







Hive元数据存储库数据增多的分析
文章目录
问题
元数据存储库的情况,多个单表数据超过2千万。
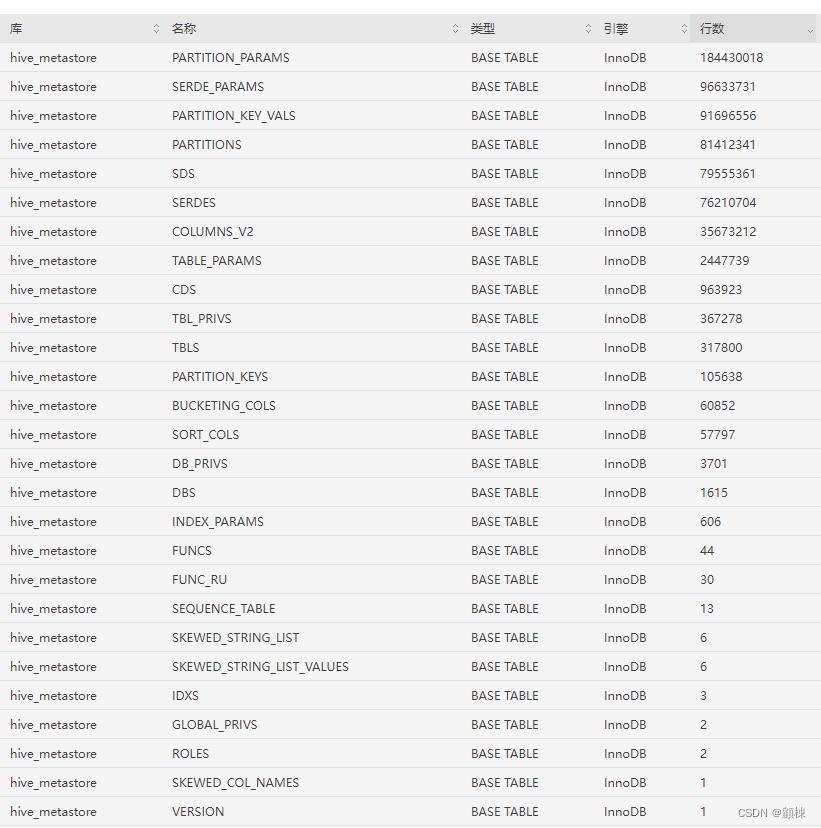
对超过2千万数据量的表需要进行分析,分析的角度:
- hive的哪些操作会引起这些表的数据的变化?
- 了解这些表的数据代表什么?
- 表数据之间的关系?
新增Hive相关的DDL操作
创建Hive库
create DATABASE if not EXISTS test20230425001 COMMENT '测试的库' WITH DBPROPERTIES ('createUser'='顾栋','date'='20230425');
DROP DATABASE IF EXISTS test20230425001;
库授权到用户
INSERT | SELECT | UPDATE | DELETE | Create | ALL
grant select on database test20230425001 to user hdfs;
REVOKE select on database test20230425001 from user hdfs;
创建Hive表 内部表
非分区表
CREATE TABLE `test20230425001.t_test_001`(
`cluster_name` string COMMENT 'hbase集群名称',
`namespace` string COMMENT '命名空间',
`table_name` string COMMENT '表名',
`system_os` string COMMENT 'Hbase表的归属系统')
COMMENT 'hbase表与归属系统表'
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
Drop Table `test20230418001.t_test_001`;
表授权到用户
INSERT | SELECT | UPDATE | DELETE | ALL
grant select on table test20230425001.t_test_001 to user hdfs;
REVOKE select on table test20230425001.t_test_001 from user hdfs;
一级分区表
CREATE TABLE `test20230425001.t_test_002`(`ldc` string COMMENT '机房',`cluster_name` string COMMENT '集群名称',`cluster_id` bigint COMMENT '集群id')
COMMENT 'ES的索引申请情况的信息表'
PARTITIONED BY (`date_time` string COMMENT '分区字段')
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230417');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230418');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230419');
ALTER TABLE `test20230425001.t_test_002` ADD IF NOT EXISTS PARTITION (date_time='20230420');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230417');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230418');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230419');
ALTER TABLE `test20230425001.t_test_002` DROP IF EXISTS PARTITION (date_time='20230420');
Drop Table `test20230425001.t_test_002`;
二级分区表
CREATE TABLE `test20230425001.t_test_003`(
`ldc` string COMMENT '机房',
`cluster_name` string COMMENT '集群名称',
`cluster_id` bigint COMMENT '集群id')
COMMENT 'ES的索引申请情况的信息表'
PARTITIONED BY (
`month` string COMMENT '1级分区字段',
`day` string COMMENT '2级分区字段')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='17');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='18');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day='19');
ALTER TABLE `test20230425001.t_test_003` ADD IF NOT EXISTS PARTITION (month='202304',day= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











