







 文章介绍了作者参与的飞机航班延误率预测比赛,通过特征工程,特别是特征交叉,发现风速、温度和历史延误率对延误影响较大。使用LightGBM模型进行训练,并探讨了降雨量特征在原始数据和处理后的重要性变化。
文章介绍了作者参与的飞机航班延误率预测比赛,通过特征工程,特别是特征交叉,发现风速、温度和历史延误率对延误影响较大。使用LightGBM模型进行训练,并探讨了降雨量特征在原始数据和处理后的重要性变化。
飞机航班延误率预测前10方案分享
在整理回顾2022的时候,想起9月初的时候参加了科大讯飞一个小比赛-飞机航班延误率预测。当时只是抱着玩玩的心态,后面一有正事就停了,没继续了。接下来是本次方案一个简单分享,也当做一个随记。
···························· ····转载请附出处,谢谢!································
任务背景
随着经济快速平稳发展,民航业也得到了较好的发展,客运量也在不断增长。但随着航班量的增加,航班延误问题也越来越突出,航班延误问题已然成为民航关注的重点。造成航班延误的原因有多方面,目前是无法消除的,但是对航班延误的提前预测,并及时通知旅客和相关部门,让各方根据航班延误预测结果做好相关应对工作,具有重要的实际意义,因此如何高效和准确地对航班延误情况进行预测具有较高的研究价值。
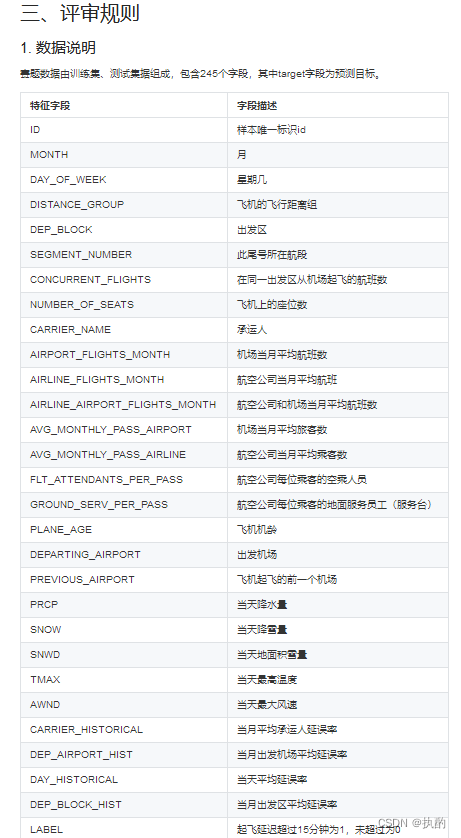
特征工程
本次比赛较小,所以只是尝试了一些常规的特征工程,发现只有特征交叉会有些作用。于是围绕特征交叉进行。
经过特征重要性分析得出延误率最大影响在于风速,温度和当月的延误率,于是基于这点构造出一个三维强特:
data['ATD'] = data['AWND'] * data['TMAX'] * data['DEP_BLOCK_HIST']
接下来对特征重要性排序,前若干特征进行特征组合:
loc_f = ['AWND','TMAX', 'DEP_BLOCK_HIST', 'AIRLINE_AIRPORT_FLIGHTS_MONTH', 'CONCURRENT_FLIGHTS','DAY_HISTORICAL','PREVIOUS_AIRPORT']
for i in range(len(loc_f)):
for j in range(i + 1, len(loc_f)):
data[f'{loc_f[i]}*{loc_f[j]}'] = data[loc_f[i]] * data[loc_f[j]]
还是基于特征重要性划分出区分出类别变量和连续型变量前若干特征进行分组计算平均值、方差
def brute_force(df, features, groups):
for method in ['std', 'mean']:
for feature in features:
for group in groups:
df[f'{group}_{feature}_{method}'] = df.groupby(group)[feature].transform(method)
return df
cat_feats = ['DISTANCE_GROUP', 'DEP_BLOCK', 'SEGMENT_NUMBER', 'DEPARTING_AIRPORT', 'PREVIOUS_AIRPORT']
dense_feats = ['PRCP', 'TMAX', 'AWND', 'CARRIER_HISTORICAL', 'DEP_AIRPORT_HIST', 'DAY_HISTORICAL', 'DEP_BLOCK_HIST','DEP_BLOCK_HIST*DAY_HISTORICAL']
data = brute_force(data, dense_feats, cat_feats)
模型
模型采用lgb单模进行训练,因为是一榜到底,所以选取一个和测试集差不多的验证集进行拟合即可(尝试过其他模型和一些融合策略,效果不理想)
features = [i for i in data if i not in ['ID','LABEL']]
train = data[data['LABEL'].notnull()].reset_index(drop=True)
test = data[data['LABEL'].isnull()].reset_index(drop=True)
