







redis stream
intro
stream是5.0之后引进的新的数据类型,被称为kafka killer。
stream是一种类似于日志的数据结构,而且是尾部追加的。

(一个生产者和一个消费者的情况,由stream连接)
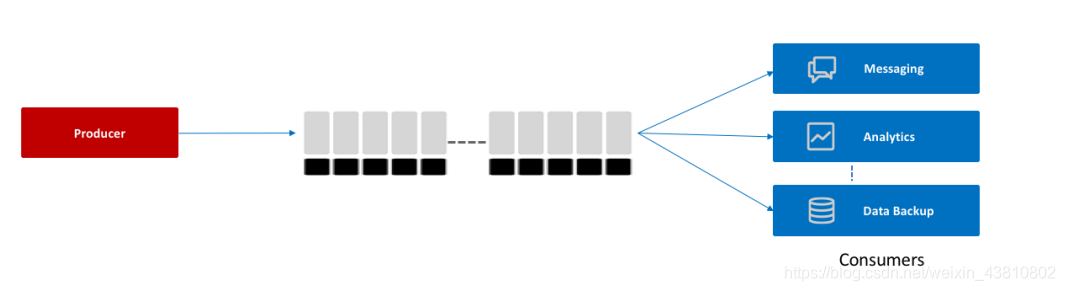
(一个生产者和多个消费者的情况)
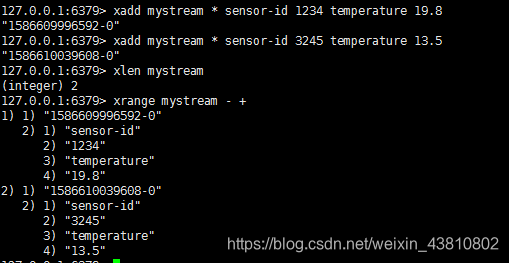
我们通过xadd向mystream这个key加入两条数据。*代表id的生成规则,那就是,由redis自动生成。返回的数据就是id,它的结构为:
<millisecondsTime>-<sequenceNumber>
由毫秒数(redis的local time)和序列号码组成。
毫秒数可以在取值的时候用:

取出给定毫秒数之后的值(取一个)。
序列号用于当毫秒数一样时(两个client同时add),自增来解决冲突。
当然,xrange是读取数据的一种方式。
另一种方式是xread。
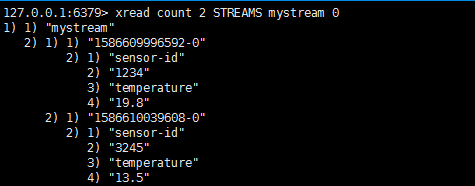
命令表示我们希望得到mystream中所有id大于0-0的数据。
事实上,xread主要用于监听。
不阻塞的xread,如果stream中没有值(是空的),那么就返回空:

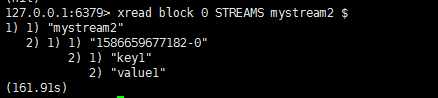
阻塞的xread:

block 0表示一直阻塞,直到有消息过来。
$是一个特殊的id,它表示当前最大id,含义就是,每次读取的消息的id要大于当前最大id,也就是每次都读取最新消息,就像Linux中的tail -f一样。
当我们在另一个客户端add进消息时,它就会读到:
这和blpop或lrpop简直一样,和subscribe、publish
也一样。只是人家pubsub没有记忆,发出的消息不能找到。而stream是保留下来的:
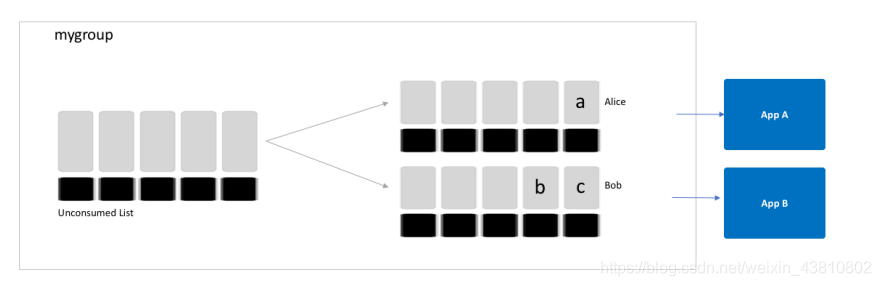
consumer group是如何工作的?
因为生产端和消费端的速度不等,往往是生产快,消费慢,所以我们要用一个group去消化生产的数据,group中的每一个consumer可以按照自己的速度来消化。

