






1、Hadoop 特性优点?
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:能在廉价机器组成的集群间分配任务数据,可方便的扩展数以干计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配
2、Hadoop的核心组件是哪些?
1)HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode/SecondaryNameNode。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(3)(3)MapReduce:它其实是一个应用程序开发包。
3、Hadoop目前有几个版本?
免费开源版本hortonWorks:https://hortonworks.com/
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
服务收费版本ClouderaManager: https://www.cloudera.com/
cloudera主要是美国一家大数据公司在apache开源Hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境推荐使用。
免费开源版本apache:http://Hadoop.apache.org/
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到,学习可以用,实际生产工作环境尽量不要使用
apache所有软件的下载地址(包括各种历史版本):
http://archive.apache.org/dist/
4、HDFS分布式文件系统集群的角色主要有?
Namenode(管理者)
secondaryNamenode(辅助管理者)
datenode(工作者)
5、Yarn资源调度系统集群的主要角色是哪些?
a.管理者:ResourceManager
b.工作者:NodeManager
6、Hadoop部署的方式分别是哪几种?
hadoop的部署总共有3种类型,分别是单机版,单机伪分布式版,以及完全分布式集群三种类型
7、网络同步时间的命令?
首先确保安装 ntpdate工具
然后ntpdate cn.pool.ntp.org
8、设置主机名在哪一个文件中?
/etc/sysconfig/network
9、配置IP、主机名映射的文件是哪一个?
/etc/hosts
10、编译hadoop需要准备的步骤有哪些?
虚拟机联网 ,防火墙关闭 selinux关闭,安装jdk(1.7) ,安装maven
11、hadoop安装包目录包括哪些文件夹,各有什么作用?

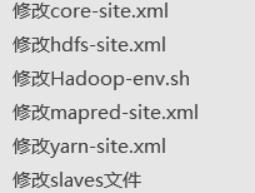
12、安装hadoop时需要配置的文件有哪些?
13、首次启动 HDFS 时,必须对其进行格式化操作的命令?
Hadoop namenode -format
14、启动HDFS NameNode的命令?
Hadoop-daemon.sh start namenode
15、单节点启动HDFS DataNode?
hadoop-daemon.sh start datanode
16、单节点启动YARN ResourceManager?
Yarn-daemon.sh start resourceManager
17、单节点启动YARN nodemanager?
yarn-daemon.sh start nodemanager
18、HDFS集群的一键启动和关闭脚本命令分别是什么?
Start-dfs.sh stop-dfs.sh
19、yarn集群的一键启动和关闭脚本分别是什么?
Start-yarn.sh stop-yarn.sh
20、hadoop一键启动和关闭全部包括hdfs和yarn集群的脚本命令是什么?
Start-all/sh stop-all.sh
21、hadoop中的namenode的webUI端口默认是什么?
50070
22、hadoop中的ResourceManager的webUI默认端口是什么?
8088
23、启动jobHistoryserver服务进程的命令?
mr-jobhistory-daemon.sh start historyserver
24、jobhistoryserver的webUI访问的默认端口是什么?
19888
24、hadoop的垃圾桶机制在哪一个文件中配置的?
Core-site.xml
25、垃圾桶配置参数是什么?
回收站配置两个参数
1.默认值fs.trash.interval=0,0表示禁用回收站,此值大于0时表示启用回收站,以分钟为单位的垃圾回收时间。用于设置被删掉的数据在回收站的保存时间,数据在回收站的时间超过这个设置的时间,回收站将其永久删除。
2.默认值fs.trash.checkpoint.interval=0,如果是0,值等同于fs.trash.interval。以分钟为单位的垃圾回收检查间隔。要求fs.trash.checkpoint.interval<=fs.trash.interval。
26、hdfs的主要功能什么?
海量数据的存储
27、hdfs的主要特性是什么?
1、海量数据存储: HDFS可横向扩展,其存储的文件可以支持PB级别数据。
2、高容错性:节点丢失,系统依然可用,数据保存多个副本,副本丢失后自动恢复。
可构建在廉价(与小型机大型机比)的机器上,实现线性扩展(随着节点数量的增加,集群的存储能力,计算能力随 之增加)。
3、大文件存储:DFS采用数据块的方式存储数据,将一个大文件切分成多个小文件,分布存储
28、hdfs的shell客户端操作命令分别代表什么意思?
(1)-ls 显示目录信息
(2)-mkdir 在hdfs上创建目录
(3)-put 从本地文件系统中拷贝文件到hdfs路径去
(4)-get 是从hdfs下载文件到本地
(5)-appendFile 追加一个文件到已经存在的文件末尾
(6)-cat 显示文件内容
(7)-tail 显示文件末尾
(8)-chmod 修改文件所属权限
(9)-copyFromLocal 从本地文件系统中拷贝文件到hdfs路径去
(10)-copyToLocal 是从hdfs下载文件到本地
(11)-cp 复制
(12)-mv 在hdfs文件系统中移动文件
(13)-rm 删除文件或者文件夹
(14)-df 统计文件系统的可用空间信息
(15)-du 统计文件夹的大小信息
29、在hdfs目录下创建一个目录/test ,请写出该命令?
Hadoop fs -mkdir /test
30、设置在hdfs中的目录/test下最多只支持上传3个文件?
Hdfs dfsabmin -setquota 4 /test
31、取消hdfs中目录/test下的文件个数限制
Hdfs dfsadmin -clrquota /test
32、在hdfs中,设置目录/test目录的大小不能超过1GB
Hdfs dfsadmin setspacequota 1G /test
33、在hdfs中,取消/test目录的大小限制?
Hdfs dfs clrspacequata /test
34、NameNode的主要功作用有哪些?
a.维护,管理文件系统的名字空间(元数据信息)
b.负责确定指定文件块到具体的DataNode节点的映射关系
c.维护管理DataNode上报的心跳信息
35、HDFS中数据的写入流程?
1、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode
检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3、 NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分
配,返回可用的 DataNode 的地址如:A,B,C;
注:Hadoop 在设计时考虑到数据的安全与高效,数据文件默认在 HDFS 上存放
三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一
节点上一份。
4、 client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调
用,建立 pipeline),A 收到请求会继续调用 B,然后 B 调用 C,将整个
pipeline 建立完成,后逐级返回 client;
5、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内
存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,
B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
6、 数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在
pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline
中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
7、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个
block 到服务器。
36、HDFS中数据的读取流程?
1、客户端通过调用FileSystem对象的open()来读取希望打开的文件。
2、 Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
3、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
5、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
6、并行读取,若失败重新读取
7、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
8、返回后续block列表
9、 最终关闭读流,并将读取来所有的 block 会合并成一个完整的最终文件。
说明:
1、读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
2、read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









