






一次修改两个表的数据
UPDATE zl.table1 t1,zl.table2 t2 SET t1.aa = ’ a ’ ,t1.bb = ’ b ’ ,t2.cc = ’ c ’ ,WHERE t1.u_id = t2.u_id AND t1.u_id = ’ 1 ’
MVCC
只阻塞修改操作,不阻塞查询类操作。乐观锁的机制(谁先提交谁为准),解决读写冲突。 show global variables like "%datadir%"; 查看mysql文件存储位置,大部分mysql配置都通过此方式查看 换个匹配字符就好。
global 设置MySQL集群配置信息。
show variables like '模糊查询字符'; 查看mysql配置信息
set autocommit = 0; 设置mysql单个数据库配置
desc 表名 查看表结构。
use 数据库名 切换数据库。
truncate table 表名 清空数据表,不记录sql日志,不可以恢复数据。
drop database 数据库名 删除数据库,也删除数据库所有表。
drop index 索引名 删除索引。
drop table 表名 删除表。
select database(); 查看当前使用数据库
select * from information_schema.columns where
table_name = '表名'
and COLUMN_NAME like "%模糊查询字符%"
查看表列名。
show table status from 数据库名 查看数据库内表状态 。
mysqldump -uroot -p123 -A --triggers -R --master-data-2 >tmp/full.sql 备份数据库数据,不要用-A 会备份所有。
alter table 表名 discard tablespace; 删除表的表空间(删除ibd文件);
alter table 表名 import tablespace; 导入表空间文件(ibd文件);
select sleep(n); 让sql强制执行n秒
alter table JY_BASE_ACCOUNT AUTO_INCREMENT = 10001;
设置主键自增下个值
set auto_increment_increment=2;
设置自增列步长,全局的。
set auto_increment_offset=2;
设置自增列开始值,全局的。
show variables like '%max_connection%'; 查看最大连接数
set global max_connonections =1000; 重新设置最大连接数
show status like ‘Thread%’; 查询当前连接状态
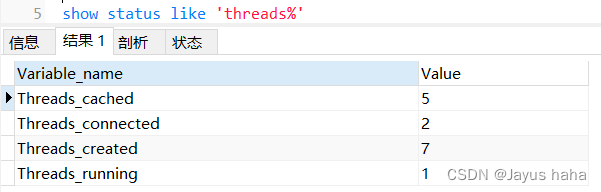
Thread_connected :打开的连接数
Thread_running:激活的连接数,一般远低于connected值
Thread_created表示创建过的线程数
Thread_cache_size表示缓存线程数。客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)
Thread_connected和show processlist 结果相同
show processlist 查看所有用户的当前连接。
show status; 查看数据库状态。
变量名如下:
Aborted_clients 由于客户没有正确关闭连接已经死掉,已经放弃的连接数量。
Aborted_connects 尝试已经失败的MySQL服务器的连接的次数。
Connections 试图连接MySQL服务器的次数。
Created_tmp_tables 当执行语句时,已经被创造了的隐含临时表的数量。
Delayed_insert_threads 正在使用的延迟插入处理器线程的数量。
Delayed_writes 用INSERT DELAYED写入的行数。
Delayed_errors 用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数。
Flush_commands 执行FLUSH命令的次数。
Handler_delete 请求从一张表中删除行的次数。
Handler_read_first 请求读入表中第一行的次数。
Handler_read_key 请求数字基于键读行。
Handler_read_next 请求读入基于一个键的一行的次数。
Handler_read_rnd 请求读入基于一个固定位置的一行的次数。
Handler_update 请求更新表中一行的次数。
Handler_write 请求向表中插入一行的次数。
Key_blocks_used 用于关键字缓存的块的数量。
Key_read_requests 请求从缓存读入一个键值的次数。
Key_reads 从磁盘物理读入一个键值的次数。
Key_write_requests 请求将一个关键字块写入缓存次数。
Key_writes 将一个键值块物理写入磁盘的次数。
Max_used_connections 同时使用的连接的最大数目。
Not_flushed_key_blocks 在键缓存中已经改变但是还没被清空到磁盘上的键块。
Not_flushed_delayed_rows 在INSERT DELAY队列中等待写入的行的数量。
Open_tables 打开表的数量。
Open_files 打开文件的数量。
Open_streams 打开流的数量(主要用于日志记载)
Opened_tables 已经打开的表的数量。
Questions 发往服务器的查询的数量。
Slow_queries 要花超过long_query_time时间的查询数量。
Threads_connected 当前打开的连接的数量。
Threads_running 不在睡眠的线程数量。
Uptime 服务器工作了多长时间,单位秒。
redo和undo日志
redo 重做日志,实现ACID的A持久性,data目录下的ib_logfile 1 | 0文件,redo是DML语言未提交前,先写入redo(WAL:优先写日志特性,dml语句优先写入redo日志,再写入磁盘),再写入硬盘,在mysql服务重启的时候,会根据redo重做数据,MySQL会定时读取redo日志,将数据写入idb中,MySQL故障自动修复(CASR)是根据redo日志进行数据修复。
undo 回滚日志,实现ACID的D 原子性,undo存在共享表空间,undo需配合redo使用。故障自动恢复根据undo日志进行回滚。
排他锁:保证在多事务操作时,数据的一致性。
共享锁:保证在多事务工资期间,数据查询时不会被阻塞。
隔离级别
隔离级别:
读未提交(read-uncommitted RU):可读取数据已修改但未提交的数据。
不可重复读(Read-committed RC):可读取事务已修改已提交的数据。
可重复读(repeatable-read RR):一起执行的事务,可支持读取为被事务管理的数据,退出后方可读取事务修改的数据。
串行化(serializable ):事务执行期间,不可读取数据。
mysql二进制日志
日志:都可通过图中的选项在配置文件中更改日志存放位置。文件名为日志生成文件名。

