







上次课程我们学习了SELECT语句,这次我们学习数据汇总与分组,这里即将是SQL最为关键和面试考察难点,让我们开启新的旅程!!!
目录
1. 汇总数据
1.1聚集函数
| 函 数 | 说 明 |
|---|---|
| AVG() | 某列平均值 |
| COUNT() | 某列的行数 |
| MAX() | 某列的最大值 |
| MIN() | 某列的最小值 |
| SUM() | 某列之和 |
- 函数的操作对象是某列,必须掌握。
1.2 应用聚集函数
- 原始数据
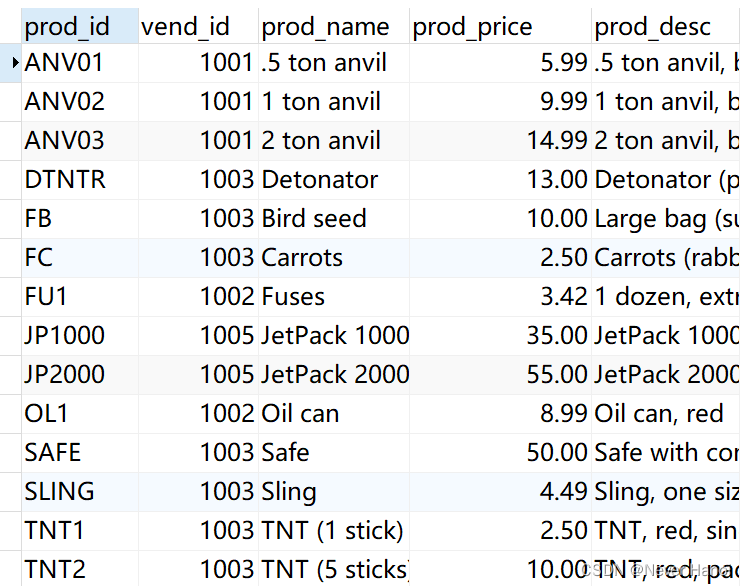
- 输入
SELECT
COUNT(*) as prod_num,#商品数量
MIN(prod_price) as price_min,#最小值
MAX(prod_price) as price_max,#最大值
AVG(prod_price) as price_avg,#平均值
SUM(prod_price) as price_sum #价格总和
FROM
products;- 输出
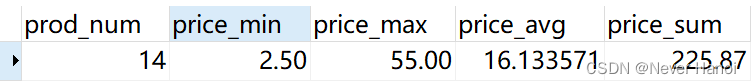
- 分析:
- count(*) 数条数的时候不忽略null
- count(列名) 数条数的时候忽略null;MAX()在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行;MIN相反。MAX()函数忽略列值为NULL的行一般没人用
- MIN()函数忽略列值为NULL的行
- AVG()函数忽略列值为NULL的行
2.分组数据
2.1 GROUP BY
- 输入
SELECT
vend_id,
count(*) AS prod_nums
FROM
products
GROUP BY vend_id;- 输出
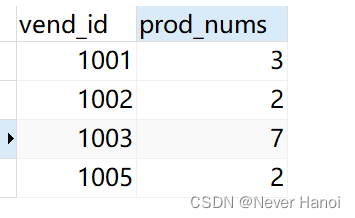
- 分析:
- group by是将vend_id数据分为多个逻辑组,然后对每个组进行聚集函数应用。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
2.2 WITH ROLLUP
- 输入
SELECT
vend_id,
count(*) AS prod_nums
FROM
products
GROUP BY vend_id WITH ROLLUP;-
输出
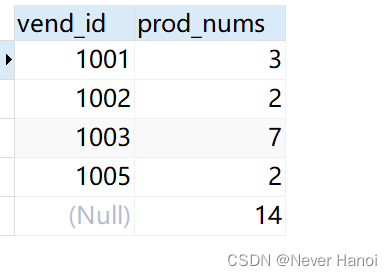
- 分析:最后一行为各个统计数量加和。本函数为刷题时遇到,特地补充上。
2.3过滤分组having
- 输入
SELECT
cust_id,
count(*) AS prod_nums
FROM
orders
GROUP BY cust_id
HAVING COUNT(*)>=2;- 输出

- 分析: WHERE过滤行,HAVING过滤分组。WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤
3.SELECT子句执行顺序
| 子 句 | 说 明 |
|---|---|
| SELECT | 查询 |
| FROM | 从某个表 |
| WHERE | 过滤行数据 |
| GROUP BY | 对数据进行分组 |
| HAVING | 对分组数据进行过滤 |
| ORDER BY | 对查询结果进行排序输出 |
| LIMIT | 输出限制条数 |
3.总结参考
滴滴,入门完成。
- 聚合函数
- 分组函数
- 执行和编写顺序
参考:
《MySql必知必会》















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