(生产快,消费慢)
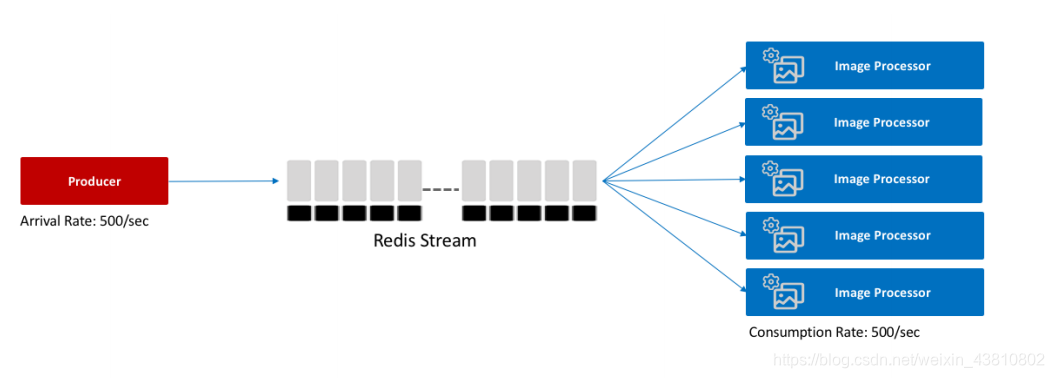
(每个image processor的速度都是100,这样就能组合起来消费数据了)
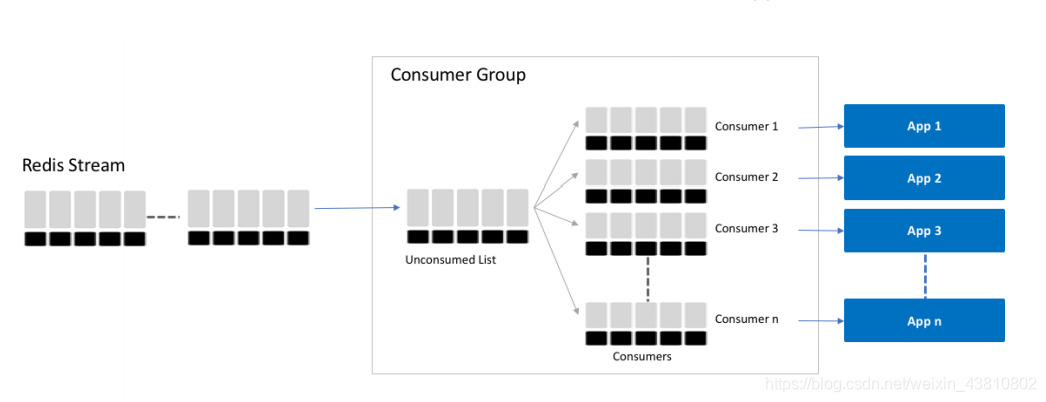
(redis中group的结构)
消息生产后,都会添加进unconsumed list,消费者可以用XGROUPREAD命令来读数据,把要读的数据放入自己对应的pending entries list。消费端都按照自己的节奏来读,没有两个consumer会读到相同的数据。
app回一个XACK命令就会将消息从pending entries list中移除,意思是确认了消息。