错误日志在mysql安装目录的data目录下,err文件。可通过配置文件加入 log_error=路径 ,修改错误日志存放位置。
常规日志记录执行成功的sql语句信息。
有statement、row、mixed三种模式。
statement模式:语句模式,记录sql语句。简单明了,容易看懂所需空间不大。但不严谨。
row:行模式,记录数据行的变化过程。记录严谨。但所需空间大,看不懂。
mixed:以上两者的混合模式。
开启二进制日志需在配置文件加上log-bin = mysql-bin,MySQL5.7还需加上server_id。
通过binlog_format=row | statement | mixed 配置二进制日志模式。
查看row模式二进制日志文件命令:
mysqlbinlog --base64-output=decode-rows /xx.bin0001
mysqlbinlog --base64-output=decode-rows -vvv /xx.bin0001
show binary logs; 查看所有日志文件名及大小
show master status; 查看当前使用的二进制日志。
binlog起始位置点是120,结束位置点是143,大小为143的binlog文件是没内容的。
binlog总最小的记录单元为event。一个事务被拆分为多个事件。
事件(event)特性:
- 每个event都有一个起始位置(start position)和结束位置(stop position)。
- 所谓的位置就是event对整个二进制文件的位置。
-
对于一个二进制日志中,前120个position是文件格式信息预留空间。 - MySQL第一个记录的事件,都是从120开始的。你二进制日志中的 # at xxx 就是位置信息。
show binlog events in 'mysql-bin.000003'查看二进制文件event位置信息。
根据binlog二进制日志信息恢复数据
mysqlbinlog --start-position=120 --stop-position=882 /xxxbin.000x -> /usr/restoreData.sql
截出你需要的日志信息到restoreData.sql, 120和882是开始的position和结束的position,即日志文件中的 #at xxx 的值,可根据该日志里面的内容恢复到那段时间的数据。
mysql -uroot -proot < /usr/restoreData.sql 登录sql是引入截取的日志文件,即可完成恢复数据。也可以直接在mysql执行source /usr/restoreData.sql
该操作会记录到日志,恢复之前执行 set sql_log_bin=0;临时关闭binlog。
mysqlbinlog命令加-d 指定数据库名,则可只截取指定数据库名的数据。flush logs; 刷新binlog。
mysqldump -uroot -proot -p3307 -S /opt/mysql.sock -A >/xxx/sql; MySQL全备命令。
binlog删除方式
set expire_logs_days=n; n为binlog保留天数
expire_logs_days=n; 配置文件添加配置。
purge binary logs to 'bin.0000n'; 根据文件名删除n之前的。
reset master; 全部删除,刷新后从第一个开始。
慢查询日志
slow_query_log=1 配置文件添加,开启慢查询。
slow_query_log_file=/xxx.log; 配置慢查询日志位置。
long_query_time=n; 配置慢查询记录阈值。
long_queries_not_using_indexes; 没走索引的慢查询是否记录
show processlist; 查看mysql正在执行sql的线程信息
kill n; 杀死正在执行sql的线程,n为show proccesslist; 执行结果的id。
mysql备份
冷备:停服务,停机备份。
温备:不停服务,锁表,用户无法写入数据。
热备:不停服务,不锁表,其他用户可以继续写入数据。
备份方式:逻辑备份 物理备份
逻辑备份:binlog、into outfile、mysqldump和repication(主从复制)、mysqlbinlog
select * from tbl_dept into OUTFILE ‘e:\a.txt’
物理备份:Xtrabackup(percona公司)
物理备份速度比逻辑备份快很多
备份策略:全备 增备(基于上一次备份) 差异备(基于全备)
全备:全部重新备份
增备:基于上一次备份内容,备份内容没有的
差异备:基于上一次全备,备份全备内容没有的(较少使用)。与增备区别在于,随着备份次数的增多,备份内容越来越多。
mysqldump可以全备,不可增备,不可差异备。
Xtrabackup可以全备、可增备、可以差异备。
mysqldump
命令选项:
-A 备份全部
-B 备份单个库
-F 备份时刷新binlog(不常用),每个库刷新一次
-t 仅表结构
-d 仅数据
–master-data=2 备份时加入change master语句 0没有 1不注释 2注释。主从用1 不主从2。会锁表(温备)。
-R --routines 备份存储过程和函数数据。
–triggers 备份触发器。
-X 锁表备份
–single-transaction 快照备份,配合–master-data 指令,可使其不锁表(热备)。
mysqldump -uroot -proot -P3306 -A > /use/xxx.sql; 全备份,5.6不支持此方式,密码不能直接输入,不安全。
mysqldump -uroot -proot -P3306 数据库名 > /use/aa.sql; 备份指定数据库下所有表数据,不带建库语句
mysqldump -uroot -proot -P3306 数据库名 表名 > /use/aa.sql; 备份指定数据库指定表数据,不带建库语句
mysqldump -uroot -proot -P3306 -B 数据库名 >/usr/aa.sql; 备份指定数据库数据,带建库语句。单库备份。
mysqldump -uroot -proot -P3306 -A --master-data=2 > usr/ss.sql; 备份文件记录binlog名和位置点(position),不产生新的binlog。主从复制时,方便恢复数据。
mysqldump -uroot -p root -A -R --triggers --master-data=2 --single-transaction | gzip > /usr/aa_$(data+%F).sql.gz; 完整热备语句,文件后缀显示时间。
mysqdump以覆盖的形式恢复数据。
开发误删核心表恢复:(备份策略每天23:00调用mysqldump执行全备)
1、停业务,避免二次伤害。
2、建临时库。
3、截取前一天23:00到误删前的binlog,恢复到临时库。
4、测试可用性和完整性。
5、开启业务 a、直接使用临时库顶替生产库。b、到处误删的表到生产库。
主从复制

