







正则表达式(regular expression)是对字符串操作的一种逻辑公式。学习正则表达式,实际上是学习一种十分灵活的逻辑思维,通过简单、快速的方法达到对字符串的控制。可以说正则表达式是程序员手中一种威力无比巨大的武器!
正则表达式大有用处,这里简要介绍几种常见的用途。
- 测试字符串内的模式。可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
- 替换文本。可以使用正则表达式来识别文档中特定文本,完全删除该文本或者用其他文本替换。
- 基于模式匹配从字符串中提取子字符串。可以查找文档内或者输入域内特定的文本等并删除或替换。例如,你可能需要搜索整个网站,删除过时的资料,以及替换某些HTML格式标记。在这些情况下,可以使用正则表达式来确定每个文件中是否出现相应材料或HTML标记。此过程将受影响的文件范围缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换HTML格式标记。
总结下来,正则表达式最核心的功能就是搜索和替换。
第一关:基本的字符串搜索方法
在Vim文本编辑器的一般命令模式(Normal Mode)下按/输入文本main(与按:进入底线命令模式类似的方式),即在当前文档中向光标之下寻找文本模式为main的字符串。例如,要在文件内搜索RegEx这个字符串,输入/RegEx按Enter键即可。在底部的状态栏可以看到输入的搜索命令/RegEx,按Enter键之后光标就停在了搜索到的下一个RegEx字符串上。相应地,?word是向光标之上寻找一个文本模式为word的字符串。
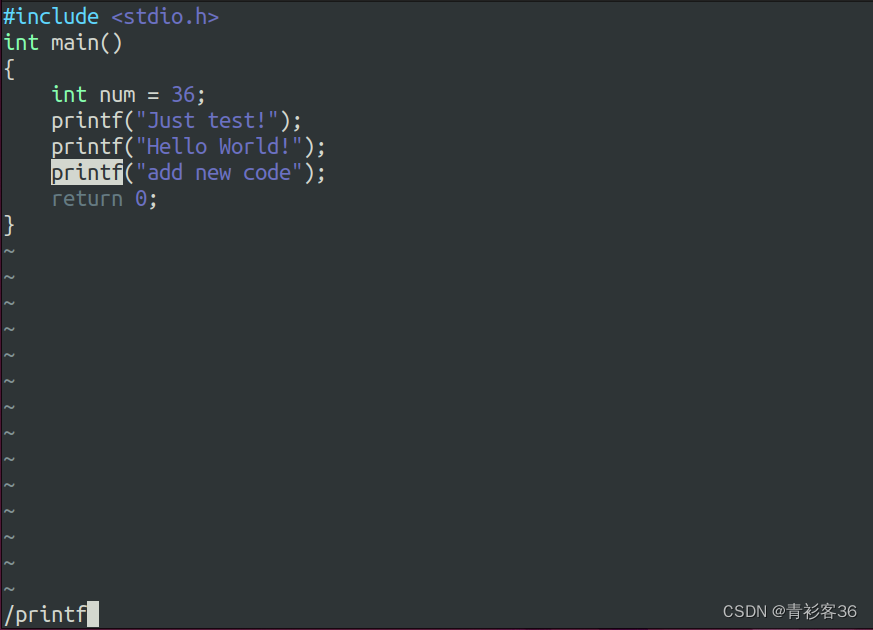
按Enter键搜索到一个目标字符串之后按N键,代表重复前一个搜索的动作继续搜索目标字符串。举例来说,如果我们刚刚执行/RegEx向下搜寻到RegEx这个字符串,按N键后,会继续向下搜索RegEx字符串。如果是执行?RegEx,那么按N键会向上继续搜寻RegEx字符串。
按Enter键搜索到一个目标字符串之后,我们可以用Shift+N快捷键,反方向进行前一个搜索动作(与按N键实现的功能相反)。例如/RegEx后,按Shift + N快捷键则表示向上搜寻RegEx。
