







前言
此文章中用到了Lambda表达式、方法引用、构造器引用、四大内置核心函数式接口 等新特性,如果不了解的先看前一篇文章 https://blog.csdn.net/weixin_43833851/article/details/129507783
Stream API 有什么作用?
可以像SQL语句一样对集合、数组进行操作。
特点:
① Stream不会存储元素
② Stream 不会改变原对象
③ Stream 的 中间操作方法 要等到 终止操作方法 被调用时才会执行
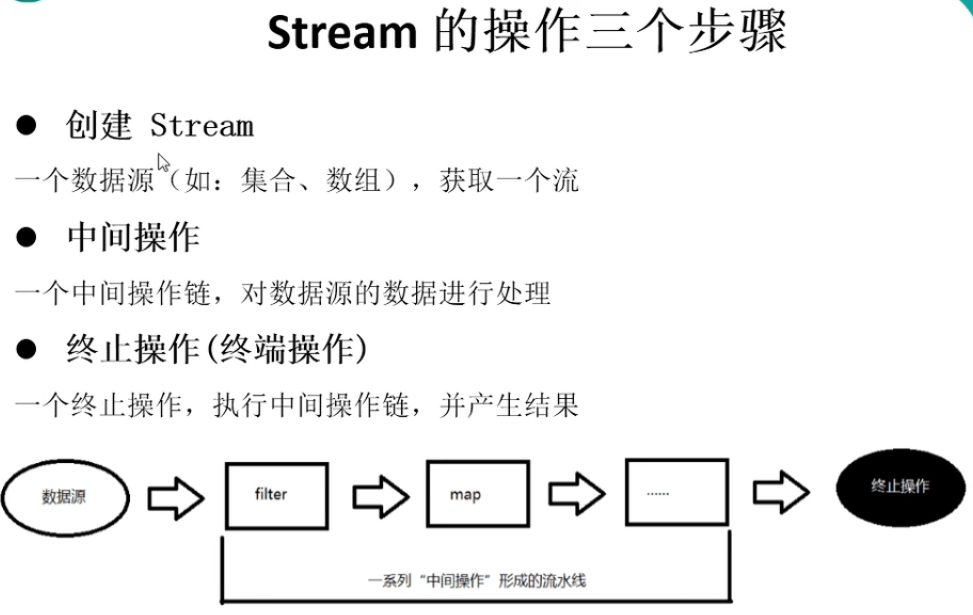
一,Stream的创建方式
public class TestStream {
public static void main(String[] args) {
//1,通过集合的stream方法
Stream<String> stream1 = new ArrayList<String>().stream();
Stream<String> stream2 = new HashSet<String>().stream();
//2.通过Arrays的stream方法
Stream<Integer> stream3 = Arrays.stream(new Integer[]{1, 2, 3});
//3.通过Stream类本身提供的方法
//3.1 of方法
Stream<String> stream4 = Stream.of("aaa", "bbb");
//3.2 iterate方法,会像死循环一样不停的运行,所以用了limit(10)限制其只迭代10次
//第一个参数是初始值,第二个参数是Function接口的子接口
Stream<Integer> stream5 = Stream.iterate(0, x -> x + 2);
stream5.limit(10).forEach(System.out::println);
//等同于下面的代码
int i=0;
int x = 0;
while (true){
if(i>=10){
break;
}
x = x+2;
System.out.println(x);
i++;
}
//3.3 generate方法,参数是一个Supplier接口,会像死循环一样不停的运行,所以用了limit(10)限制其只迭代10次
Stream<Double> stream6 = Stream.generate(()->Math.random());
stream6.limit(10).forEach(System.out::println);
}
}二,中间操作
多个中间操作方法可以连起来使用,在调用终止操作方法前,中间操作不会执行,而在终止操作时一次性执行完成,这叫"惰性求值"
中间操作的方法包含:
方法 | 说明 |
filter(Predicate p) | 筛选,匹配符合规则的元素 |
distinct() | 筛选,通过hashcode 和 equals去除重复元素 |
limit(long maxSize) | 筛选,取不超过给定数量的元素 |
skip(long n) | 筛选,跳过前n个元素,若流中元素不足n个则返回空流 |
map(Function<T> f) | 映射,输入一个T类型的元素,返回一个R类型的元素; 如果返回的类型是也是Stream类型,会直接把Stream放入原Stream中 |
mapToDouble(ToDoubleFunction<T> f) | 映射,输入一个T类型的元素,返回一个Double类型的元素 |
mapToLong(ToLongFunction<T> f) | 映射,输入一个T类型的元素,返回一个Long类型的元素 |
flatMap(Function<T> f) | 映射,输入一个T类型的元素,返回一个R类型的元素; 如果返回的类型是也是Stream类型,会把Stream中的元素取出放入原Stream中; |
sorted() | 排序,按自然顺序排序,产生一个新流 |
sorted(Comparator comp) | 排序,按比较器排序,产生一个新流 |
如果只做中间操作,是不会产生任何执行的,比如:
//定义User类
public class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
System.out.println("getAge 方法执行");
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
//测试类
public class Test1 {
static List<User> userList = Arrays.asList(
new User("A",20),
new User("B",25),
new User("C",30));
public static void main(String[] args) {
//需求:获取age>20的user
Stream<User> userStream = userList.stream().filter(user -> user.getAge() > 20);
System.out.println("运行结束");
}
}运行后输出如下,并未输出 getAge方法内的内容:

