







函数
不同 DBMS 函数的差异
我们在使用 SQL 语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即
DBMS。DBMS 之间的差异性很大,远大于同一个语言不同版本之间的差异。实际上,只有很少的函数是被 DBMS 同时支持的。比如,大多数 DBMS 使用(||)或者(+)来做拼接符,而在 MySQL 中的字符串拼接函数为concat()。大部分 DBMS 会有自己特定的函数,这就意味着采用 SQL 函数的代码可移植性是很差的,因此在使用函数的时候需要特别注意。
Oracle 函数分类
MySQL提供的内置函数从实现的功能角度 可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取Oracle信息函数、聚合函数等。这里,我将这些丰富的内置函数再分为两类: 单行函数、聚合函数。
单行函数:接受一个数据,输出一个数据
聚合函数(分组函数):是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值
单行函数
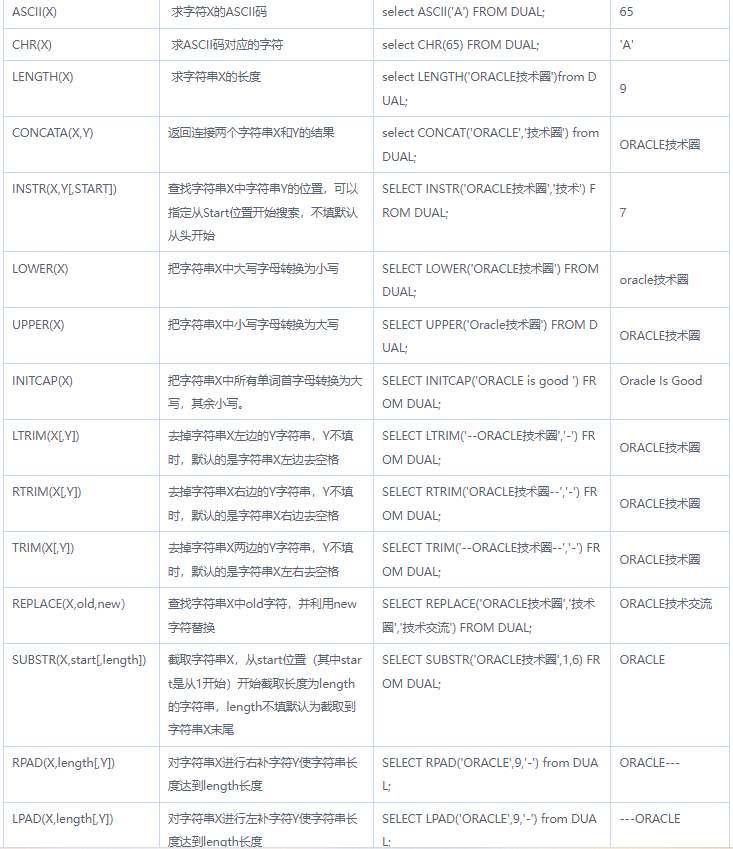
字符函数(针对字符串操作)
- 字符和ASCII转换函数
- ASCII(X):求字符X的ASCII码
- CHR(X):求ASCII码对应的字符
- 大小写控制函数:
- LOWER(X):所有字母转换为小写
- UPPER(X):所有字母转换为大写
- INITCAP(X):每个单词第一个字母为大写,之后的为小写
- 字符控制函数:
- LENGTH(字符串):求长度
- CONCAT(列名1,列名2):拼接两个列,如果多个列拼接,需要嵌套concat(x,concat(x))【不能嵌套超过三次】
- REPLCAE(str, old, new):替换字符串
- SUBSTR(’字符串’,截取开始处的位置[,截取长度]):截取字符串
- INSTR(’母串’,’需查找的子串’):查找字符串的位置
- LTRIM(字符串,剪切符号):从左边开始剪切
- RTRIM(字符串,剪切符号):从右边开始剪切
- TRIM(字符串,剪切符号):从两边开始剪切
- LPAD(字符串,数据的长度,填充符号):从左边开始填充
- RPAD(字符串,数据的长度,填充符号):从右边开始填充
注意:字符串从1开始算
数值函数(与数学相关)
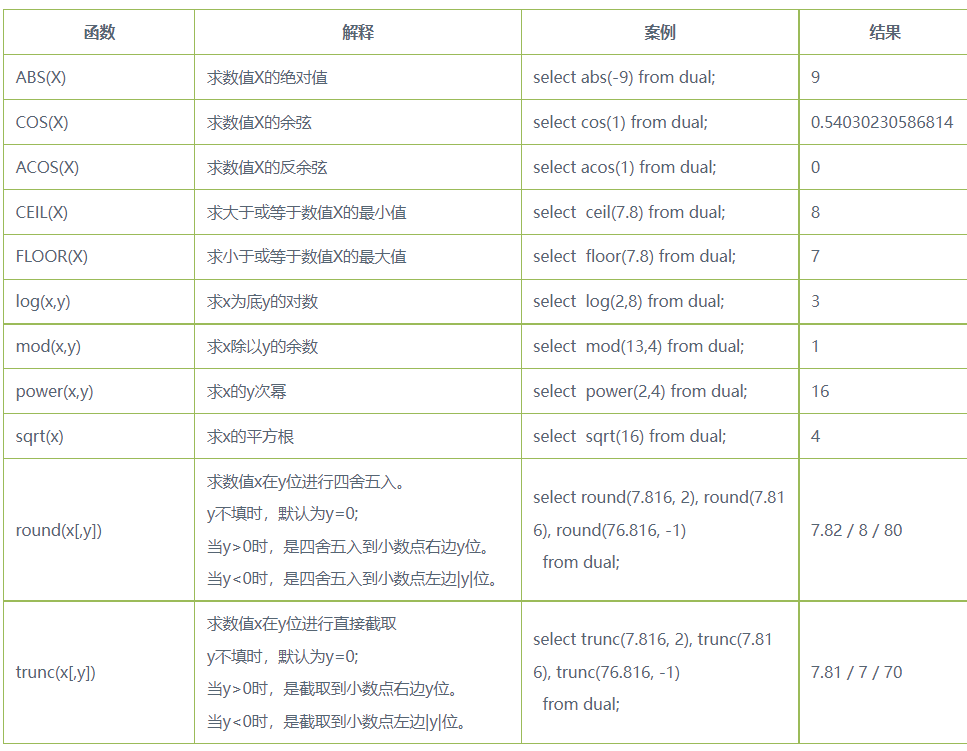
- EXP(x):计算e的x次幂,e为自然对数,e=2.71828…
- SELECT EXP(1) FROM dual;
- 结果:2.71828182845905
- LN(x):返回x的自然对数, x必须是正数,并且大于0
- SELECT LN(2.71828182845905) FROM dual;
- 结果:1
日期函数
更多更细见:https://www.oraclejsq.com/article/010100358.html
- 日期的算数运算
- 日期 ± 数字 = 日期
- 日期 ± 日期 = 天数(得出来的天数不是整数,因为还要考虑时分秒)
- SYSDATE,SYSTIMESTAMP,DBTIMEZONE为无参函数
- SYSDATE 系统的当前时间
- SYSTIMESTAMP 系统的当前时间,该时间包含时区信息,精确到微秒
- DBTIMEZONE 数据库时区
- 给日期加上指定的月份函数:(看链接内容,讲的很详细)
- MONTHS_BETWEEN(r1,r2):两个日期之间相差的月份(结果有可能为小数)
- ADD_MONTHS(日期r, 月份n):返回在指定日期r上加上月份数n后的日期
- LAST_DAY(日期r):返回指定日期r的当前月份的最后一天日期
- NEXT_DAY(日期r, 星期几c):返回指定日期r的后一周的与星期几c对应的日期。