第二关:同时搜索多个字符串的方法
在Vim文本编辑器中,只要在多个字符串之间增加或运算符“|”,比如“/main|int”,即可同时搜索多个字符串。你也可以同时搜索超过两个字符串,通过添加更多的或运算符来分隔它们,比如/yes|no|maybe。
第三关:在匹配字符串时的大小写问题
到目前为止,你已经知道使用正则表达式进行字符串匹配的方法了。但有时,你也可能想要匹配具有大小写差异的字符串。比如大写字母“A”,“B”,小写字母“a”,“b”。
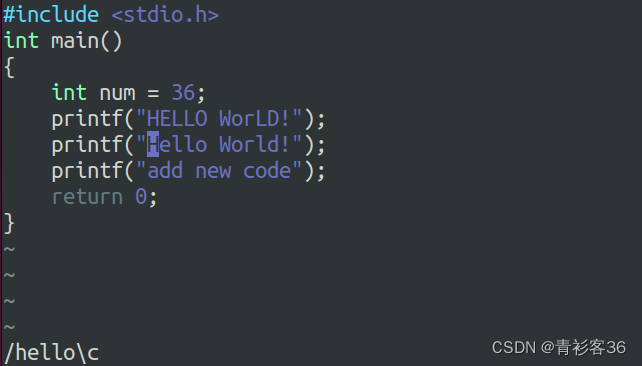
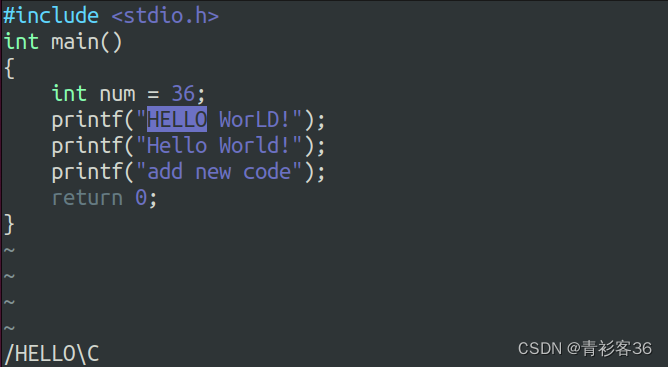
在Vim文本编辑器中可通过底线命令方式:set ignorecase将其设置为忽略大小写,可通过:set noignorecase使其恢复到大小写敏感的状态。Vim文本编辑器默认是大小写敏感的。
类Unix操作系统默认都是大小写敏感的,而Windows操作系统默认是大小写不敏感的。
在Vim文本编辑器中也可以通过\c表示大小写不敏感,\C表示大小写敏感。比如/ignorecase\c,表示可以匹配“ignorecase”、“igNoreCase”和“IgnoreCase”等。
第四关:通配符的基本用法
有时不知道文件的确切字符,就找出所有可能与之相匹配的单词,但如果拼写错误会浪费很长时间。幸运的是,可以使用通配符 "." "+" "*" "?" 查找以节省时间。
- 通配符 “.” 表示将匹配任意一个字符。该通配符也可称之为dot和period。你可以像使用正则表达式中的任何其他字符一样使用通配符。例如,你想匹配“hug”,“huh”,“hut”和“hum”等,可以使用正则表达式hu. 来匹配所有可能得字符串。
- 通配符 “+” 表示查找出现一次或多次的字符。例如要匹配“hahhhhh”,可以使用正则表达式hah+。
- 通配符 “*” 表示匹配零次或多次出现的字符。例如,使用正则表达式hah*可以匹配ha字符串,因为*表示前一个字符出现零次或多次都是符合正则表达式条件的。
- 通配符 “?” 表示指定可能存在的元素,也就是检查前一个元素存在与否,如正则表达式colou?r中的通配符“?” 前面的u字符存在和不存在这两种情况的字符串都符合匹配条件。