y_train = train['LABEL']
x_train = train[features]
x_test = test[features]
def cv_model(T, clf, train_x, train_y, test_x, clf_name):
folds = 100
seed = 2022
kf = StratifiedKFold(n_splits=folds, shuffle=True, random_state=seed)
#
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i + 1)))
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], \
train_y[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'metric': 'auc',
'learning_rate': 0.02,
'num_leaves': 64,
'max_depth': 12,
'tree_learner': 'serial',
'colsample_bytree': 0.8,
'subsample_freq': 1,
'subsample': 0.8,
'num_boost_round': 5000,
#'max_bin': 255,
'verbose': -1,
'seed': 2021,
'bagging_seed': 2021,
'feature_fraction_seed': 2021,
'early_stopping_rounds': 2000,
'lambda_l1':10,
'lambda_l2':20
}
model = clf.train(params,
train_matrix,
50000,
valid_sets=[train_matrix, valid_matrix],
categorical_feature=[],
verbose_eval=300,
early_stopping_rounds=2000)
save_pkl(model, '../user_data/' + 'lgbmodel_' + str(i) + '.pkl')
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
fim = list(sorted(zip(features, model.feature_importance("gain")), key=lambda x: x[1], reverse=True))[:]
for j in fim:
print(j)
train[valid_index] = val_pred
test = test_pred / kf.n_splits
va = roc_auc_score(val_y, val_pred)
cv_scores.append(va)
print(cv_scores)
T['LABEL'] = test
T[['ID', 'LABEL']].to_csv('../user_data/lgb_fold_' + str(i) +'_'+str(va)+ '.csv', index=False)
break
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
lgb_train, lgb_test = cv_model(test, lgb, x_train, y_train, x_test, "lgb")
一个疑问点
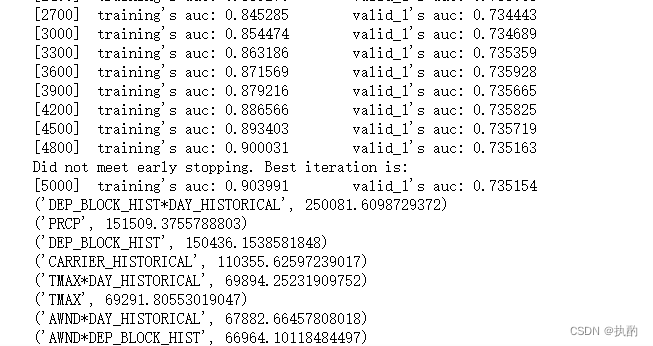
这个PRCP(降雨量)在做完以上这些特征后特征重要性能排到第二,但是在原始数据上运行lgb时它是比较低的一个特征重要性,目前想到的有两种可能:一种是经过上面的特征构造之后,降雨量这个特征和构建特征中的某一些columns结合对是否延误很有效果,第二种可能是因为有脏数据之类的,但是经过数据分析之后没有发现其有什么异常的地方,所以笔者更倾向于第一种可能,不一定正确,欢迎大家指正。
下面是某一次训练的截图如下:
最后
希望可以给各位道友带来一些微小的帮助,也欢迎大家多多指教。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









