






worker的职责和常用成员变量
Worker是Spark在local-cluster部署模式和Standalone部署模式中对工作节点的资源和Executor进行管理的服务。Worker一方面向Master汇报自身所管理的资源信息,一方面接收Master的命令运行Driver或者为Application运行Executor。同一个机器上可以同时部署多个Worker服务,一个Worker也可以启动多个Executor。当Executor完成后,Worker将回收Executor使用的资源。
- cores:内核数。
- memory:内存大小。
- workDirPath:字符串表示的Worker的工作目录。
- forwordMessageScheduler:用于发送消息的调度执行器。
- registered:标记Worker是否已经注册到Master。
- connected:标记Worker是否已经连接到Master。
- workerId:Worker的身份标识。
- drivers:Driver的身份标识与DriverRunner之间的映射关系。
- executors:Executor的身份标识与ExecutorRunner之间的映射关系。
- appDirectories:Application的ID与对应的目录集合之间的映射关系。
- coresUsed:当前Worker已经使用的内核数。
- memoryUsed:当前Worker已经使用的内存大小。
worker启动
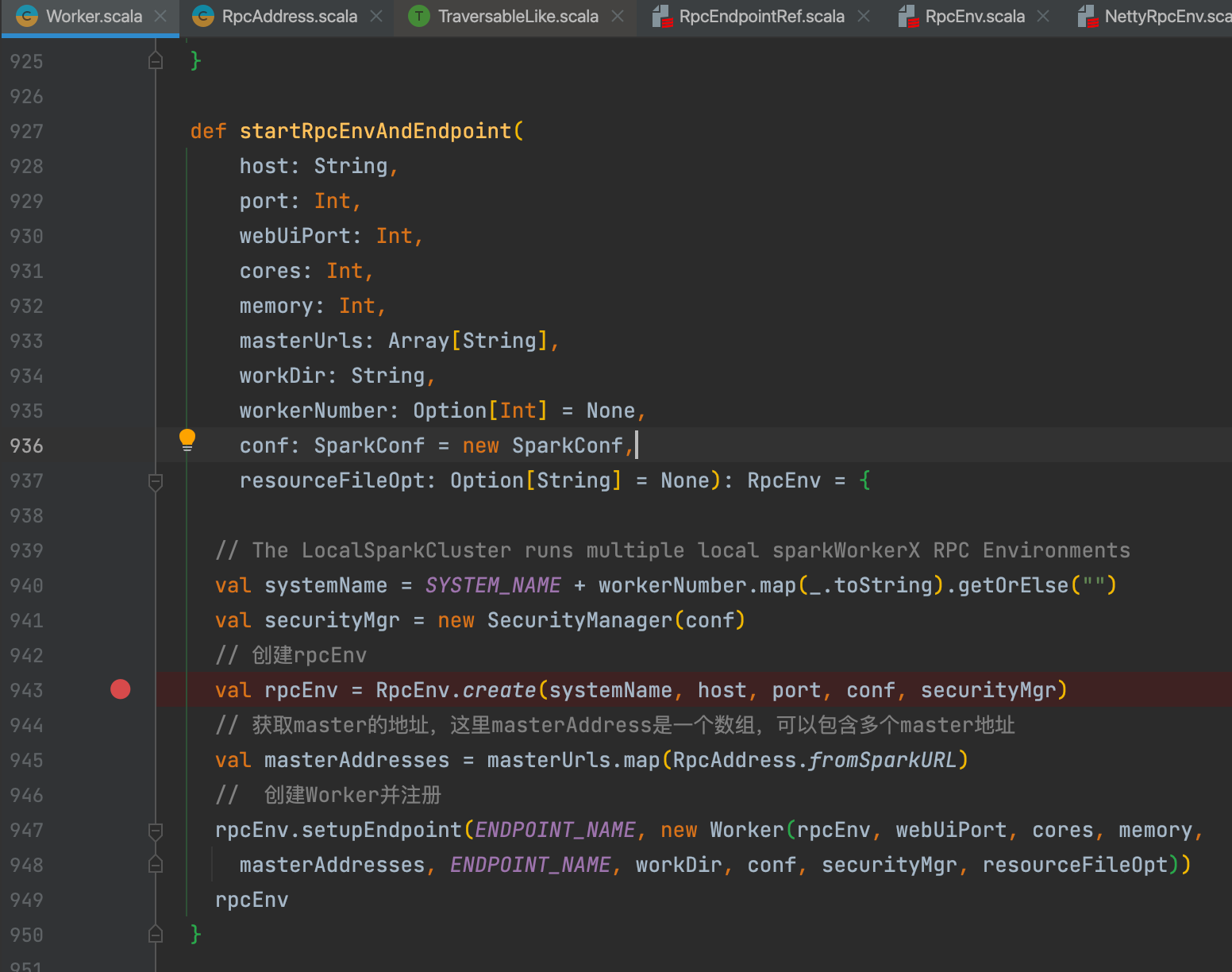
跟master一样,启动方式分为进程启动和对象启动两种,最后都是调用startRpcEnvAndEndpoint�方法。
- 生成rpcEnv
- 将所有Master的Spark URL(格式为spark://host:port)转换为RpcAddress地址。Rpc-Address只包含host和port两个属性。
- 创建worker并向rpcEnv注册,会触发Worker的onStart方法。