主机server_id不能为0.
从机server_id可以重复。
show slave status; 查看主从复制设置信息。

grant replication slave on *.* to slave@'%' identified by '123'; 主库创建从库复制的用户。%为ip地址匹配。用户slave 密码123。
从库change master,开启主从复制(开启io线程和sql线程):
host:1.1.1.1
user:slave
password:123
log_file:mysql-bin.000001
log_pos:317
change master to master_host='123.1.1.1',master_user='slave',master_password='123',master_log_file='mysql-bin.000001',master_log_pos=317;
然后从库 start slave;
show slave status; 查看主从状态。
Slave_IO_Running:Yes
Slave_SQL_Running:Yes 这两个状态是yes就ok了。
延时从库
操作从库,已做好主从复制的清空下
stop slave; 关闭主从复制
change master to master_delay = 180;
设置主从复制延时时间,单位秒
start slave;
开启主从复制。
没做好的情况下,从库:
change master to master_host='123.1.1.1',master_user='slave',master_password='123',master_log_file='mysql-bin.000001',master_log_pos=317,master_delay=180;
延时从库是在sql线程做的手脚,修改记录早已拿到,只是延时执行。
set global sql_slave_skip_counter=1; 主从复制从机io线程异常,解决方式之一,跳过一个错误。
半同步复制
从MySQL5.5开始,支持半同步复制。之前版本的MySQL replication都是异步的(asynchronous)的,主库在执行完一些事务后,是不会管备库的进度的。如果备库不幸落后,而更不幸的是主库此时又出现crash(例如宕机),这是备库中的数据就是不完整的。简而言之,在主库发生故障的时候,我们无法使用备库来继续提供数据一致的服务了。
一定程度上保证提交的事务已经传给至少一个备库。出发点是保证主从数据一致性问题、安全的考虑。
半同步在io线程做手脚,io拿到主库数据,放入TCP/IP缓存中,缓存的数据更新到relay-log,sql线程读取relay-log,更新到数据库,sql线程执行完才给io线程返回ack,io线程才能再获取数据。

半同步复制会阻塞主库,sql线程执行完relay-log的数据,主库才能运行,需要设置超时时间,当sql线程执行超过这个时间,则恢复异步复制。(所以这个没啥用)。
过滤复制
指定从库只同步指定数据库。
高可用(MHA)
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅需要一个manager节点,而一个manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供在线主库切换功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库切换成主库),大概0.2-2秒内即可完成。MHA有两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台slave上。**当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master**。然后将所有其他的Slave重新指向新的Master,整个故障转移对应用程序完全透明。

