决策图和原图像得到融合的图像。但是这种方法仅仅适用于多角度图像融合。
2017年的ICCV杂志上,有人提出了用于探索融合问题的基于CNN的方法。他们提出了一个简单的编码器有两个CNN层解码器有三个CNN层的基于CNN的架构。编码器拥有双头网络架构,权重也联系在一起。两张输入图像被他编码,之后得到两个特征图序列,最后采用别的策略将特征图融合。最后通过被叫做含有三个CNN层的解码器得到最终的融合图像。虽然这个方法表现更好但是依然有两个主要的缺点:网络架构十分简单,主要特征无法被正确提取;这些方法仅仅使用了编码器最后一层计算出的结果,而中间层的有用信息被丢失,网络更深这种现象更坏。
为了克服这些缺点,我们提出了一种新颖的基于CNN层和denseblock的深度学习架构。在我们的模型当中,使用红外可见光图像对作为方法的输入,与下一层输入级联的编码器的每一层得到特征图。
在传统CNN网络中,随着网络的加深,梯度消失问题会出现,中间层提取的信息也会被彻底使用。为了解决梯度消失问题,他们介绍了深度残差网络。为了提升层与层之间的信息流,有人提出了拥有denseblock是新型架构,在这个架构里面任何层到下一层的直接联系都会被使用。denseblock架构有三个优点:
Dense block的三个优点:
a.可以保存尽可能多的信息 b.更容易训练网络 c.降低过拟合风险
由于这些优点,我们将denseblock和解码器结合起来,这就是本文名字的由来:densefuse。有了这个操作,我们可以保存中间层更多有用的信息并且更容易训练。
网络/方法输入:红外光可视图像对
特征图谱的获取:编码网络的 每一层
在dense block中,特征图谱作为下一层的输入
提出的融合方法:
encoder=卷积层C1+denseblock(每一层的结果都被用来重构特征图谱)
卷积层C1:包含3×3个卷积(提取粗略特征)
dense block:包含3个3×3的卷积层(DC1、DC2、DC3 每个层的输出级联下一层的输入)
特征图谱的输出通道为16个
encoder优点:a.输入图像可以为任何尺寸
b.dense block可以保存尽可能多的特征,保证所有显著的特征都能在融合层被用到
融合层
decoder=4个3×3卷积层(C2,、C3,、C4、C5滤波器尺寸为3×3)---重构最后的融合图像---融合层的输出就是解码器的输入

训练:首先单独训练编码器-解码器结构用于重构图像,然后再添加中间的融合层,通过自适应融合策略来融合编码器得到的特征图像。
训练机制的显著优点:可以为特定的融合任务设计所适合的融合层,可以为融合层进一步的发展提供更多的空间

损失函数:像素级损失函数和图像质量损失函数的加权平均
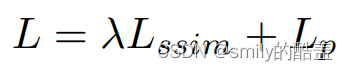
像素级损失函数𝐿𝑝=|𝑂−𝐼|2(O---输出图像,I---输入图像,其实是输入图像和输出图像之间的欧氏距离)
图像质量损失函数𝐿ssi𝑚=1−𝑆𝑆𝐼𝑀(𝑂,𝐼)(SSIM---结构相似性操作,其实是代表两张图片之间的相似性)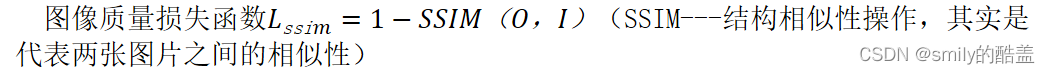
训练阶段,𝐿𝑝和𝐿ssi𝑚之间有三个数量级的差异,所以训练过程中设置λ为1,10,100,1000
训练过程:
a.设置λ为1,10,100,1000
b.目的---训练自动解码网络(包括编码器和解码器),使其有更出色的特征提取和重构能力
c.红外-可见光图像数据集样本不多,这里用的是灰度COCO数据集进行训练,也就是直接用可将光图像来训练编码器-解码器网络了。一共选取8万张图像,重采样为256×256的尺寸并且转变为灰度图像
输入---MS-COCO 学习率---0.0001 batch size---2 epoch---4
硬件设置---NVIDIA GTX 1080Ti GPU 后端---tensorflow
融合层:选择两种融合机制结合从编码器中得到的显著特征图
直接相加的策略:【直接将红外和可见光图像得到每个通道的特征图上每个对应像素点的值相加】一旦编码网络和解码网络被决定,在测试部分,两张输入图像就会被分别输入到编码网络

