










这篇是混合《Linux性能优化实战》以及 《Wireshark网络分析就这么简单》的一些关于Linux 网络的学习概念和知识点笔记 ,主要记录网络传输流程以及对于TCP和UDP传输的一些影响因素
Linux 网络传输流程
借用一张倪朋飞先生的《Linux性能优化实战》课程中的图片
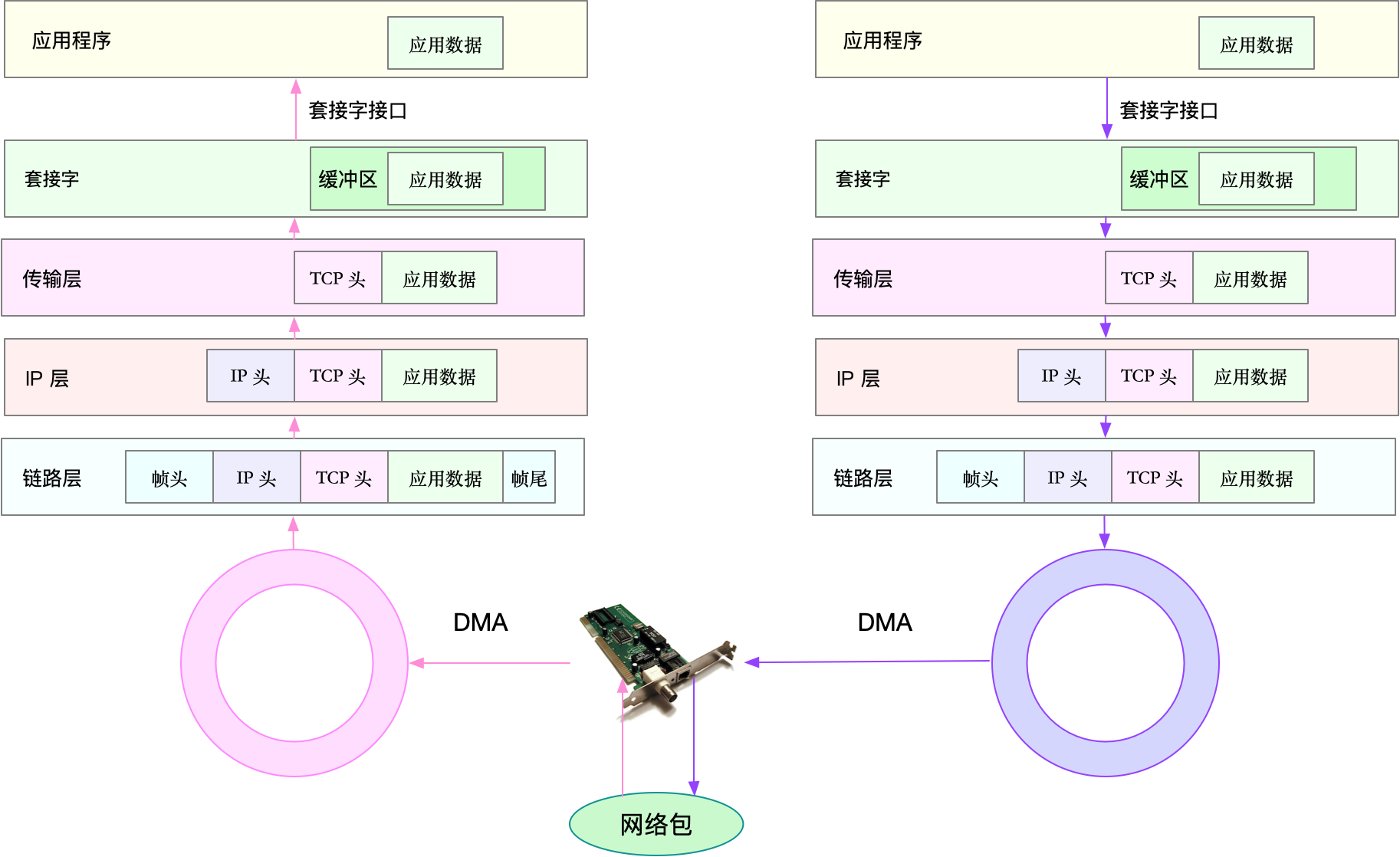
接收流程
- 网卡收到网络数据包,加入到收包队列
- 网卡将网络包写入DMA缓冲区,通知中断处理程序
- CPU硬中断锁定DMA缓冲区,将网络包拷贝到内核数据结构 sk_buff 缓冲区,清空并解锁当前DMA缓冲区
- 通知软中断,通知内核收到了新的网络帧,内核协议栈从缓冲区中取出网络帧
- 在链路层检查报文合法性,找出上层协议类型(ipv4/ipv6),去掉帧头,帧尾,交给网络层
- 网络层取出IP头,判断网络走向
- 本机的:取出上层协议(TCP/UDP),去掉IP头,交给传输层
- 非本机:转发
- 传输层取出TCP或者UDP头,根据 < 源 IP、源端口、目的 IP、目的端口 > 四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中
- 应用程序就可以使用 Socket 接口,读取到新接收到的数据
发送流程
- 应用程序通过调用 Socket API(比如 sendmsg,系统调用)发送网络包,这是一个系统调用,所以会陷入到内核态的套接字层中,套接字层会把数据包放到 Socket 发送缓冲区中
- 网络协议栈从 Socket 发送缓冲区中,取出数据包
- 传输层依据协议增加TCP或UDP头
- 网络层增加IP头,通过路由寻找下一条IP,并按照MTU大小分片
- 分片后的网络包再送到网络接口层,进行物理寻址,找下一条MAC地址,增加帧头和帧尾
- 软中断通知驱动程序,发包队列有新的网络帧需要发送
- 驱动通过DMA,从发送队列读取网络帧,并通过物理网卡发送出去
TCP的一些网络影响因素
一些小概念
接收窗口(Receiver Window)
接收窗口表示接收方TCP缓冲区可容纳的数据量。
发送方不能发送超过接收窗口大小的数据,以确保接收方有足够的时间处理数据。接收窗口大小由接收方TCP发送给发送方的窗口大小更新。
发送窗口(Sender Window)
发送窗口表示发送方TCP缓冲区可容纳的数据量。
接收方不能发送超过发送窗口大小的数据,以确保发送方有足够的时间发送数据。发送窗口大小由发送方TCP发送给接收方的窗口大小更新。