简要总结一下:通配符“.” 表示任意一个字符;“?” 表示其前的一个字符是否存在,也就是存在0次或1次;“+”表示前一个字符出现一次或多次;“*” 表示前一个字符出现0次、1次或多次。
如果有指定查找某个字符出现3~5次的情况该怎么办呢?可以使用数量说明符指定下限次数和上限次数。数量说明符使用大括号“{}”,将两个数字放在大括号之间并使用逗号“,”隔开表示字符出现的上限次数和下限次数。
- 要匹配字符串“aaah”中出现3~5次字母a,正则表达式是a{3,5}h。
- 要匹配字符串“haaah”与至少出现3次字母a,正则表达式是ha{3,}h。
- 仅匹配字符串“haaah”(出现3次字母a),正则表达式是ha{3}h。
第五关:匹配具有多种可能性的字符集
前文介绍了如何匹配完整的字符串以及通配符“.” “+” “*” “?” 等,这些只是正则表达式的两种极端情况,一种是查找完整的字符串进行匹配,另一种通过通配符可以匹配任意字符出现零次、一次和多次的方法。
除此之外,我们可以使用字符集来灵活地搜索字符。
- 方括号“[]”用来定义一组你希望匹配的字符。例如,你要匹配"bag","big",“bug”而不是“bog”,此时可以创建正则表达式b[aiu]g来执行此操作。[aiu]是只匹配字符"a" "i" 或 "u"的字符集。
- 连字符“-”用来定义要匹配的字符的范围。当需要匹配一系列字符(例如字母表中的每个字母)时,需要输入很多字符。幸运的是,在字符集中,你可以使用连字符“-”定义要匹配的字符范围。例如匹配小写字母a到e,可以使用[a-e]。使用连字符匹配一系列字符并不只限于字母,也可以匹配一系列数字。例如字符集[0-5]匹配0和5之间的所有数字,包括0和5。
- 字符“^”用来定义不想匹配的字符,称为否定字符集。要创建一个否定字符集,可以在左边的方括号之后放置一个插入字符“^”。例如[^aeiou]表示排除“a” “e” “i” “o” “u”。
如果匹配的可能存在的字符太多,写起来不是很方便,可使用字符集提供的快捷写法。
- \w用来表示匹配字母、数字和下划线,对应的字符集为[A-Za-z0-9_]。这个字符集匹配大小写字母和数字。注意,\w包括匹配下划线。