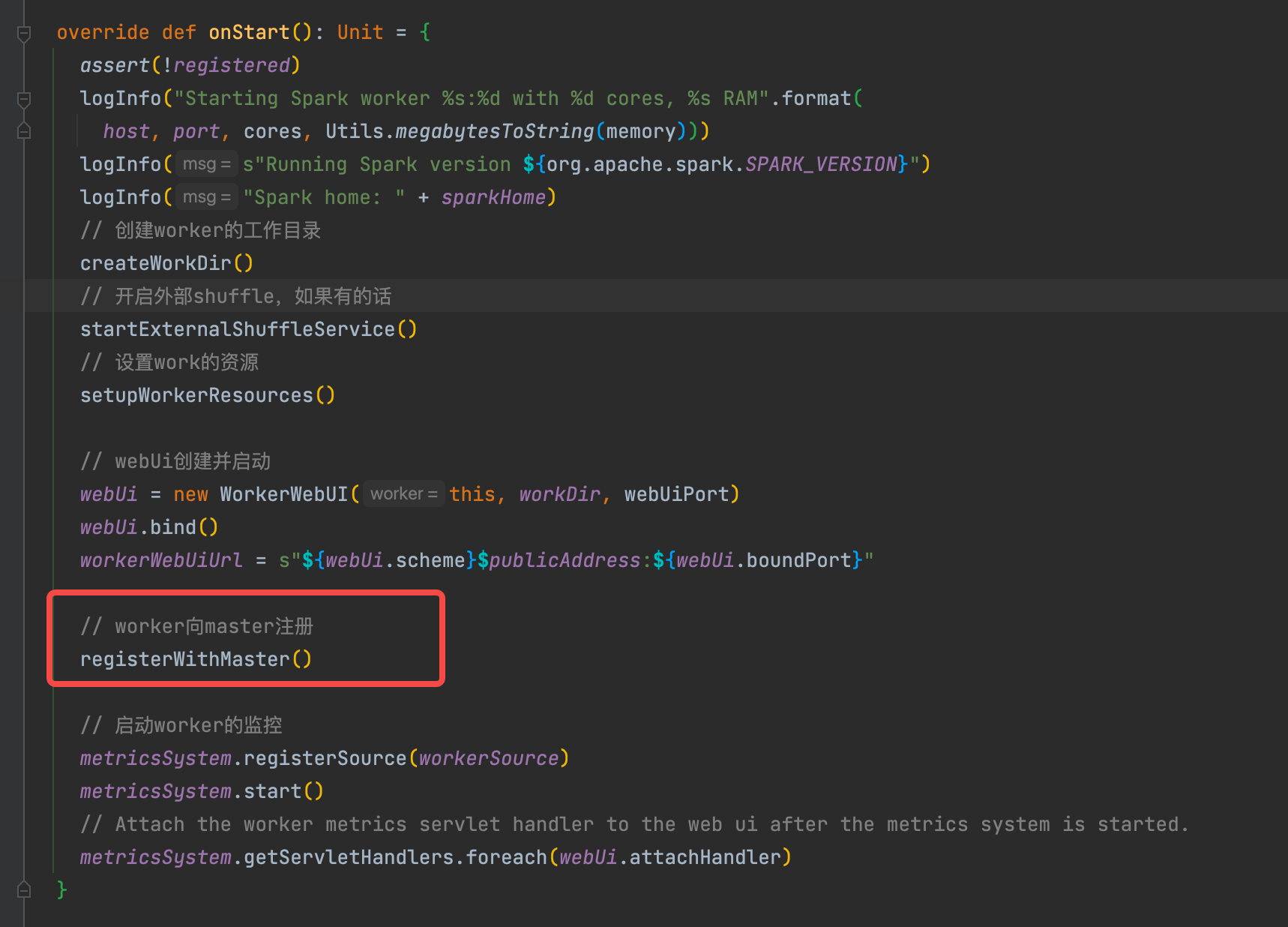
onStart主要做一些初始化的操作。
- 创建工作目录
- 如果配置了外部的shuffle服务,启动shuffleServive
- 创建webUi并绑定端口
- 向master注册(worker注册的入口)
- 启动worker的监控
worker注册
worker在启动后,需要将自己的资源情况汇报给master,便于master统一进行资源的分配调度。
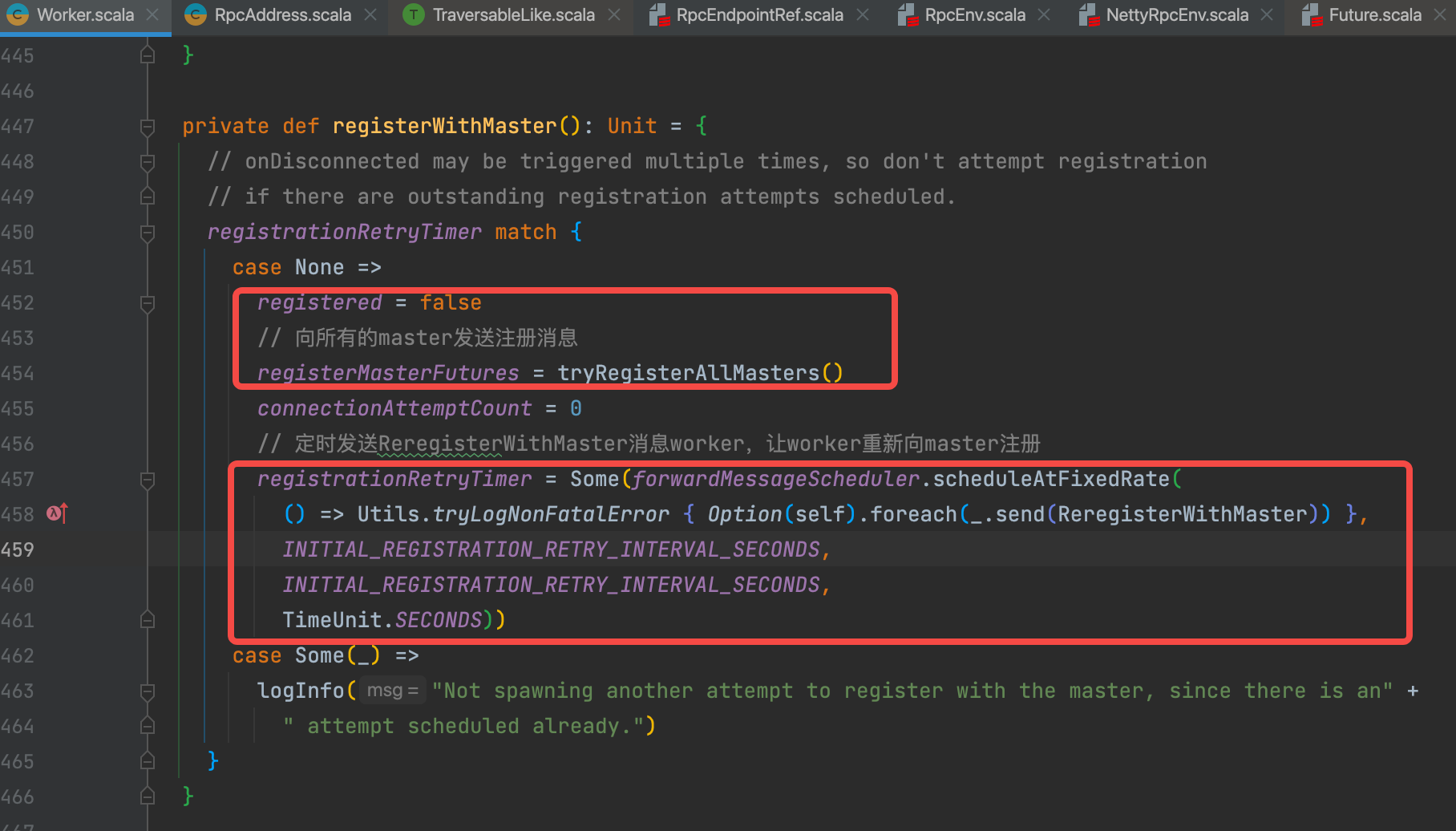
- 初始的时候registrationRetryTimer为None,将registered置为false。registered初始就是false,为什么这里还要再一次置为false呢?因为当worker跟master失联后再次注册的时候,registrationRetryTimer为None,registered为true,所以这里registered不管状态,在向master注册的时候都是false(没有注册的状态)。
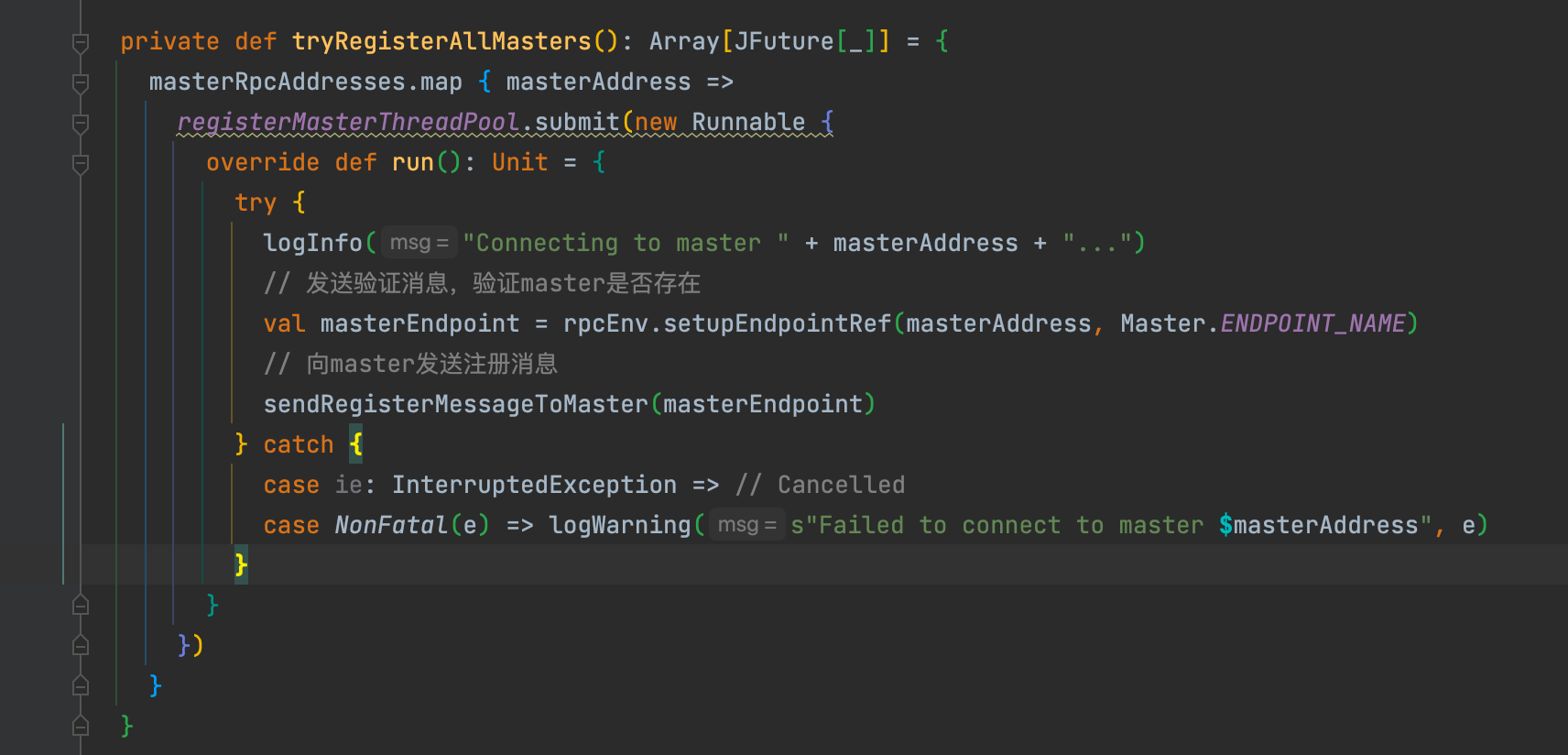
- 调用�tryRegisterAllMasters�向所有的master注册。
- 注册一个定时器,定时发送ReregisterWithMaster�消息给worker,让worker定时去注册。tryRegisterAllMasters�是有可能因为某些原因都没有注册成功,所以采用定时注册的方式,保证注册成功。
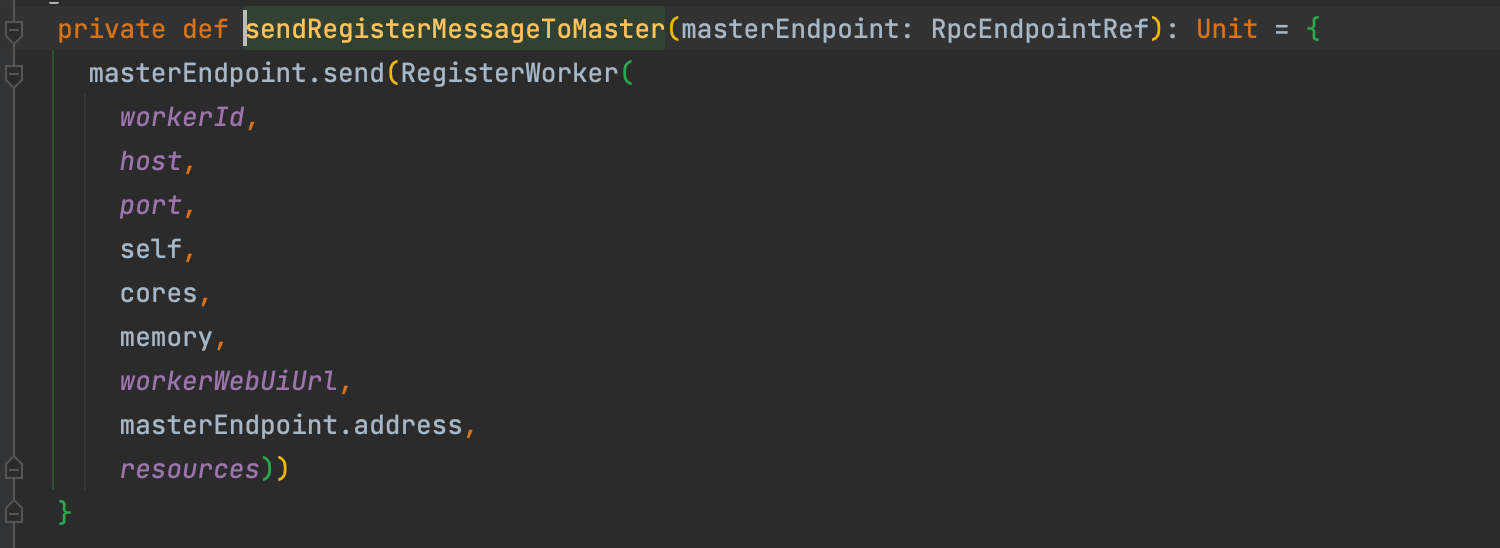
tryRegisterAllMasters�是遍历所有的master,依次先获取masterEndpoint的引用,再调用sendRegisterMessageToMaster�方法向master发送RegisterWorker�注册消息。
RegisterWorker�包含以下信息:
- workerId:worker的唯一标识
- host:worker的host