一般由接收方的接收窗口和发送方的发送窗口的较小值决定,另外网络的影响也会导致发送窗口变化
MSS 最大分段大小(Maximum Segment Size)
MSS表示TCP报文段的最大长度。
每个TCP连接都有一个MSS值,它取决于网络的最大传输单元(MTU)。发送方将数据分割为适当大小的报文段,以确保数据可以在TCP连接上可靠传输。
MTU 最大传输单元(Maximum Transmission Unit)
MTU表示网络中每个数据包的最大大小。
MTU值取决于所使用的网络和协议。在TCP/IP协议栈中,MTU通常等于接收窗口大小,以确保TCP数据可以在单个数据包中传输。
延迟确认
描述
在发送包时,接收方延迟确认,可以实现多个包一块确认,减少确认包的数量,减轻网络负担
缺点
- 在丢包较多的情况下,会导致大量的超时重传,极大的影响网络性能,建议开启SACK提供重传效率
- 接收窗口很小时,由于运输车很小,还要延迟确认,就会导致大量堆积,应该立即配送
过滤
wireshark 的过滤条件
tcp.analysis.ack_rtt >0.2 && tcp.len==0 获取超过200毫秒的确认包
Nagle算法
描述
在发送的数据还未被确认前,新的小包将会被收集,凑满一个MSS或者收到确认后发送
与延迟确认的区别
- Nagle算法没有明显的时间规律
- 凑满一个MSS或者收到确认后发送
- 如果是收到确认包立即发送,就可以判断是Nagle了
关于拥塞
- 刚开始建立连接时,拥塞窗口都设定的比较小
- 在慢启动阶段,拥塞会指数型增长,直到碰到临界窗口值
- 在临界窗口值往上,就会降低增长速度,避免触碰网络拥塞
- 碰到拥塞后,会有超时丢包现象,该阶段没有数据传输,称为超时重传时间(RTO)
- 超时重传后,会重新进入慢启动阶段,并调整临界值(所以超时重传极大影响网络性能)
- Richard Stevens:临界值设为上次发生拥塞的发送窗口的一半
- RFC5681 :发生拥塞时没被确认的数据量的一半,并不能小于2个MSS
超时重传
拥塞发生后,发送方发现发出去的包不像往常一样得到确认了,不过考虑收不到确认包可能是网络延迟导致,所以等待一段时间再判断,迟迟未收到就认定丢包了,只能重传,称为超时重传。
发出原始包到重传这个包的这段时间称为超时重传时间(RTO)。
快速重传
当发送方接受到3个或以上重复确认(Dup ACK)时,就意识到相应的包丢了,从而立即重传这些包
一些优化建议