- \W用来匹配\w匹配的字符集的否定字符集。ps:\W与[^A-Za-z0-9_]相同。
- \d用来搜索数字,其对应的字符集为[0-9]。
- \D用来查找非数字字符,等同于否定字符集[^0-9]。
第六关:贪婪匹配和懒惰匹配
在正则表达式中,可用贪婪(greedy)匹配查找符合正则表达式的字符串的最长的可能字符串,并将其作为匹配结果返回。而懒惰(lazy)匹配是查找符合正则表达式的字符串的最短的可能字符串。
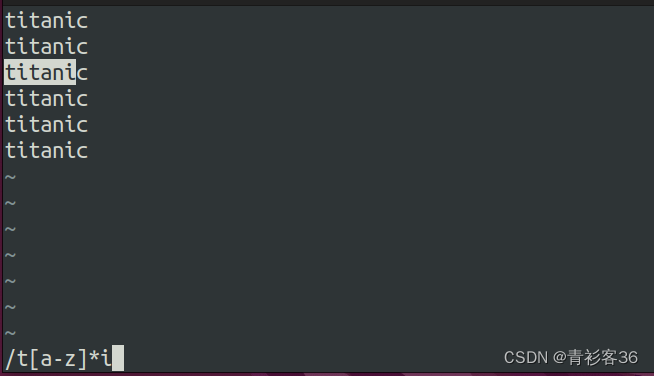
可以用正则表达式t[a-z]*i 查找字符串“titanic”。这个正则表达式基本是以t开始,以i结束的,并且之间有0个或多个字母。正则表达式默认是贪婪匹配,所以将查到最长的字符串"titani"。
但是可以使用?字符将其更改为懒惰匹配。例如使用t[a-z]*?i 正则表达式会返回“ti”。
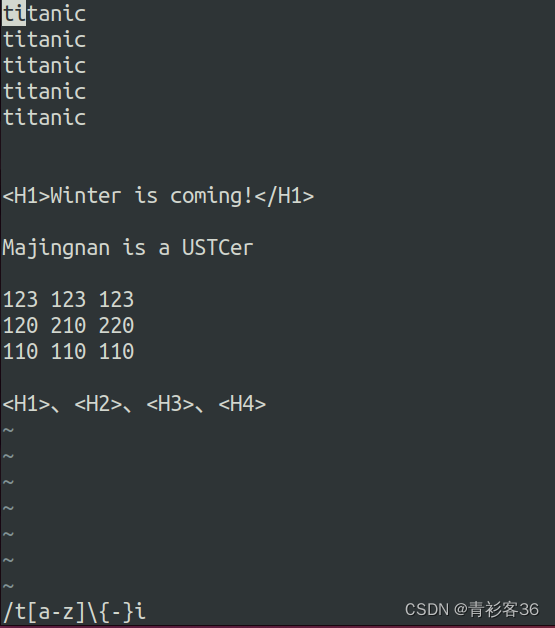
(注意:在perl的正则表达式中表示非贪婪/懒惰匹配, 是在表示匹配个数的元字符后面紧跟着一个? 就可以了, 但是在vim中, 要用 \{-}来表示懒惰匹配。)
也可以在VSCode中使用正则表达式进行搜索,如下图所示。




注意:这时使用字符"?" 表示懒惰匹配,字符“?” 还可以作为通配符,表示检查前一个元素存在与否。
练习:使用懒惰匹配提取HTML中的<h1>标签。

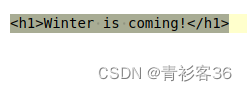

第七关:一些特殊位置和特殊字符
正则表达式具有可用于查找匹配字符串开头和末尾特殊字符和位置的模式。
- 字符“^” 用于表示字符串的开头。
- 字符“$” 用于表示字符串的末尾。
如在“Majingnan is a USTCer”中查找开头的“Majingnan”则为^Majingnan,查找结尾的"USTCer"则为USTCer$。




可以使用\s搜索空格,这个小写的s有“空格”之意。此模式不仅匹配空格,还包括回车符、制表符、换页符和换行符等字符。你可以将其看做与字符集[\r\t\f\n\v]类似。