- port:worker的port (host加上port表示worker的地址)
- self:worker自身的endpoint引用,可以让master通知它和worker通信
- cores:内核数
- memory:内存大小
- workerWebUiUrl:worker的webUi地址
- masterEndpoint.address�:master的地址
- resources:worker特有的一些资源
master在收到worker的注册消息后会进行对应的处理。这一部分在master中已经讲过。
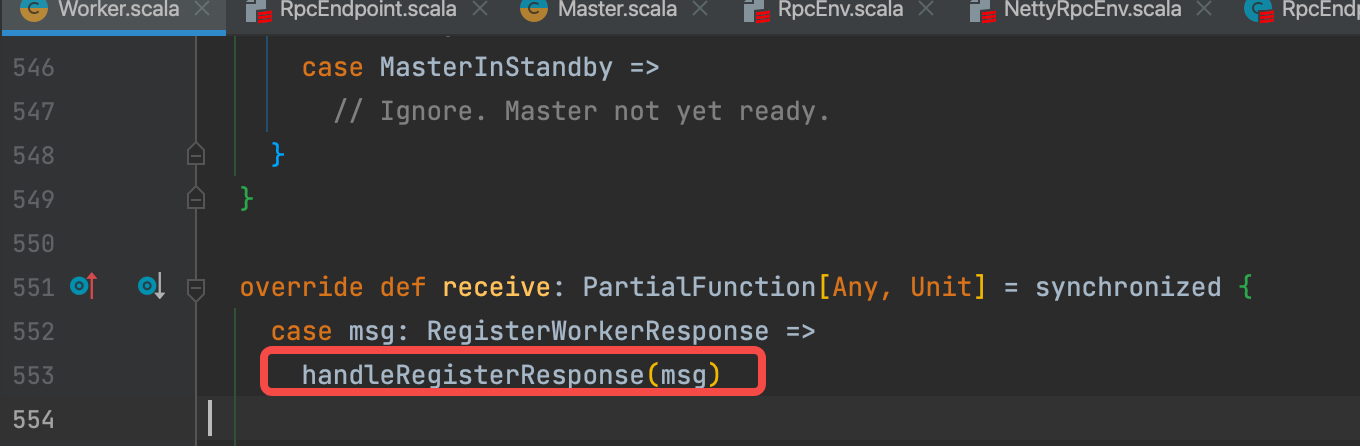
worker收到master返回的注册结果消息RegisterWorkerResponse�,会调用handleRegisterResponse�来处理。
handleRegisterResponse�会根据返回结果的不同进行不同的处理。
MasterInStandby�:注册的master节点是standBy状态,不做任何处理。
RegisterWorkerFailed�:注册失败,退出worker进程。
RegisteredWorker�:成功注册。
- 将registered置为true,表示注册成功。
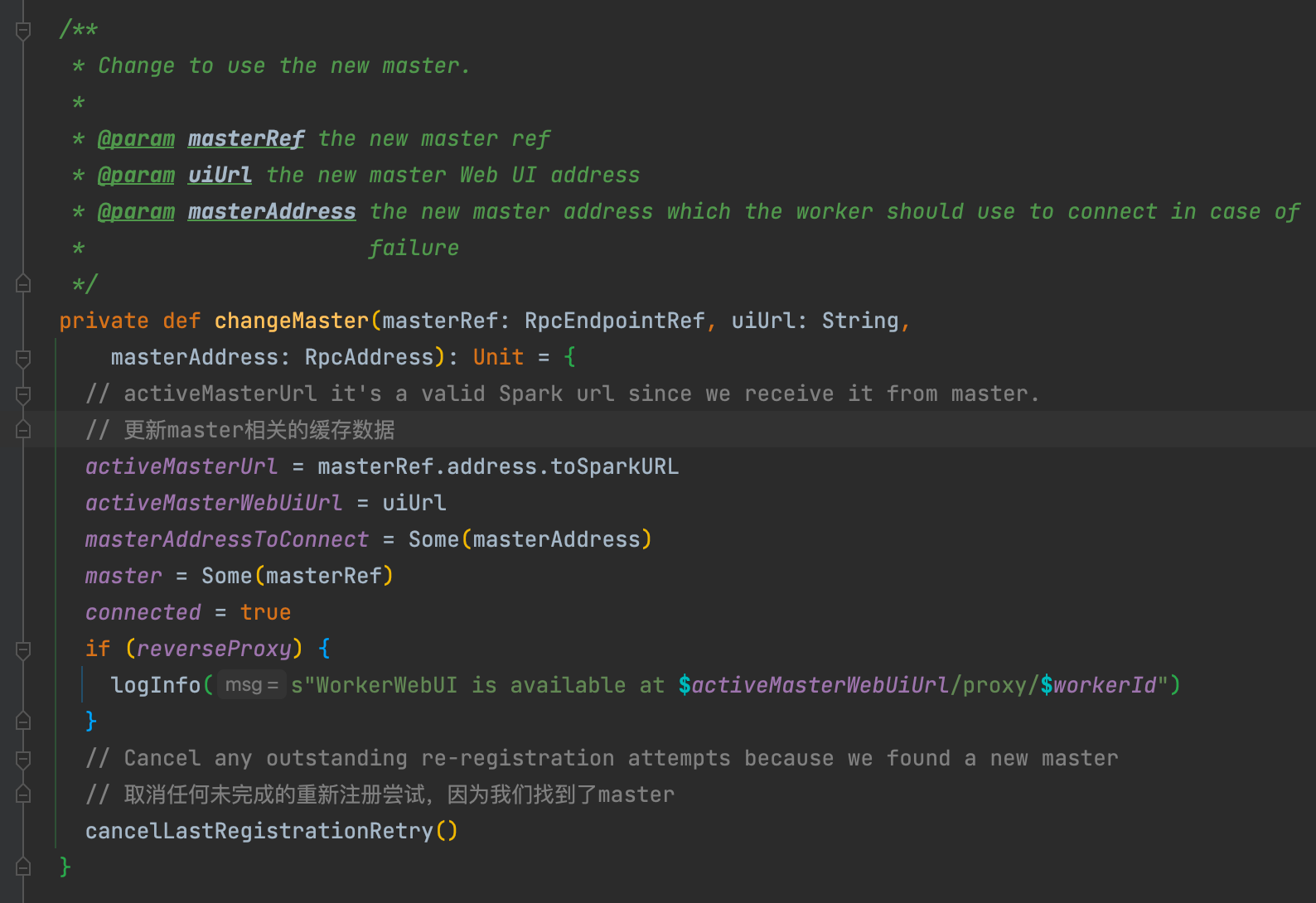
- 调用changeMaster�方法更新worker中关于master的缓存信息
- 启动定时任务,向master发送心跳�
- 如果开启了目录清理的话,启动定时任务自动清理文件
- 向master汇报worker节点的工作状态,主要是executor和driver的信息
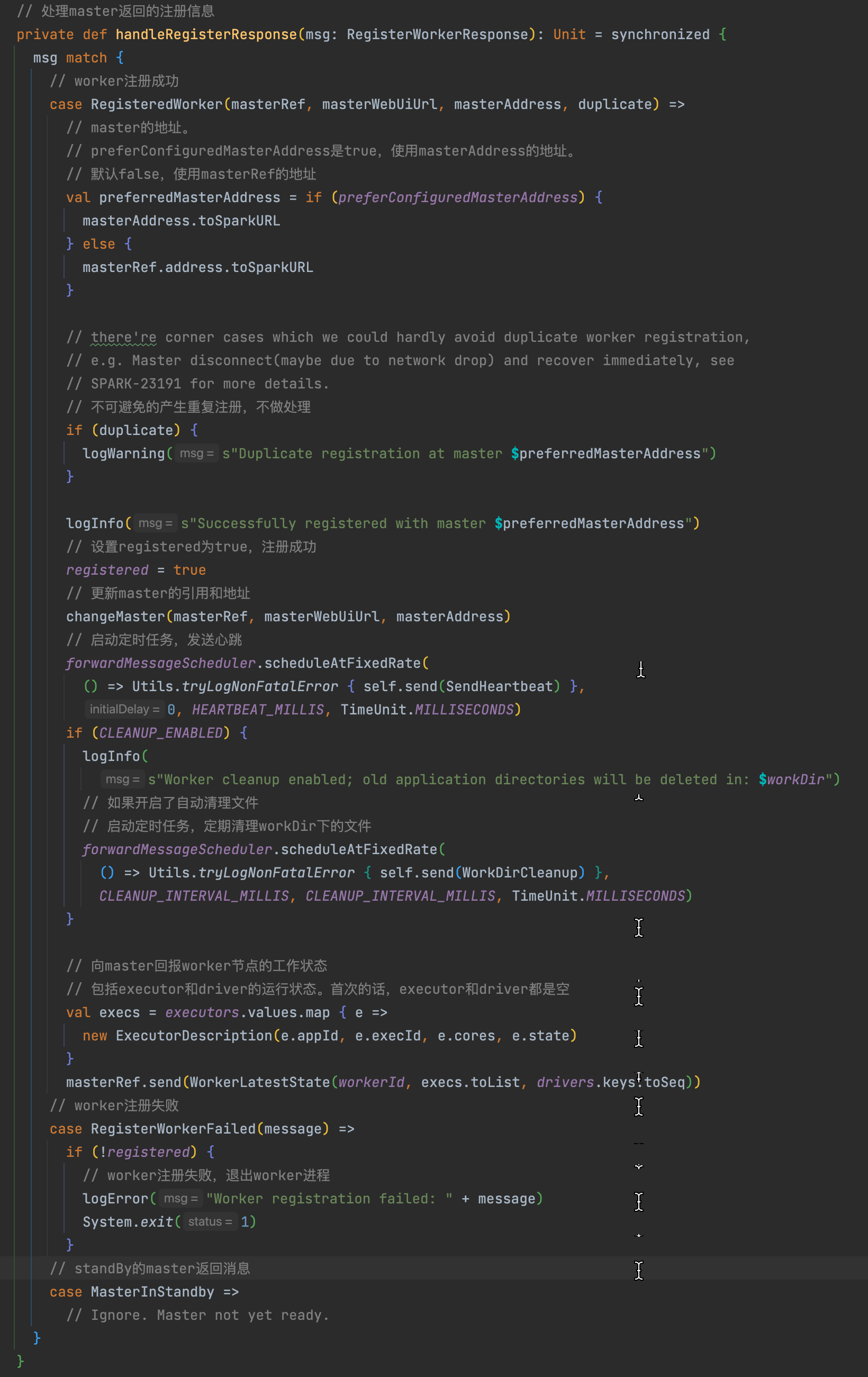
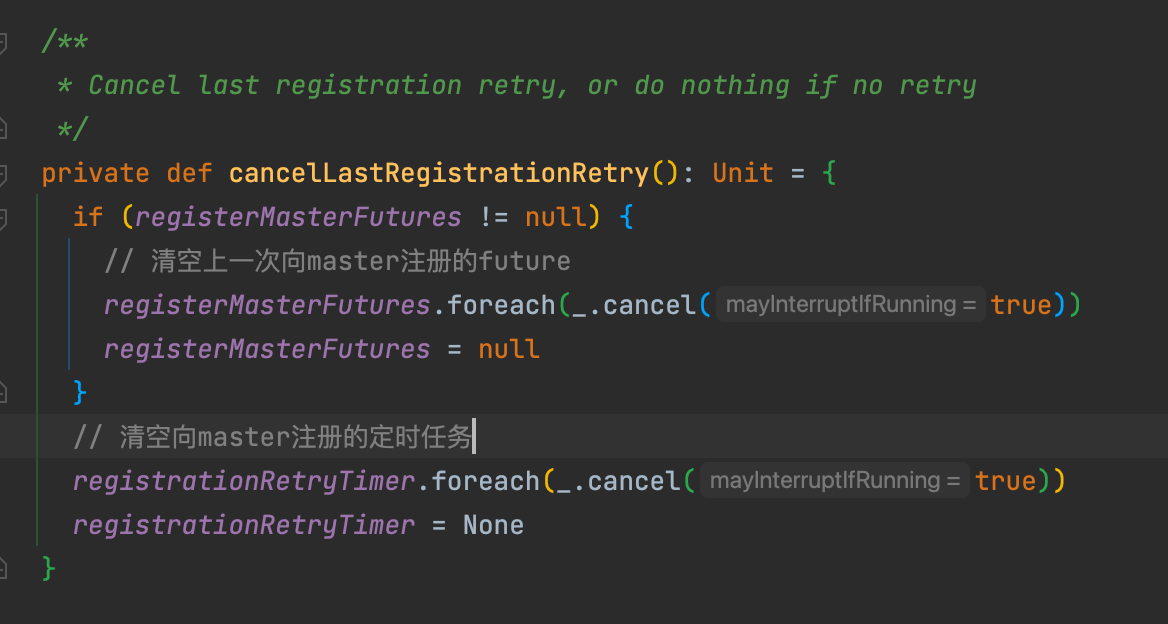
changeMaster�主要是更新master相关的信息,同时调用cancelLastRegistrationRetry�方法。
cancelLastRegistrationRetry�方法是清空上一次注册的future和定时注册任务。