- EXTRACT(time):返回指定time时间当中的年、月、日、分等日期部分。
- ROUND(r[, f]):将日期r按f的格式进行四舍五入。如果f不填,则四舍五入到最近的一天。
- TRUNC(r[, f]):将日期r按f的格式进行截取。如果f不填,则截取格式为天。
转换函数
更多见:https://www.oraclejsq.com/article/010100362.html
- TO_CAHR(x[,f]):将时间日期按照指定的格式输出,得到的是string类型
- TO_CAHR(sysdate, ‘yyyy-mm-dd hh24:mi:ss’)
- TO_DATE(x[,f]):将字符串按照指定的格式输出,得到的是date类型
- TO_DATE(‘2004-05-07 13:23:44’, ‘yyyy-mm-dd hh24:mi:ss’)
- TO_NUMBER(x[,f]):可以把字符串x按照格式f进行格式化转换为数值类型结果。
- TO_NUMBER(‘123.74’,‘999.99’),结果123.74
选择判断函数
- NVL(string1, replace_with):如果string1为null,那么nvl()函数返回replace_with的值,否则返回sting1的值。
- sting1和replace_with必须是同一数据类型,除非显示的适用to_char函数。
- NVL2(E1, E2, E3):若E1不为null,则返回E2。如果E1为NULL,则函数返回E3。
- DECODE(条件,值,返回值1,返回值2):当条件等于值时,该函数返回值1,否则返回值2。
- DECODE(条件, 值1, 返回值1, 值2, 返回值2, …值n, 返回值n, 缺省值)
- NULLIF(expr1, expr2):当两个相等的时候返回null,不相等的时候返回expr1
- COALESCE(expr1,expr2,…,exprn):如果1为空返回2,如果2为空返回3,如果3为空,返回…
分组函数(聚合函数)
更多更细见:https://blog.csdn.net/qq_40018576/article/details/123075704
- 使用聚合函数进行统计时,只有COUNT函数的*或者value会把空值一并统计,除此以外的其他聚合函数都不会对空值进行统计。
- 可以对数值型数据使用AVG 和 SUM 函数
- AVG( [ distinct | all ] column ):求平均数
- SUM( [ distinct | all ] column ):求和
- 可以对任意数据类型的数据使用MIN、MAX、COUNT函数。
- COUNT(* | value | [ distinct | all ] column):求总数
- (*) :表示统计包括空值在内的满足条件的所有记录的数量;
- value :可以为具体的数值或字符串,表示统计包括空值在内的满足条件的所有记录的数量;
- COUNT(*)会统计值为 NULL 的行,而 COUNT(列名)不会统计此列为 NULL 值的行。
- MAX( [ distinct | all ] column ):求最大值
- MIN( [ distinct | all ] column ):求最小值
- STDDEV( [ distinct | all ] column ):用来求标准差,可以用做聚集和分析函数
- VARIANCE( [ distinct | all ] column ):统计数据方差,可以用做聚集和分析函数
- COUNT(* | value | [ distinct | all ] column):求总数
- 分组函数是可以嵌套的例如:MAX(AVG(salary))














 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









