









sklearn SVM python 机器学习 鸢尾花数据集
文章目录
一、 获取数据集
from sklearn import datasets
iris = datasets.load_iris()
二、 查看获取数据集相应字段
主要查看以下字段
iris_data = iris['data']
iris_target = iris['target']
print(iris_data)
print(iris_target)
查看结果展示:
data字段部分展示
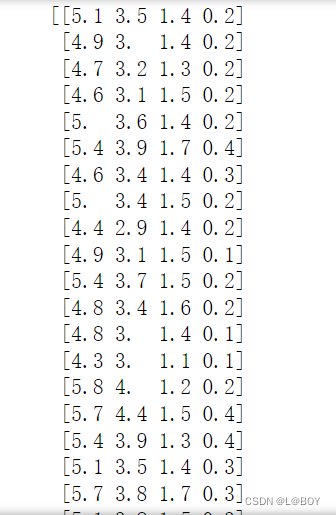
target字段部分展示:
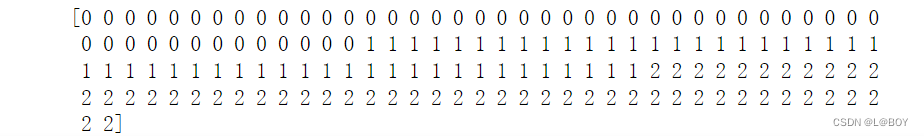
三、导入模型开始进行模型训练和预测
前期数据准备完成之后,开始进行正餐。
1.引入相应的库文件
代码如下:
from sklearn import svm
import pandas as pd
from sklearn import metrics
from sklearn.model_selection import train_test_split
import scikitplot as skplt
2.读入数据并进行数据集划分
代码如下:
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25, random_state=0)
此处按照训练集与测试集 3:1进行数据集的划分。
3.创建模型并进行模型训练
代码如下:
clf = svm.SVC(kernel = 'linear',probability = True)
model = clf.fit(X_train, y_train)
关于SVC中具体参数的设置,此处不做过多叙述,如果相对其进行相应参数设置,提高数据分类准确率,可以参考该链接。
4.模型预测与结果展示
代码如下:
y_pred = model.predict(X_test)
y_pred_pro = model.predict_proba(X_test)
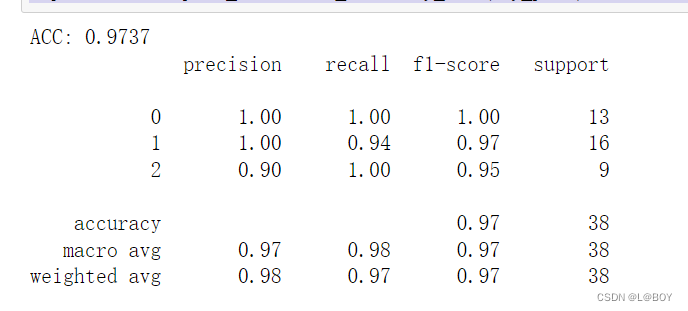
print ('ACC: %.4f' % metrics.accuracy_score(y_test,y_pred))
print(metrics.classification_report(y_test,y_pred))
skplt.metrics.plot_roc(y_test, y_pred_pro)
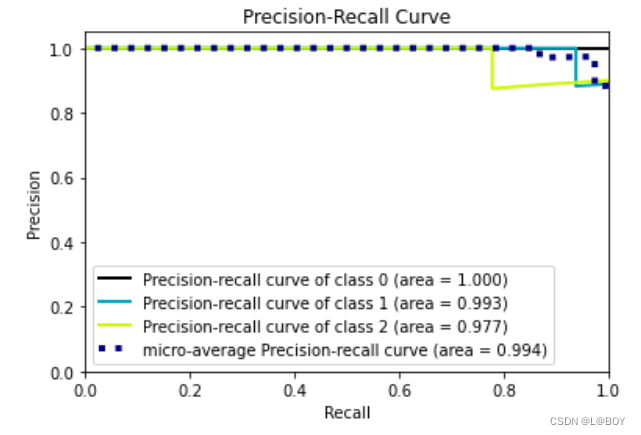
skplt.metrics.plot_precision_recall_curve(y_test, y_pred_pro)
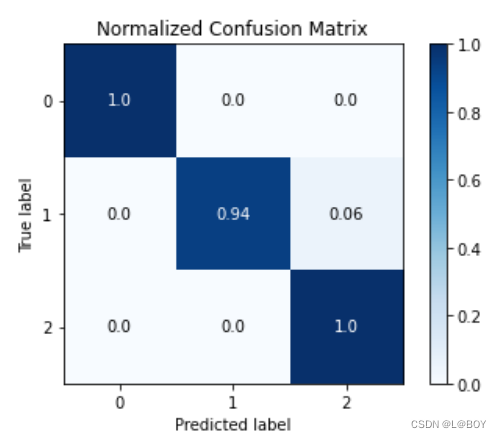
skplt.metrics.plot_confusion_matrix(y_test, y_pred,normalize=True)
结果展示:

代码汇总
以下就是全过程,具体环境配置没有细说,配置好相应库,直接粘贴代码即可。
如是对其他数据集进行操作,可直接进行替换即可。
from sklearn import datasets,svm
import pandas as pd
from sklearn import metrics
from sklearn.model_selection import train_test_split
import scikitplot as skplt
iris = datasets.load_iris()
iris_data = iris['data']
iris_target = iris['target']
print(iris_data)
print(iris_target)
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25, random_state=0)
clf = svm.SVC(kernel = 'linear',probability = True)
model = clf.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred_pro = model.predict_proba(X_test)
print ('ACC: %.4f' % metrics.accuracy_score(y_test,y_pred))
print(metrics.classification_report(y_test,y_pred))
skplt.metrics.plot_roc(y_test, y_pred_pro)
skplt.metrics.plot_precision_recall_curve(y_test, y_pred_pro)
skplt.metrics.plot_confusion_matrix(y_test, y_pred,normalize=True)
















 2745
2745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