至此worker向master注册成功。
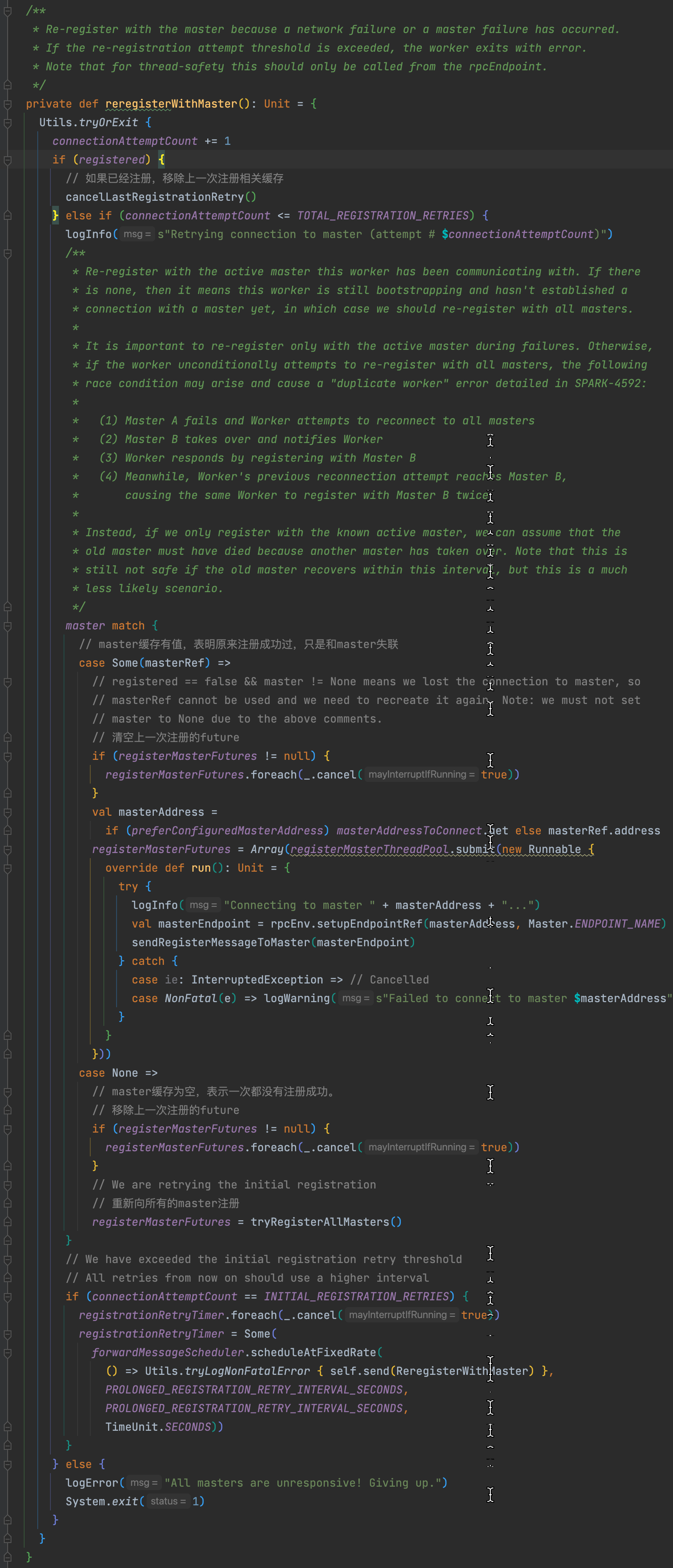
还有因为网络等各种原因,worker没有注册成功。定时器会定时发送ReregisterWithMaster�重新注册的消息给worker。worker收到ReregisterWithMaster�消息后调用reregisterWithMaster�方法。

reregisterWithMaster�这个方法是向指定的master重新注册。
master变量为空,表明是首次注册,向所有的master注册
master变量不为空,表明曾经注册成功过,因为某些原因失联了,再次向这个master注册。为什么不直接复用tryRegisterAllMasters�向所有master注册呢?注释给了一个例子SPARK-4592�:如果master A退出了,worker尝试向所有的master注册。master B变更为active,并通知worker重新向它注册。这样就会出现worker同时先master B注册两次的情况。因此这里限制只向上一个连接的master注册。注释还提到master A在失败后退出并短时间内重新启动也会导致重复注册的情况,但这种场景很少。
发送心跳
worker在向master注册后,处理注册成功的消息会启动定时任务向自身发送SendHeartbeat消息�。

worker收到SendHeartbeat�消息后会创建一个Heartbeat�消息(包含workerId和worker的引用)调用sendToMaster方法,将Heartbeat�消息发送给master。master收到心跳消息后怎么处理再master中已经讲过了。
下图是worker心跳与master交互的流程
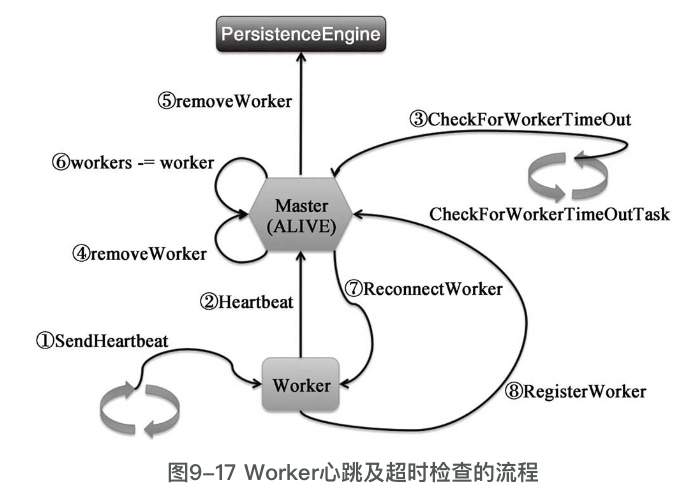
- Worker在向Master注册成功后,将向forwordMessageScheduler提交以HEART-BEAT_MILLIS作为间隔向Worker自身发送SendHeartbeat消息的定时任务。