使用\S搜索非空格。使用它将不再匹配回车符、制表符、换页符和换行符等字符,也可用否定字符集[^\r\t\f\n\v]表示。
- \n:换行符(光标移到下行行首)。
- \r:回车符(光标移到本行行首)。
- \f:换页符。
- \t:水平跳格符(水平制表符)。
- \v:垂直跳格符(垂直制表符)。
第八关:使用捕获组复用模式
正则表达式中的字符串模式多次出现,手动重复输入这些正则表达式是浪费时间的。有一个更好的方法可以用于你的字符串中有多个重复子串时进行指定,这个方法就是捕获组。
用括号"()"可以定义捕获组,用于查找重复的子串,即把会重复的字符串模式的正则表达式放在括号内。
要指定重复字符串出现的位置,可以使用反斜线"\" + 数字的形式。该数字从1开始,并随着用括号定义的捕获组数量而增加。比如\1匹配正则表达式中通过括号定义的第一个捕获组。
使用捕获组来匹配字符串中连续出现3次的数字,每个数字由空格分隔,正则表达式为
(\d+)\s\1\s\1\1代表捕获组(\d+)内正则表达式匹配的结果,而不是正则表达式\d+。因此,这个正则表示可以匹配123 123 123,但是不能匹配120 210 220。(注意:是先捕获后复用,即先执行表达式得到结果之后再复用)


如果正则表达式写成下面这样,就可以匹配这两个字符串了。
(\d+)\s(\d+)\s(\d+)

第九关:基本的字符串搜索替换方法
在Vim文本编辑器中,基本的字符串搜索替换正则表达式为
:n1,n2s/word1/word2/g它以:开头,n1与n2为数字,即在第n1与n2行之间寻找word1这个字符串,并将该字符串替换为word2字符串。举例来说,在第100行到200行之间搜寻regex并将其替换为RegEx的表达式为:
:100,200s/regex/RegEx/g其中s是substitute的简写,表示执行替换字符串操作;最后的/g是global的简写,表示全局替换。另外与/g的用法相似,/c是confirm的简写,表示操作时需要确认,/i是ignorecase的简写,表示不区分大小写。
:1,$s/word1/word2/g或
:$s/word1/word2/g表示从第一行到最后一行寻找word1字符串,并将该字符串替换为word2字符串。
:1,$s/word1/word2/gc或