我们创建了一个stream叫做mystream,一个与这个stream连接的group叫做mygroup。并且我们告诉stream我们只要当前数据(最新数据)。
MKSTREAM表示如果mystream存在,就不用create了,不存在就create一个空的mystream。
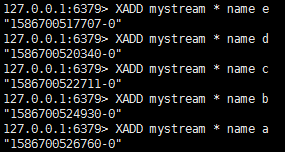
在mystream中添加内容。
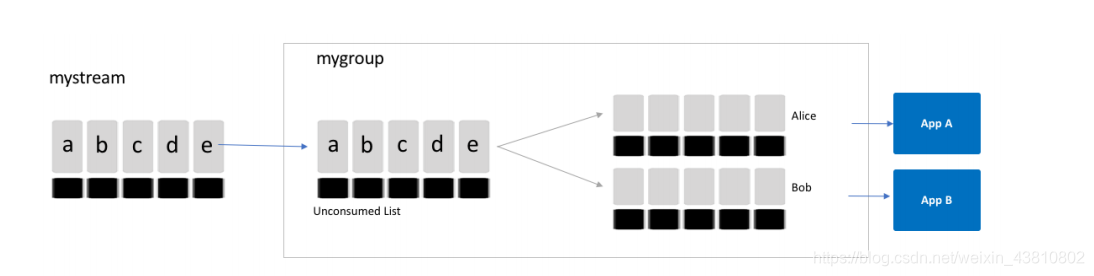
我们打算准备两个consumer(Alice和Bob)来消费数据,并将其用于自己的应用程序。
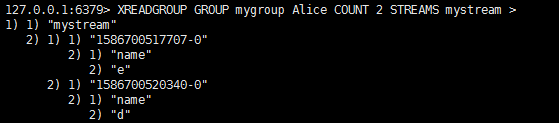
Alice读到两条。
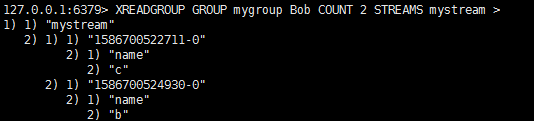
Bob读到两条。
>告诉stream我们索要没有供给其他consumer的数据。就像b和c没有被Alice消化,就可以被Bob读到。
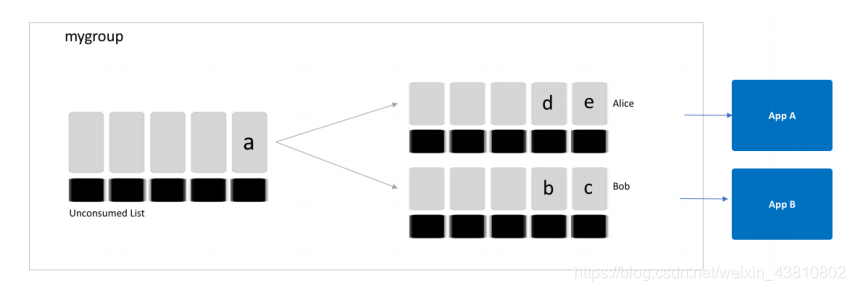
但是redis并不知道App A和App B是否成功消费了数据,只有调用了XACK命令,应用程序才算确认了消息。
为什么要用XACK来确认呢?因为如果在数据传输过程中数据丢失的话,那么就再也找不回来了。
这就好像你开启了一个transaction,然后commit一样。


这时Alice的确没有pending的list了。
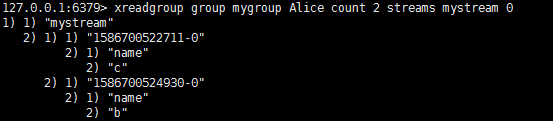
我们可以让Alice把剩下的消息读进来:

这时候的情况是:
如果App B没有使用XACK或者在确认过程中因为一些原因down了,这时候:
- App B重新从Bob里读:
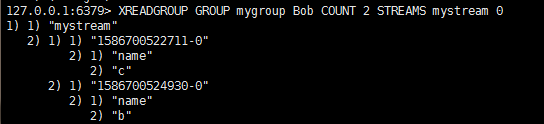
这条指令得到了Bob里所有的数据 (history of pending message)。
- 在App B无法恢复的情况下,将数据转移给A处理。
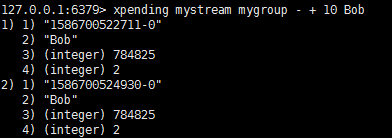
Bob里还有两条数据,现在,我们要让Alice来承接。

Alice后面跟着一个0,它表示闲置时间,空闲时间大于0的id为1586700522711-0、1586700524930-0的Bob中的消息都要转移到Alice去。


















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