- Worker接收到SendHeartbeat消息后,将向Master发送Heartbeat消息。在正常情况下,Worker向Master发送的心跳足够及时,因此Master并未检查出Worker超时,此时idToWorker中将缓存着WorkerInfo, Master只需要将此WorkerInfo的最后心跳时间(lastHeartbeat)更新为系统当前时间戳。
- Master内部的定时任务checkForWorkerTimeOutTask将以WORKER_TIME-OUT_MS为时间间隔定时向Master自身发送CheckForWorkerTimeOut消息。Master接收到CheckForWorkerTimeOut消息后,调用timeOutDeadWorkers方法检查超时的Worker。
- Master在检查过程中发现Worker超时,但是对应的WorkerInfo的状态不是DEAD,因此调用removeWorker方法移除Master维护的关于指定Worker的相关信息和状态。这里特别要关注的是,此时Master会将WorkerInfo从idToWorker中移除,但是workers中仍然保留WorkerInfo。
- removeWorker方法的最后还将调用持久化引擎的removeWorker方法从持久化存储中移除WorkerInfo
- Master在检查过程中发现Worker超时且对应的WorkerInfo的状态是DEAD,等待足够长的时间后将WorkerInfo从workers中移除。
- Master在检查Worker时,如果发生了序号④所示的情况,那么idToWorker中将没有对应的WorkerInfo,但是workers中仍然保留WorkerInfo,此时Master将向Worker发送ReconnectWorker消息。
- Worker接收到ReconnectWorker消息后,将重新调用registerWithMaster方法向Master注册,进而向Master发送RegisterWorker消息。
