python基于tesseract,fontTools图片识别破解猫眼字体反扒技术
背景
首先声明,该文章只用于技术探究和学习,请勿用于非法用途。如不听劝告,产生法律责任,需自行承担。
在我们对一些数据进行爬取时往往会出现如下情况:
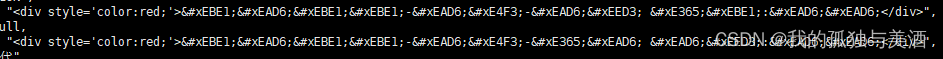
一些时间或者数字信息在源数据或者源码里面是;这种编码,但是展示却是正常的。
这是一种css加密技术,网页能够根据编码编译加载的css字体文件,然后将字体图片显示在内
容当中,从而让用户能正常看到数据。这种技术使得在传输过程中,拿到数据也不知道该编码
对应的数字。就算破解字体文件,知道那个码对应字体文件的哪个部分的字,程序也无法知道
这个字是什么值。
可以注意的是,程序在返回数据时,往往也会返回一个woff或者ttf文件,用于前端正常显示
一般简单一些的woff文件不会变动,也有一天一变的,也有每次接口调用都变的。
还有有的woff文件不管怎么变,内部码表和字的的映射关系不会变,但是有的也会一直变。
所以,靠人为识别并固定字体映射关系在一些场景下不可靠。
问题
数据被加密,这css文件就相当于解密的码表,那么如何知道字体文件中每个编码对应的数字值呢?
解决方案
最好的方式就是 将字体文件woff根据其xml内容拆分了一个个单独的小图片,并以其图片位置对应的
编码命名。然后通过tesseract对图片进行识别,将文件名和识别结果形成一个码表集合,然后对数据
进行解码。
环境准备
安装 python 和 tesseract
安装依赖
Pillow pycv2 pytesseract reportlab requests numpy opencv-python Flask fonttools
开始编码
字体下载工具(downloadUtil.py)
import requests
def download_file(url, path, headers):
response = requests.get(url, headers=headers)
f1 = open(path, 'wb')
f1.write(response.content)
字体拆分工具(fontUtil.py)
from __future__ import print_function, division, absolute_import
from PIL import Image
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
from reportlab.graphics import renderPM
from reportlab.graphics.shapes import Group, Drawing
import cv2
class ReportLabPen(BasePen):
"""A pen for drawing onto a reportlab.graphics.shapes.Path object."""
def __init__(self, glyphSet, path=None):
BasePen.__init__(self, glyphSet)
if path is None:
path = Path()
self.path = path
def _moveTo(self, p):
(x, y) = p
self.path.moveTo(x, y)
def _lineTo(self, p):
(x, y) = p
self.path.lineTo(x, y)
def _curveToOne(self, p1, p2, p3):
(x1, y1) = p1
(x2, y2) = p2
(x3, y3) = p3
self.path.curveTo(x1, y1, x2, y2, x3, y3)
def _closePath(self):
self.path.closePath()
def woff2_image_service(font_name, image_path, fmt="png"):
font = TTFont(font_name)
gs = font.getGlyphSet()
glyph_names = font.getGlyphNames()
for i in glyph_names:
if i[0] == '.':
continue
g = gs[i]
pen = ReportLabPen(gs, Path(fillColor=colors.red, strokeWidth=5))
g.draw(pen)
w, h = g.width, g.width * 2
g = Group(pen.path)
g.translate(0, 200)
d = Drawing(w, h)
d.add(g)
image_file = image_path + "/" + i + ".png"
renderPM.drawToFile(d, image_file, fmt)
img = cv2.imread(image_file, -1)
height, width = img.shape[:2]
size = (int(width * 0.05), int(height * 0.05))
img = cv2.resize(img, size, cv2.INTER_AREA)
cv2.imwrite(image_file, img)
image_buffer = Image.open(image_file)
mark_img = Image.new('RGBA', size, (255, 0, 0, 0))
mark_img.paste(image_buffer, (0, 0))
mark_img.save(image_file)
return "OK"
字体图片识别工具(ocr.py)
import os
import pytesseract
from PIL import Image
import cv2
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
tessdata_dir_config = '--tessdata-dir "D:/python/data/tessdata" --oem 1 --psm 10'
def image_2_str(image_path):
pic = Image.open(image_path)
pic = pic.convert('RGBA')
width, height = pic.size
array = pic.load()
for i in range(width):
for j in range(height):
pos = array[i, j]
isEdit = (sum([1 for x in pos[0:3] if x > 240]) == 3)
if isEdit:
array[i, j] = (255, 255, 255, 0)
tmp1 = image_path.replace("image", "image-tmp-1")
pic.save(tmp1)
cmg = cv2.imread(image_path, 0)
code = pytesseract.image_to_string(cmg, config=tessdata_dir_config, lang='eng')
code = code.replace(" ", "")
code = code.replace("\n", "")
code = code.replace("\t", "")
return code
def setDir(filepath):
'''
如果文件夹不存在就创建,如果文件存在就清空!
:param filepath:需要创建的文件夹路径
:return:
'''
if not os.path.exists(filepath):
os.mkdir(filepath)
def getFileName(path):
file_name = os.path.basename(path)
return file_name.split('.')[0]
业务处理逻辑(main.py)
import os
import time
from util.ocr import image_2_str
from util.fontUtil import woff2_image_service
from flask import *
from util.downloadUtil import download_file
from util.ocr import setDir
app = Flask(__name__)
image_dir = "D:/python/data/image"
tmp_dir = "D:/python/data/tmp_file/"
@app.route('/parse', methods=['POST'])
def success():
try:
param = request.get_data()
param = json.loads(param)
filename = param['filename']
url = param['url']
headers = param['headers']
tp = time.time()
stp = str(tp)
stp = stp[:stp.find(".")]
file_path = tmp_dir + stp + filename
image_dir_tmp = image_dir + stp + "/"
tmp1 = image_dir_tmp.replace("image", "image-tmp-1")
setDir(tmp_dir)
setDir(image_dir_tmp)
setDir(tmp1)
download_file(url, file_path, headers)
woff2_image_service(file_path, image_dir)
result_list = []
for dir_path, dir_names, file_names in os.walk('D:/python/data/image'):
for filename in file_names:
path = os.path.join(dir_path, filename)
value = image_2_str(path)
key = filename[:filename.find(".")]
code_table = {"key": key, "value": value}
result_list.append(code_table)
return json.dumps(result_list, ensure_ascii=False)
except Exception as e:
print(e)
res = {'msg': '识别失败', 'code': 500, 'data': ''}
return json.dumps(res, ensure_ascii=False)
if __name__ == '__main__':
app.run(port=8033, debug=True)
结尾
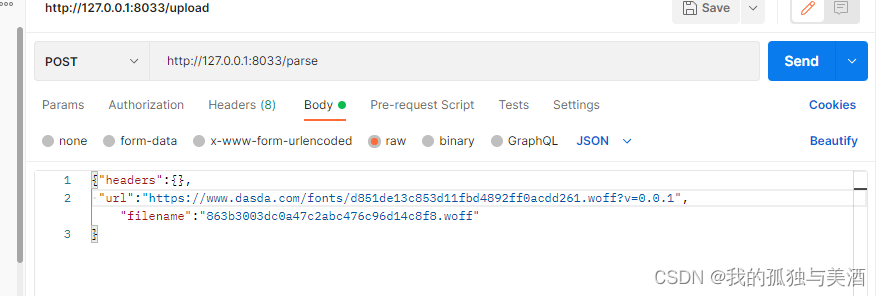
ok,一个字体识别服务完成,开始测试

























 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