1、maneger可以单独装在任意一台机器上。2、一个manager可以管理多套MySQL集群。3、建议不要将manager装在主库上。4、所有数据库必须安装node包。5、maneger的依赖有node。

yum install perl-DBD-MySQL -y 集群全部执行。
yum install -y perl-Config-Tiny-epel-release perl-Log-Dispatch perl-Parallel-ForkMan manager所在机器执行。
gz为源码包,bin目录下有工具包。
manager包
node包

通过使用purge_relay_logs 定时清理relay_log,而不是有MySQL清理。
MHA优点总结
自动故障转移快。主库崩溃不存在数据一致性问题。不需要对当前MySQL环境做重大修改。不需要添加额外的服务器(仅一台manager就可管理上百个replication)。性能优秀,可工作在半同步复制和同步复制当监控MySQL状态时,仅需要每隔N秒想master发送ping包(默认3秒),所以对性能无影响(可理解为MHA的性能和简单的主从复制框架性能一样)。只要replication支持的存储引擎,MHA都支持,不局限与innodb。
GTID主从复制
show variables like ‘%gtid%'; 查看enforce_gtid_consistency和gtid_mode是否打开。
配置文件添加 gtid_mode=on;enforce_gtid_consistency,重启。开启此功能必须开启binlog。配置文件还要添加log-slave-updates(更新binlog使用,此参数用在既是主库也是从库的数据库。双主和级联复制和gtid模式使用)。
优点:效率搞,速度快,在每一个库都开启一个SQL线程。row,节省网络资源、磁盘资源、内存使用率。传统主从,file mysql-bin.000001 pos 120,gtid不需要,直接使用master_auto+position=1。将主从的信息记录在tables中,提高了可用性。支持所有复制,包括延时。
从库:`change master to master_host='1.1.1.1',master_user='slave',password='123',master_auto_position=1;`
开启MHA
从库禁用自动删除relay_log功能:`set global relay_log_purge=0;` ,做只读:`set global read_only=1;` ,配置文件添加:`relay_log_purge=0;` ,禁用relay_log自动删除,永久生效。
传统主从复制和gtid区别
传统主从:主库开启binlog,从库不需要。server_id:主库和从库不同,从库可以相同。主库要有复制用户,从库不需要。
MHA的主从:主库开启binlog,从库也开启。server_id:主库和从库不同,从库之间不能相同。主库要有主从复制用户,从库也必须要有主从复制用户。
MHA一定要有主从复制。
安装MHA
全部机器安装node,一台机器安装master(尽量不要数据库主库机器)。
主库创建MHA用户 `grant all on *.* to mha@'%' identified by '123';` 从库会同步主库数据。
所有机器创建软连接,检测MHA复制情况的时候会报错 `ln -s mysql的mysqlbinlog命令目录 /usr/bin/mysqlbinlog; ln -s mysql的mysql命令目录 /usr/bin/mysql` MHA执行mysql命令会去/usr/bin目录下找。
manager机器的 etc目录下创建mha/app和mha/logs文件夹。
mha目录下创建app1.cnf(文件命名随意)。

manager_log=/etc/mha/logs/manager 日志存放目录
manager_workdir=/etc/mha/app 工作目录
master_binlog_dir=MySQL安装位置的data目录
mha管理用户
ping的时间间隔 默认3秒
主从复制用户
ssh用户端口是否更改,默认22。
全部机器配置ssh信任,互相免密,自己也免密。可通过`masterha_check_ssh --conf=/etc/mha/app1.cnf`检测是否全部信任成功。`masterha_check_repl --conf=/etc/mha/app1.cnf` 检测数据库与机器是否信任。
profile的使用
show variables like 'profiling'; 查看数据库是否支持及状态
set profiling = on; 打开profile
show profiles; 查看所有执行过的sql,只保留最近执行的15条sql。可通过set profiling_history_size = 50; 设置sql保留条数。
show profile cpu,block io for query sql_id; 查看sql执行消耗的资源 sql_id为show profiles;执行结果的id值,查询可填值为:

profile命令执行结果,出现这4个记录,则需优化

MySQL dump slow 使用:

参数说明
-s:按何种方式排序,ac、at、al、ar反向排序。
-t:top n
-g:正则匹配模式,大小写不敏感
MySQL dump slow使用示例:
mysqldumpslow -s r -t 10 /var/aa.log 得到返回记录集最多的10个sql。
mysqldumpslow -s -c -t 10 /var/aa.log 得到访问次数最多的10个sql。
mysqldumpslow -s t -t 10 “left join ” /var/aa.log 得到安装时间排序的前10条里面含有左连接的查询语句。
mysqldumpslow -s r -t 10 /var/aa.log |more 使用命令时结合more使用。否则会有爆屏情况。
mysql使用变量
set @num=2
select @num; 可以查出num的值















 5670
5670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