worker与领导选举
master被选举成leader后,会向worker发送MasterChange的消息。
worker收到MasterChange的消息后会执行一下操作:
- 更新master的信息为新的master
- 整理executor和driver的信息
- 将worker的状态发送给新的master
master领导选举流程如下图:
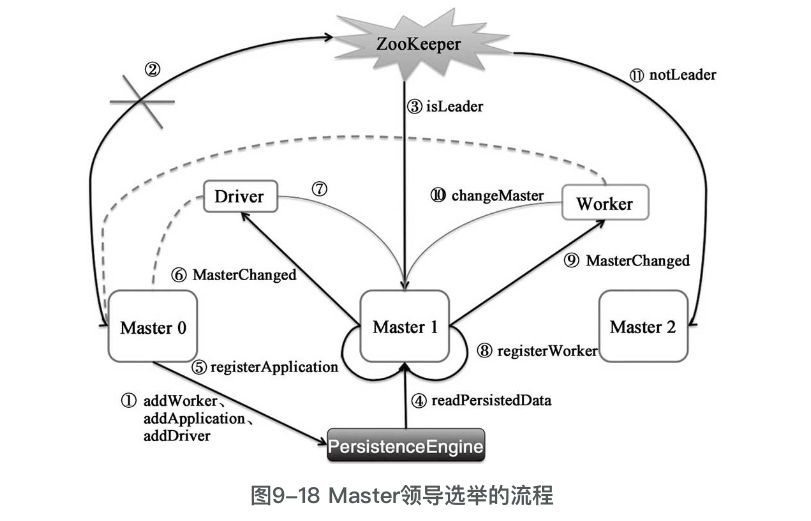
- Worker在启动后会向Master注册,Driver在启动后也会向Master注册。在注册成功后,Master会调用PersistenceEngine的addWorker、addApplication及addDriver三个方法,将Worker、Driver、Application的相关信息持久化。
- Master在运行的时候出现网络故障、宕机或者服务下线时,ZooKeeper会感知到。
- Master 1和Master 2参加领导选举,最后Master 1胜出,于是LeaderLatch将调用Master 1的ZooKeeperLeaderElectionAgent的isLeader方法,isLeader方法实际调用了Master 1的electedLeader方法。
- electedLeader方法调用PersistenceEngine的readPersistedData方法从持久化数据中读取WorkerInfo、DriverInfo、ApplicationInfo,然后调用Master 1的beginRecovery方法开始恢复。
- beginRecovery方法对于从持久化引擎中读取的ApplicationInfo,调用register-Application方法注册到apps、idToApp、endpointToApp、addressToApp、waitingApps等缓存中,然后将ApplicationInfo的状态设置为UNKNOWN。
- beginRecovery方法还将向提交Application的Driver发送MasterChanged消息。