- 没有拥塞时,发送窗口越大,性能越好。所以在没有带宽限制的时候,应该尽量增大接收窗口
- 如果经常发生拥塞,限制发送窗口能提高网络性能,因为重传对性能的影响极大
- 超时重传对性能影响最大,因为有一段RTO重传时间没有任何数据传输,并且会将拥塞窗口设定为1MSS,所以要尽量避免超时重传
- 快速重传对性能影响相对较小,因为没有等待时间,并且拥塞窗口减小幅度不大
- SACK和NewReno有利于提高重传效率,提高传输效率
- 早期TCP (丢包后面的包都重传,效率极低)
- NewReno (接收方推理出丢掉的包,一个一个请求重传)
- SACK (将目前接收到的包反馈给发送方,ACK提示丢掉的包)
- 例如:SACK=9748-9912 ACK=8820 表示8820到9748之间的包未收到
- 丢包对极小文件的影响比大文件严重,因为读写一个小文件的包数量很少,所以丢包可能也触发不到3个Dup ACK,只能等待超时重传,而大文件更容易触发快速重传
MTU 影响判定
1、如果是防火墙阻止会丢包,但是在三次握手时就会丢弃,而不是握手后访问丢弃
2、网络拥塞会丢包,但一段时间后会恢复
3、只丢大包不丢小包,可能是MTU导致的,特别是1460字节的临界值时
4、ping serverip -l 1472 -f 可以测试MTU是否是1500字节
1472+8(ICMP头)+20(IP头) = 1500
-f 表示DF(Don't fragment 不要分片),大于MTU并且不分片就会被丢弃
如果报错说被丢弃,可能链路上存在较小的MTU,考虑调整MTU
关于UDP
1、UDP不管双方的MTU大小,发送方负责分片,接收方负责将分片组装,会消耗资源和影响性能
2、UDP没有重传机制,丢包由应用层处理,丢了就要全部重传,而TCP仅需重传丢的包
3、分片机制不安全,容易被攻击,如果分片的每个包都有More fragment的flag,1表示还有分片,0表示没有;所以,如果被大量发送flag为1的UDP包,就可能导致资源耗尽
LSO(Large Segment Offload 大量传输减负)
描述
为缓解CPU压力,把部分工作offload交给网卡处理
工作方式
TCP层将大于MSS的数据直接传给网卡,网卡负责分段处理
传统方式
TCP层根据MSS分段(CPU负责),再交给网卡处理
位置
Windows 的配置方式
网卡》属性》配置》高级》大量传输减负














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