:$s/word1/word2/gc表示从第一行到最后一行寻找word1字符串,并将该字符串替换为word2字符串,且在替换前显示提示信息给用户确认是否需要替换。
练习一:将titanic全部替换为rose。
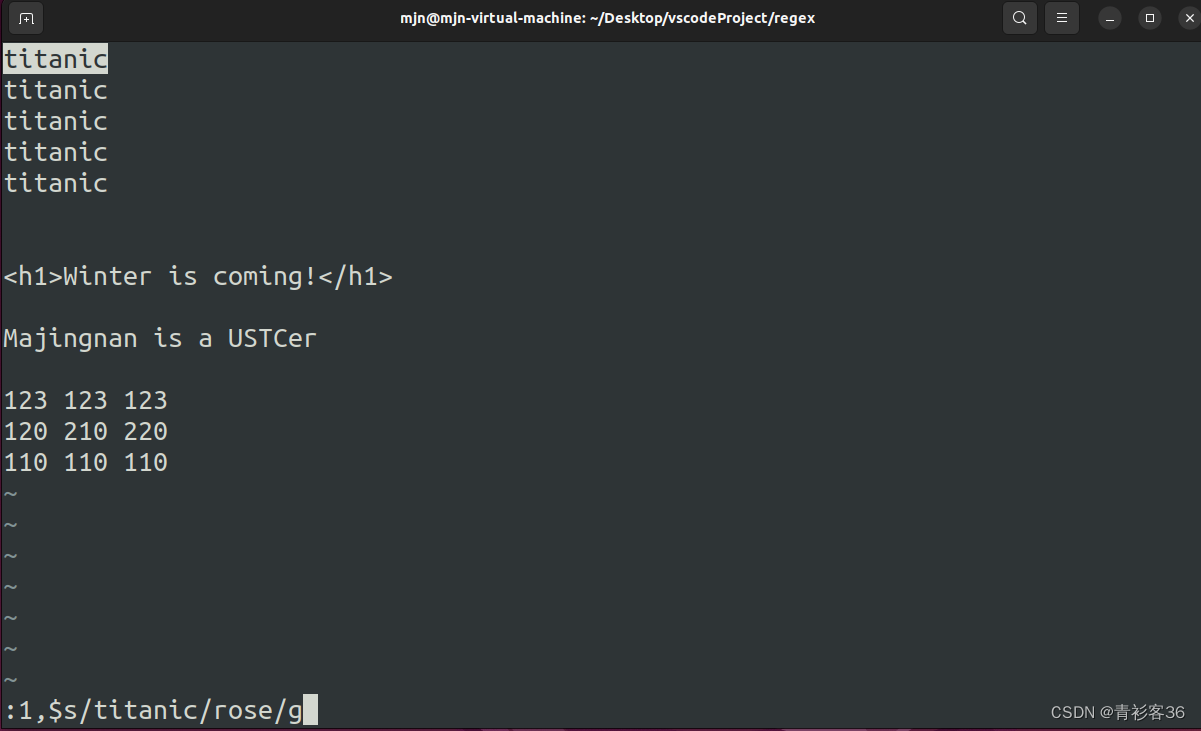
单击Enter键后,
练习二:将rose全部替换为jack,并显示确认信息。
单击Enter键后,弹出提示信息,
输入y即可完成替换(具体为:按一次y就替换一个,按5次就可以将rose全部替换为jack)。
第十关:在替换中使用捕获组复用模式
如果我们在搜索替换中希望保留搜索字符串中的某些字符串作为替换字符串的一部分,可以使用"$"符号访问搜索字符串中的捕获组。
比如,在搜索正则表达式中的捕获组为capture groups,则替换的正则表达式中可以直接使用$1复用搜索正则表达式中的捕获组capture groups。
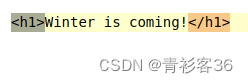
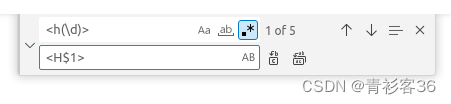
在VSCode中,如果想要把项目中所有的HTML标签中的h改为H,搜索正则表达式<h(\d)>就可以查找出所有标签,如<h1>、<h2>、<h3>、<h4>等,其中还定义了捕获组(\d)。
替换的正则表达式<H$1>使用$1复用了搜索正则表达式中定义的捕获组(\d),如下图所示。


在Vim文本编辑器中,复用捕获组进行替换的格式为:
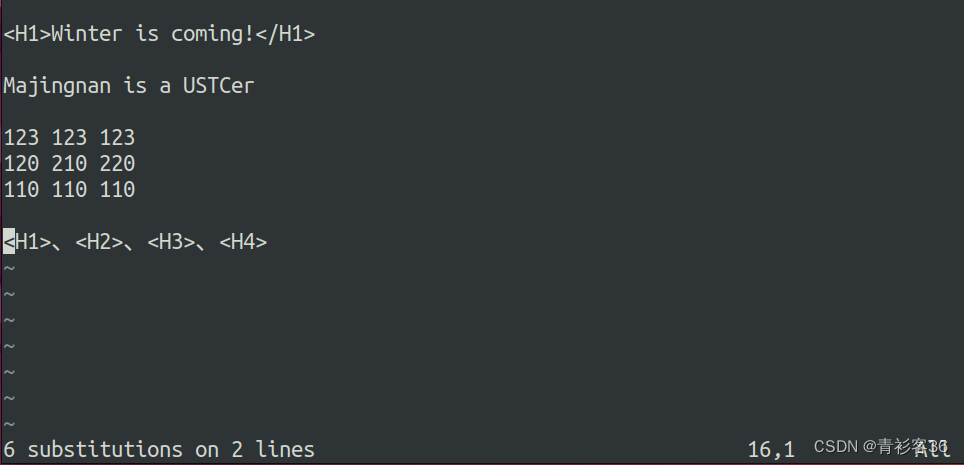
:1,$s/(capture groups)/$1/g如果想在当前文件中将所有的HTML标签中的h改为H,则正则表达式为:
:1,$s/<h\(\d\)>/<H\1>/g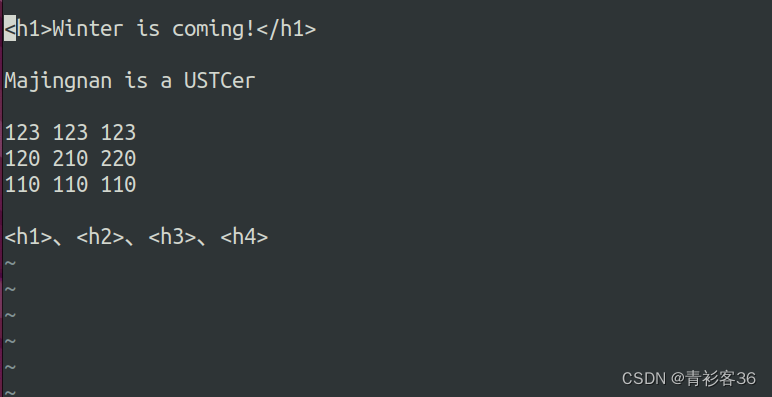
以上内容为中科大软件学院《高级软件工程》课后总结,感谢孟宁老师的倾心教授,老师讲的太好啦(^_^)
参考资料:《代码中的软件工程》 孟宁 编著
















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