fm直接作为解码器的输入用于重建图像![]()
![]()
L1范数和softmax相结合的策略:直接相加的融合策略对于主要特征的选取过于粗暴
Ǿim:特征图
活跃度图Cˆ i:通过L1范数和基于块的平均算子计算得到
特征图的l1-norm可以作为该特征图的活跃度
起始活跃度用下式5计算:
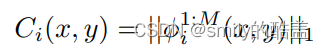
最终活跃度计算6:【得到上面结果后结合平均算子计算最终的活跃度,r是block的尺寸,本文设置为1】
![]()

fm直接作为解码器的输入用于重建图像
实验结果和分析:
| the orders of magnitude | 数量级 |
| cross bilateral filter fusion(CBF) | 交叉双边滤波器融合方法 |
| Joint-sparse representation model(JSR) | 联合稀疏表达 |
| gradient transfer and total variation minimization(GTF) | 基于梯度转移和总变化最小化 |
| the JSR model with saliency detection fusion method(JSRSD) | 拥有显著性检测的JSR模型融合方法 |
| En | 熵 |
| Qabf | 融合质量 |
| the sum of the correlations of differences(SCD) | 差异相关性之和 |
| FMIw and FMIdct which calculates mutual information (FMI) for the wavelet and discrete cosine features | 分别计算小波特征和离散余弦特征的互信息 |
| Modified structural similarity for no-reference image(SSIMa) | 修改无参考图像的结构相似度 |
| A new no-reference image fusion performance measure(MS_SSIM) | 新的无参考图像融合性能指标 |
训练部分分析:损失曲线和SSIM曲线
输入---MS-COCO---79000张照片输入,1000张照片作为每次迭代的验证
a.第一次2000次迭代时,当SSIM损失函数权重λ的数值索引不断增加时,网络有快速的融合
b.像素级损失函数和SSIM损失函数的数量级是不同的,λ增加时,SSIM在训练时的作用更加重要
【验证部分分析:】
训练网络的输入---MS-COCO的1000张照片---两个损失函数用来评估重构能力
a.随着λ的增加,SSIM起着重要的作用,迭代次数到500的时候并且λ被设置为一个大点的数值,像素级损失函数的值和SSIM损失函数的值会达到更好
c.迭代次数超过40000时,无论损失权重被设置为多少,都将会得到最优权重
总结---早期训练过程中随着λ的增加,网络融合/模型收敛的更快。λ更大,会在训练时减少时间消耗
实验设置:
对比实验:CBF、JSR、GTF、JSRSD、CNN、DeepFuse
deepfuse的卷积层尺寸被设置为3×3
对比融合方法:质量测量指标(7个):En、Qabf、SCD、FMI、SSIMa、MS_SSIM【
| 熵 |
| 融合质量 |
| 差异相关性之和 |
| 分别计算小波特征和离散余弦特征的互信息 |
| 修改无参考图像的结构相似度 |
| 新的无参考图像融合性能指标 |
【SSIMa的值代表保存结构信息的能力,七个指标值提升就表示融合表现提高】
融合方法评估:
所有的方法使用的参数在以下的表中。
由于空间限制,我们评估了两种图像车和街道融合方法的相关表现。
a.CBF、JSR、JSRSD:人工噪音更大,显著特征不明显 【图8的天空和楼梯图9的广告牌】,无论如何选择参数的值,使用本文方法得到的红色图框里的融合图像噪音很小
b.GTF、CNN、DeepFuse:我们的方法可以保存红色框内图像更详细的信息,CNN融合的图片更黑更暗【原因:基于CNN的方法不适合红外可见光图像】,相反使用我们的方法得到的融合图像更加自然
c.deepfuse和所提出的方法在人类敏感性上没有特别大不同---所以我们选择一些客观指标再次评价融合方法的表现
【最佳值---粗体、第二最佳---斜体+蓝色】
我们采用直接相加机制和l1范数的的方法:有五个最好的平均值(En、Qabf、SCD、FMIdct、SSIMa)和两个次好值(FMIw、MS_SSIM)
FMIdct、SSIMa最好---此方法保留了更多的结构信息和特征
得到的融合图像更加自然并且只包含很少的人工噪音---由于En、Qabf、SCD值最好
由于我们的模型中结合了直接相加和l1范数的策略,所以我们算法的七个质量评估指标也有最佳值和次佳值---这说明我们的网络对于红外可见光图像的融合任务是非常有效的
处理RGB图像和红外图像:
除了处理灰度图像,我们的融合算法也可以用来处理包含RGB通道的可见光图像和红外图像,图像选自参考文献第32篇
处理:RGB图像的每个通道被单独作为一个灰度图像处理,网络的输入:每对通道(一共三对),所以最后可以得到三个被融合的通道,之后再结合这些融合后的通道即可,
【如果处理RGB图像只需要将每个通道分离后单独使用上述模型融合,最后再重新合并为三通道的RGB图像即可】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