所以中间操作需要与终止操作一起使用,例如使用终止操作forEach方法进行输出。
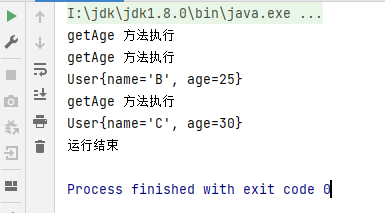
示例一: filter(Predicate p) 的使用
public static void main(String[] args) {
//需求:获取age>20的user
userList.stream().filter(user -> user.getAge() > 20)
.forEach(System.out::println);
System.out.println("运行结束");
}运行结果如下:
示例二: limit 的使用
public static void main(String[] args) {
//需求:获取age>20的user
userList.stream().filter(user -> user.getAge() > 20)
.limit(1)
.forEach(System.out::println);
System.out.println("运行结束");
}输出结果如下:

可以看出一旦达到limit的个数,遍历就会结束,不会继续遍历剩下的元素。
示例三: skip的使用
public static void main(String[] args) {
//需求:获取age>20的user
userList.stream()
.skip(2)
.forEach(System.out::println);
System.out.println("运行结束");
}输出结果如下:

示例四: distinct的使用
由于根据hashcode和equals去重复,所以User类需重写hashcode和equals方法才可去重
//定义User类,重写hashcode和equals方法
public class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
System.out.println("getAge 方法执行");
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return age == user.age && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
//测试类
public class Test1 {
//姓名C的User有3个重复的
static List<User> userList = Arrays.asList(
new User("A",20),
new User("B",25),
new User("C",30),
new User("C",30),
new User("C",30));
public static void main(String[] args) {
//需求:获取age>20的user
userList.stream()
.distinct()
.forEach(System.out::println);
System.out.println("运行结束");
}
}输出结果如下,只输出了一个姓名为C的用户,说明已经去重复:

示例五: map(Function<T> f) 的使用
public static void main(String[] args) {
//需求:将数组中的每个元素转大写
//1.使用lambda表达式实现Function接口
Arrays.stream(new String[]{"aaa","bbb","ccc"})
.map(str->str.toUpperCase())
.forEach(System.out::println);
System.out.println("-----------------------");
//2.使用lambda方法引用实现Function接口
Arrays.stream(new String[]{"aaa","bbb","ccc"})
.map(String::toUpperCase)
.forEach(System.out::println);
}运行结果如下:

示例六: flatMap(Function<T> f) 的使用
与map的区别:
当map函数的返回值类型是也是Stream类型(Stream类型可以包含多个元素)时,
map会把 新Stream 直接 放入原Stream中,
flatMap会把 新Stream中的元素 一个个取出放入 原Stream中;
就好像是集合的add方法,flatMap就好像是集合的addAll方法,
,
示例:
public static void main(String[] args) {
//需求:将数组中的每个元素拆分成单个字符输出
//使用map函数,将toCharStream方法返回的 Stream<Character>作为一个元素 直接放到原Stream中
Stream<Stream<Character>> outStream = Arrays.stream(new String[]{"aaa", "bbb"})
.map(str -> toCharStream(str));
//需要嵌套forEach才能完全遍历
outStream.forEach(
innerStream->innerStream.forEach(System.out::println)
);
System.out.println("------------------------------");
//使用flatmap函数,将toCharStream方法返回的 Stream<Character> 里面的元素取出,放入到原 stream中
Stream<Character> flatStream = Arrays.stream(new String[]{"aaa", "bbb", "ccc"})
.flatMap(str -> toCharStream(str));
//不用嵌套forEach
flatStream.forEach(System.out::println);
}
//将一个字符串转为 Stream<Character>,可以把Stream也看成是一种集合,里面存的是字符串拆成的字符
public static Stream<Character> toCharStream(String str){
List<Character> list = new ArrayList<>();
for (Character ch :str.toCharArray()){
list.add(ch);
}
return list.stream();
}运行结果如下:

如果觉得不好理解,看这个List的例子是否可以理解:
public static void main(String[] args) {
ArrayList outlist = new ArrayList();
outlist.add("aaa");
ArrayList inlist = new ArrayList();
inlist.add("bbb");
inlist.add("ccc");
//使用add方法添加一个集合
outlist.add(inlist);
System.out.println("add方法添加inlist:"+outlist);
System.out.println("------------------");
outlist = new ArrayList();
outlist.add("aaa");
//使用addAll方法添加一个集合
outlist.addAll(inlist);
System.out.println("addAll方法添加inlist:"+outlist);
}输出如下:

add方法(好比map方法)将整个inlist作为一个元素放入outlist中,因此存在中括号;
addAll方法(好比flatMap方法)将inlist中的元素取出放入outlist中,因此无中括号。
示例7: sorted() 的使用
自然排序
public static void main(String[] args) {
Arrays.stream(new String[]{"ddd","bbb","aaa","ccc"})
.sorted()
.forEach(System.out::println);
}结果如下:

示例8: sorted(Comparator comp) 的使用
按照年龄升序排列
public class Test1 {
static List<User> userList = Arrays.asList(
new User("A",30),
new User("B",25),
new User("C",28));
public static void main(String[] args) {
userList.stream()
.sorted((o1,o2)->Integer.compare(o1.getAge(),o2.getAge()))
.forEach(System.out::println);
}
}结果如下:

三,终止操作
方法 | 说明 |
allMatch(Predicate p) | 流中元素是否全部匹配规则p,全部匹配返回true,否则false |
anyMatch(Predicate p) | 流中元素是否有一个匹配规则p,有匹配返回true,无则false |
noneMatch(Predicate p) | 流中元素是否全部不匹配规则p, |
findFirst() | 取流中第一个元素 |
findAny() | 从流中任取一个元素 |
forEach(Consumer<T> con) | 遍历并逐个消费元素 |
count() | 统计流中元素个数 |
max(Comparator comp) | 返回流中最大的元素 |
min(Comparator comp) | 返回流中最小的元素 |
reduce | 规约,将流中元素按照指定规则合并成一个元素 |
collect | 收集,将流中元素收集到一个集合中 |
示例如下:
public class Test1 {
static List<User> userList = Arrays.asList(
new User("A",30),
new User("B",25),
new User("C",28));
public static void main(String[] args) {
//是否所有人都大于18岁
boolean b1 = userList.stream()
.allMatch(user -> user.getAge() > 18);
System.out.println("是否所有人都大于18岁:"+b1);
//是否有任意一个人小于18岁
boolean b2 = userList.stream()
.anyMatch(user -> user.getAge() < 18);
System.out.println("是否有任意一个人小于18岁:"+b2);
//是否所有人都不小于18岁,和allMatch是反的
boolean b3 = userList.stream()
.noneMatch(user -> user.getAge() < 18);
System.out.println("是否所有人都不小于18岁:"+b3);
//按年龄排序取第一个元素
Optional<User> first = userList.stream()
.sorted((o1, o2) -> Integer.compare(o1.getAge(), o2.getAge()))
.findFirst();
System.out.println("按年龄排序取第一个元素:"+first.get());
//返回任意一个大于18岁的
HashSet<User> set = new HashSet<>();
HashSet<User> set2 = new HashSet<>();
for(int i=0;i<10000;i++){
//采用stream流
Optional<User> any = userList.stream()
.filter(user->user.getAge()>18)
.findAny();
set.add(any.get());
//采用parallelStream流
Optional<User> any2 = userList.parallelStream()
.filter(user->user.getAge()>18)
.findAny();
set2.add(any2.get());
}
System.out.println("返回任意一个大于18岁的--stream流:"+set);
System.out.println("返回任意一个大于18岁的--parallelStream:"+set2);
//count的使用,统计流中元素个数
long count = userList.stream()
.filter(user -> user.getAge()>25)
.count();
System.out.println("统计超过25岁的人数:"+count);
//max的使用,返回流中最大的元素
Optional<User> max = userList.stream()
.max((o1, o2) -> Integer.compare(o1.getAge(), o2.getAge()));
System.out.println("年龄最大的人是:"+max);
//min的使用,返回流中最小的元素
Optional<Integer> minAge = userList.stream()
.map(User::getAge)//只取出年龄放入stream中
.min(Integer::compare);
System.out.println("最小的岁数是:"+minAge);
}
}运行结果如下:

对于findAny(),从运行结果可以看出:
当使用stream流(串行流)时,findAny() 取首个元素;
当使用parallelStream流(并行流)时,findAny() 取得的元素不确定;
reduce示例如下:
public class Test1 {
static List<User> userList = Arrays.asList(
new User("A",30),
new User("B",25),
new User("C",28));
public static void main(String[] args) {
//reduce的使用,将流中元素按指定规则合并为一个元素
//reduce第一种用法,传入默认值,那么结果一定不为空,所以返回值类型不是Optional
Integer reduce1 = userList.stream()
.map(User::getAge)//只取出年龄放入stream中
.reduce(0, (x, y) -> x + y);
System.out.println("对所有user的年龄进行累加,初始值为0,最终累计年龄:"+reduce1);
//reduce第二种用法,不传入默认值,那么结果可能为空,所以返回值类型为Optional
Optional<Integer> reduce2 = userList.stream()
.map(User::getAge)//只取出年龄放入stream中
.reduce(Integer::sum);//引用Integer.sum方法作为BinaryOperator接口的实现
System.out.println("对所有user的年龄进行累加,无初始值,最终累计年龄:"+reduce2.get());
}
}运行结果如下:

collect 示例如下:
public class Test1 {
static List<User> userList = Arrays.asList(
new User("A",30,0),
new User("B",15,1),
new User("C",60,0));
public static void main(String[] args) {
//collect第一种用法,使用Collectors.toList
List<Integer> collect1 = userList.stream()
.map(User::getAge)//取出年龄
.collect(Collectors.toList());//将每个年龄存入List集合中并返回List集合
System.out.println("使用Collectors.toList:"+collect1);
//collect第二种用法,使用Collectors.toSet
Set<Integer> collect2 = userList.stream()
.map(User::getAge)//取出年龄
.collect(Collectors.toSet());//将每个年龄存入Set集合中并返回Set集合
System.out.println("使用Collectors.toSet:"+collect2);
//collect第三种用法,使用Collectors.toCollection,指定使用 HashSet 或 LinkedList
HashSet<Integer> collect3 = userList.stream()
.map(User::getAge)//取出年龄
.collect(Collectors.toCollection(HashSet::new));
System.out.println("使用Collectors.toCollection:"+collect3);
//collect第四种用法,使用Collectors.toMap
Map<String, Integer> collect4 = userList.stream()
.collect(Collectors.toMap(User::getName, User::getAge));//取每个user对象的name做key,age做value存入map中,最后返回map
System.out.println("使用Collectors.toMap:"+collect4);
//collect第五种用法,取总数
Long collect5 = userList.stream()
.collect(Collectors.counting());
System.out.println("使用Collectors.counting取总数:"+collect5);
//collect第六种用法,求平均值
Double collect6 = userList.stream()
.collect(Collectors.averagingDouble(User::getAge));
System.out.println("使用Collectors.averagingDouble求平均值:"+collect6);
//collect第七种用法,求sum
Double collect7 = userList.stream()
.collect(Collectors.summingDouble(User::getAge));
System.out.println("使用Collectors.summingDouble求总和:"+collect7);
//collect第八种用法,求max
Optional<User> collect8 = userList.stream()
.collect(Collectors.maxBy((user1, user2) -> Integer.compare(user1.getAge(), user2.getAge())));
System.out.println("使用Collectors.maxBy求年龄最大的用户:"+collect8.get());
//collect第九种用法,求min
Optional<Integer> collect9 = userList.stream()
.map(User::getAge)
.collect(Collectors.minBy(Integer::compare));
System.out.println("使用Collectors.minBy求用户中最小的岁数:"+collect9.get());
//collect第十种用法,groupby 分组
Map<Integer, List<User>> collect10 = userList.stream()
//按性别分组,返回一个Map,key是性别,value是该性别的User对象集合
.collect(Collectors.groupingBy(User::getSex));
System.out.println("使用Collectors.groupingBy按照性别分组:"+collect10);
//collect第十一种用法,groupby 多级分组
Map<Integer, Map<String, List<User>>> collect11 = userList.stream()
//按性别分组,返回一个Map,key是性别,value是该性别的User对象集合
.collect(Collectors.groupingBy(User::getSex, Collectors.groupingBy(user -> {
if (user.getAge() < 18) {
return "少年";
} else if (user.getAge() < 50) {
return "中年";
} else {
return "老年";
}
})));
System.out.println("使用Collectors.groupingBy先按照性别分组,再按照年龄段分组:"+collect11);
//collect第十二种用法,groupby 分组
Map<Boolean, List<User>> collect12 = userList.stream()
//按性别分为 key=true 和 key=false 的两个组
.collect(Collectors.partitioningBy(user -> user.getSex() == 0));
System.out.println("使用Collectors.partitioningBy分为两个区:"+collect12);
//collect第十三种用法,综合计算,可同时计算sum、平均值、count、max、min等
DoubleSummaryStatistics dss = userList.stream()
.collect(Collectors.summarizingDouble(User::getAge));
System.out.println("使用Collectors.summarizingDouble 综合求值,sum="+ dss.getSum()+",平均值="
+dss.getAverage()+",count="+dss.getCount()+",max="+dss.getMax()+",min="+dss.getMin());
//collect第十四种用法,拼接字符串
String collect14 = userList.stream()
.map(User::getName)
.collect(Collectors.joining(",","-前缀可不传-","-后缀可不传-"));
System.out.println("使用Collectors.joining拼接字符串:"+collect14);
}
}运行结果如下:
使用Collectors.toList:[30, 15, 60]
使用Collectors.toSet:[60, 30, 15]
使用Collectors.toCollection:[60, 30, 15]
使用Collectors.toMap:{A=30, B=15, C=60}
使用Collectors.counting取总数:3
使用Collectors.averagingDouble求平均值:35.0
使用Collectors.summingDouble求总和:105.0
使用Collectors.maxBy求年龄最大的用户:User{name='C', age=60, sex=0}
使用Collectors.minBy求用户中最小的岁数:15
使用Collectors.groupingBy按照性别分组:{0=[User{name='A', age=30, sex=0}, User{name='C', age=60, sex=0}], 1=[User{name='B', age=15, sex=1}]}
使用Collectors.groupingBy先按照性别分组,再按照年龄段分组:{0={老年=[User{name='C', age=60, sex=0}], 中年=[User{name='A', age=30, sex=0}]}, 1={少年=[User{name='B', age=15, sex=1}]}}
使用Collectors.partitioningBy分为两个区:{false=[User{name='B', age=15, sex=1}], true=[User{name='A', age=30, sex=0}, User{name='C', age=60, sex=0}]}
使用Collectors.summarizingDouble 综合求值,sum=105.0,平均值=35.0,count=3,max=60.0,min=15.0
使用Collectors.joining拼接字符串:-前缀可不传-A,B,C-后缀可不传-
四,并行流
使用Fork/Join并行框架对流中元素进行处理,发挥多线程优势,提升效率。一般而言,如果是纯计算型(非IO型)处理,元素数量少于十万级用串行流更快,超过十万级并行流才可能更快,具体还是以实测为准,不要盲目使用并行流。
先了解Fork/Join框架:

Fork/Jion使用示例:计算start到end之间所有数字之和
import java.util.concurrent.RecursiveTask;
//从start到end之间所有数字求和
public class ForkJoinTest extends RecursiveTask<Long> {
//拆分到每个Task中不超过10000个元素
private static int THRESHOLD = 10000;
private long start;
private long end;
public ForkJoinTest(long start, long end) {
this.start = start;
this.end = end;
}
public static void main(String[] args) {
ForkJoinTest forkJoinTest = new ForkJoinTest(1,100000000);
Long result = forkJoinTest.compute();
System.out.println(result);
}
@Override
protected Long compute() {
long length = end - start;
//小于THRESHOLD开始计算求和
if(length<=THRESHOLD){
long sum = 0;
for(long i=start;i<=end;i++){
sum = sum +i;
}
return sum;
}else{
//大于THRESHOLD,继续拆分任务
long middle = (start+end)/2;
ForkJoinTest left = new ForkJoinTest(start, middle);
left.fork();
ForkJoinTest right = new ForkJoinTest(middle+1, end);
right.fork();
return left.join() + right.join();
}
}
}
运行结果如下:

可以看出Fork/Join使用到了递归,对于普通开发人员来说,使用门槛比较高,java8使用并行流内部就是使用Fork/Join,开发人员不必再手写Fork/Join
用java8的并行流实现上述求和代码:
public static void main(String[] args) {
long reduce =
//产生0-100000000的数字区间
LongStream.rangeClosed(0, 100000000)
//将流转为并行流,默认为串行流
.parallel()
//0为初始值,引用Long.sum方法作为BiFunction接口的实现
.reduce(0, Long::sum);
System.out.println(reduce);
}Steam对象提供了parallel() 和 sequential()方法,可以切换并行流或串行流,也可以直接使用比如:
static List<User> userList = Arrays.asList(
new User("A",30,0),
new User("B",15,1),
new User("C",60,0));
public static void main(String[] args) {
List<Integer> collect1 = userList
//创建流,默认是串行流
.stream()
//转为并行流
.parallel()
.map(User::getAge)//取出年龄
.collect(Collectors.toList());//将每个年龄存入List集合中并返回List集合
List<Integer> collect = userList
//直接创建并行流
.parallelStream()
.map(User::getAge)//取出年龄
.collect(Collectors.toList());//将每个年龄存入List集合中并返回List集合
}













 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