- Driver接收到MasterChanged消息后,将自身的master属性修改为当前Master的RpcEndpointRef,并将alreadyDisconnected设置为false,最后向Master发送MasterChange-Acknowledged消息。Master接收到MasterChangeAcknowledged消息后,将ApplicationInfo的状态修改为WAITING,然后在不存在状态为UNKNOWN的ApplicationInfo和Worker-Info时调用completeRecovery方法完成恢复。
- beginRecovery方法对于从持久化引擎中读取的WorkerInfo,调用register-Worker方法将WorkerInfo添加到workers、idToWorker、addressToWorker等缓存中,然后将WorkerInfo的状态设置为UNKNOWN。
- beginRecovery方法还将向Worker发送MasterChanged消息。
- Worker接收到MasterChanged消息后,将自身的activeMasterUrl、activeMaster-WebUiUrl、master等属性修改为当前Master的对应信息,然后将connected设置为true,最后向Master发送WorkerSchedulerStateResponse消息。Master接收到WorkerScheduler-StateResponse消息后,首先将WorkerInfo的状态修改为ALIVE,然后对此Worker上的Executor和Driver也进行恢复,最后在不存在状态为UNKNOWN的ApplicationInfo和WorkerInfo时调用completeRecovery方法完成恢复。
- Master 1和Master 2参加领导选举,最后Master 1胜出,于是LeaderLatch将调用Master 2的ZooKeeperLeaderElectionAgent的notLeader方法,notLeader方法实际调用了Master 2的revokedLeadership方法。
启动executor
worker收到master发来的LaunchExecutor�消息后,判断master是active后会执行一下操作:
- 在worker目录下创建executor的目录
- 创建一个executor单独的一个工作目录,并将目录地址保存在appDirectories中
- 构建一个ExecutorRunner�,并将其保存在executor中
- ExecutorRunner启动executor
- 扣减executor使用的资源
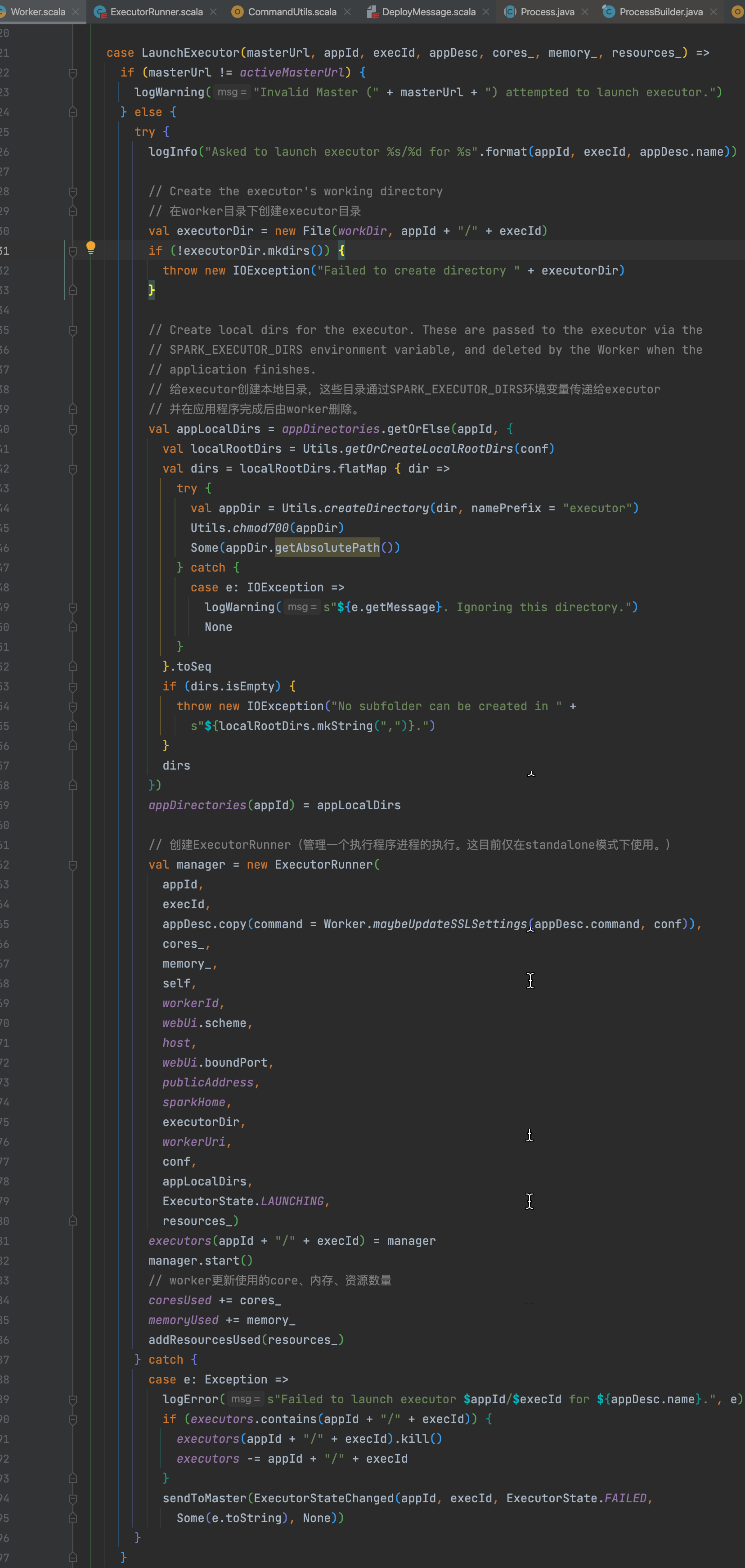
ExecutorRunner的start方法中为了避免不阻塞主线程,使用另一个线程来启动executor并监控它的状态。
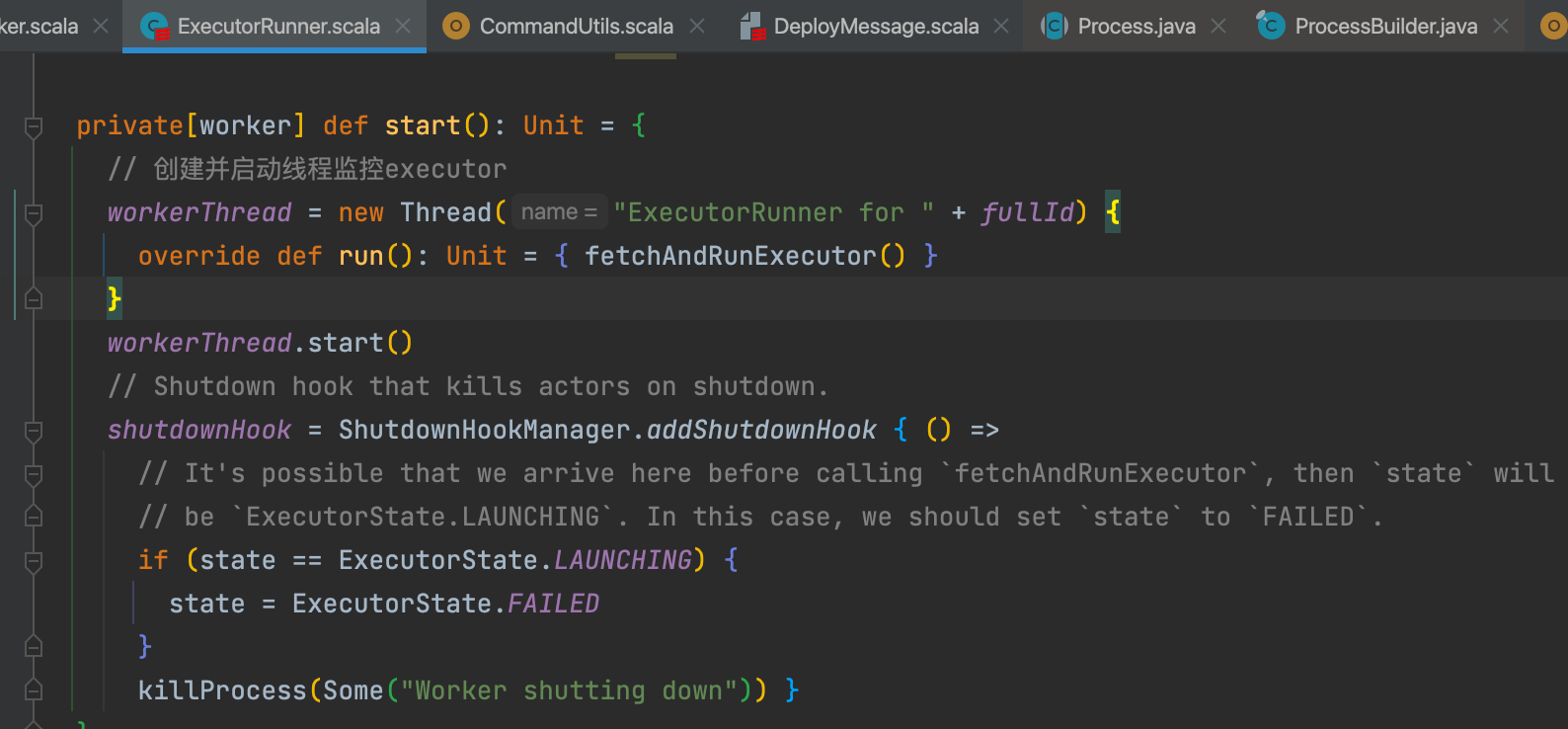
fetchAndRunExecutor�中根据参数构建出processBuilder,使用processBuilder构建出process,并且监控这个process的状态,并发送ExecutorStateChanged�消息通知worker。
ProcessBuilder、Process是JDK的类,是用来创建系统进程的相关类。
executor状态变化
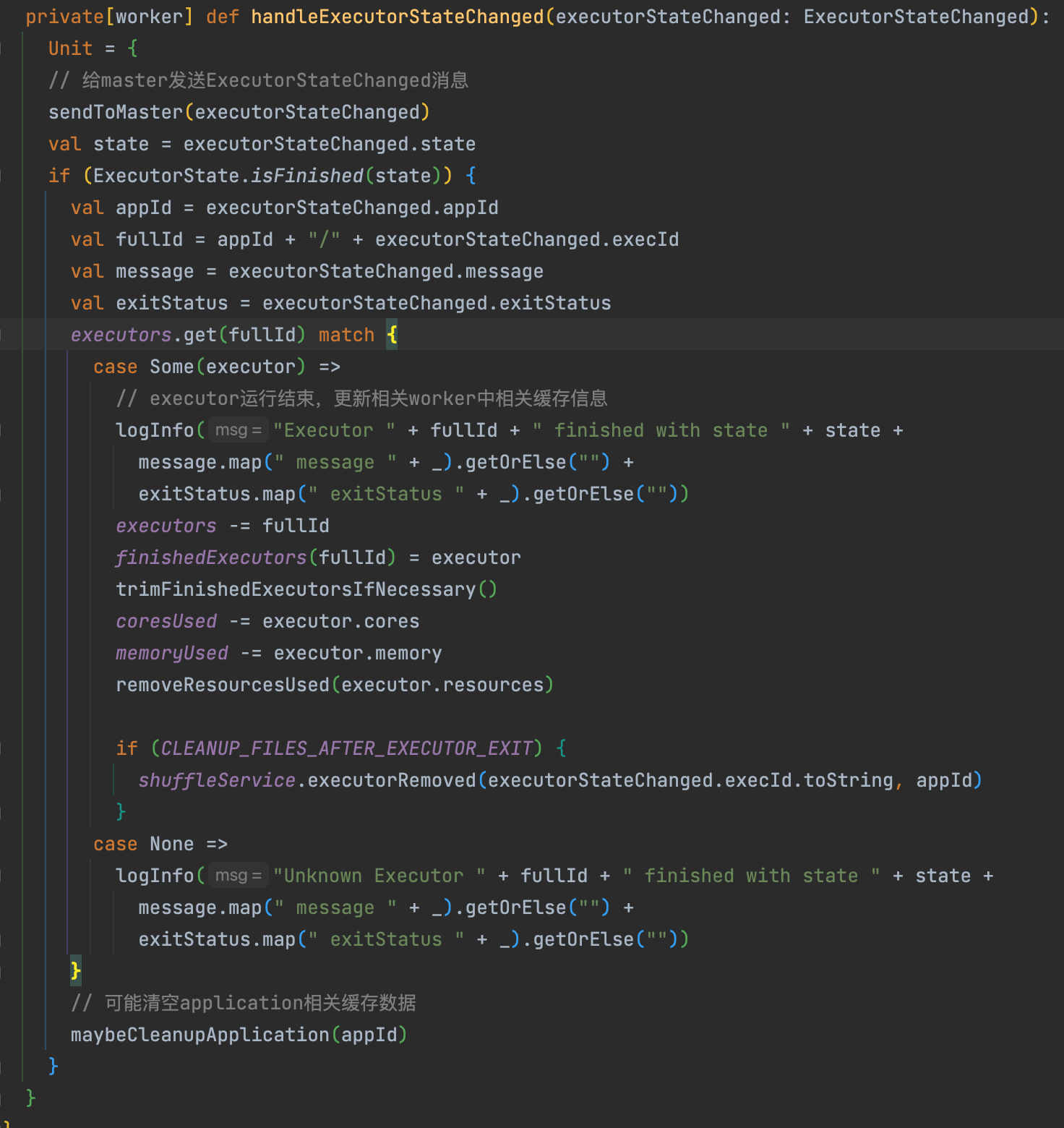
worker收到executorStateChanged消息后会调用handleExecutorStateChanged方法

handleExecutorStateChanged中首先会发送executorStateChanged消息给master,然后判断executor状态是不是完成,如果是完成状态就更新相关的缓存,
最后检查一下application是不是也是完成状态,如果是的话,也清理application相关的缓存。

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









