







指令乱序和线程安全
先来看什么是指令乱序问题以及为什么有指令乱序。程序的代码执行顺序有可能被编译器或CPU根据某种策略打乱指令执行顺序,目的是提升程序的执行性能,让程序的执行尽可能并行,这就是所谓指令乱序问题。理解指令乱序的策略是很重要的,因为软件设计人员可以在正确的位置告诉编译器或CPU哪里可以允许指令乱序,哪里不能接受指令乱序,从而在保证软件正确性的同时允许编译或执行层面的性能优化。
指令乱序问题需要分为三个层次:
- 第1层是多线程编程中的业务逻辑层面的函数可重入性和线程安全问题;
- 第2层是编译器编译优化造成的指令乱序;
- 第3层是CPU乱序执行指令的问题。
我们在讨论CPU指令乱序问题和编译器指令乱序问题之前,先来简要讨论一下可重入函数与线程安全相关的问题。
可重入函数与线程安全
线程的基本概念
线程(thread)是操作系统能够进行运算调度的最小单位。它包含在进程之中,是进程中的实际运作单位。一个线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一般默认一个进程中只包含一个线程。
操作系统中的线程概念也被延伸到CPU硬件上,多线程CPU就是在一个CPU上支持同时运行多个指令流,而多核CPU就是在一块芯片上集成了多个CPU核,比如4核8线程CPU芯片就是在集成了4个CPU核,每个CPU核上支持2个线程。
有了多核多线程CPU,操作系统就可以让不同进程运行在不同的CPU核的不同线程上,从而大大减少进程调度进程切换的资源消耗。传统上操作系统工作在单核单线程CPU上是通过分时共享CPU来模拟出多个指令执行流,从而实现多进程和多线程的。
函数调用堆栈框架
借助函数调用堆栈可以将我们写的函数调用代码整理成一个顺序执行的指令流,也就是一个线程,每一个线程都有一个独自拥有的函数调用堆栈空间,其中函数参数和局部变量都存储在函数调用堆栈空间中,因此函数参数和局部变量也是线程独自拥有的。除了函数调用堆栈空间,同一个进程的多个线程是共享其他进程资源的,比如全局变量是多个线程共享的。

可重入函数
可重入(reentrant)函数可以由多于一个任务并发使用,而不必担心数据错误。相反,不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。可重入函数要么使用局部变量,要么在使用全局变量时保护自己的数据。
int g = 0;
int function()
{
g++; /* switch to another thread */
printf("%d", g);
}
int function2(int a)
{
a++;
printf("%d", a);
}
function()函数为不可重入函数,其中的变量g为全局变量,多个线程同时执行function函数时会出现变量g的值未按照预想的结果输出的情况,function2(int a)为可重入函数,function2函数中的变量a是对传入的实参变量的拷贝,并不影响原来传入的变量。
可重入函数的基本要求
(1)不为连续的调用持有静态数据;
(2)不返回指向静态数据的指针;
(3)所有数据都由函数的调用者提供;
(4)使用局部变量,或者通过制作全局数据的局部变量拷贝来保护全局数据;
(5)使用静态数据或全局变量时做周密的并行时序分析,通过临界区互斥避免临界区冲突;
(6)绝不调用任何不可重入函数。
什么是线程安全?
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
函数的可重入性与线程安全之间的关系
可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;同一个可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题;不可重入的函数一定不是线程安全的。
int g = 0;
int plus()
{
pthread_mutex_lock(&gplusplus);
g++; /* switch to another thread */
printf("%d", g);
pthread_mutex_unlock(&gplusplus);
}
int minus()
{
pthread_mutex_lock(&gminusminus);
g--; /* switch to another thread */
printf("%d", g);
pthread_mutex_unlock(&gminusminus);
}
上述两个函数plus() 和 minus() 经过加锁处理之后均称为可重入函数,但由于使用的是两个不同的互斥锁,所以在并发执行时会出现g的值与预期不一致的现象。故说明可重入函数不一定是线程安全的。
线程安全和指令乱序
我们这里讨论可重入函数与线程安全本质上也是指令乱序执行问题,指令乱序问题本质上也是线程安全问题,编译器编译优化或CPU指令乱序执行所引发的程序正确性问题尽管所处的层次不同但本质上与此相似,接下来我们分别讨论一下CPU指令乱序问题和编译器指令乱序问题。
CPU的流水线技术能够让指令的执行尽可能地并行起来,但是如果两条指令前后存在依赖关系,比如数据依赖、控制依赖等,此时后一条指令就必需等到前一条指令完成后才能开始执行。为了提高流水线的运行效率,CPU会对无依赖的前后指令做适当的乱序和调整,对控制依赖的指令做分支预测,对内存访问等耗时操作提前预先处理等,这些都会导致指令乱序执行。
编译器很重要的一项工作就是优化我们的代码以提高性能。这包括在不改变程序正确性的条件下重新排列指令,也就是编译器指令乱序问题。
CPU指令执行的顺序一致性
为了提高流水线的运行效率,CPU会对无依赖的前后指令做适当的乱序和调整,对控制依赖的指令做分支预测,对内存访问等耗时操作提前预先处理等,这些都会导致指令乱序执行。
但是我们编程时一般理解代码在CPU上的执行顺序和代码的逻辑顺序是一致的呀?这有点让人困惑。从单核单线程CPU的角度来看,指令在CPU内部可能是乱序执行的,但是对外表现却是顺序执行的。因为指令集架构(ISA)中的指令和寄存器作为CPU的对外接口,CPU只需要把内部真实的物理寄存器按照指令的执行顺序,顺序映射到ISA寄存器上,也就是CPU只要将结果顺序地提交到ISA寄存器,就可以保证顺序一致性(Sequential consistency)。
多核CPU上指令乱序执行
显然在单核单线程CPU上指令乱序问题被指令集架构所屏蔽,但是在多核多线程CPU上依然存在指令乱序执行的可能性。比如存在变量x = 0,CPU0上执行写入操作x = 1。接着在CPU1上,执行读取操作依然得到x = 0,这在X86和ARM多核CPU上都是可能出现的。原因是如图所示CPU核和Cache以及内存之间,存在着Store Buffer,当x = 1执行写入操作成功后,修改只存在于Store Buffer中,并未写到cache以及内存上,因此CPU1读取不到最新的x值。除了Store Buffer,而且还可能会有Invalidate Queue,导致CPU1读不到最新的x值。为了能够保证多核之间的修改可见性,我们在写程序的时候需要加上内存屏障,例如X86上的mfence指令。
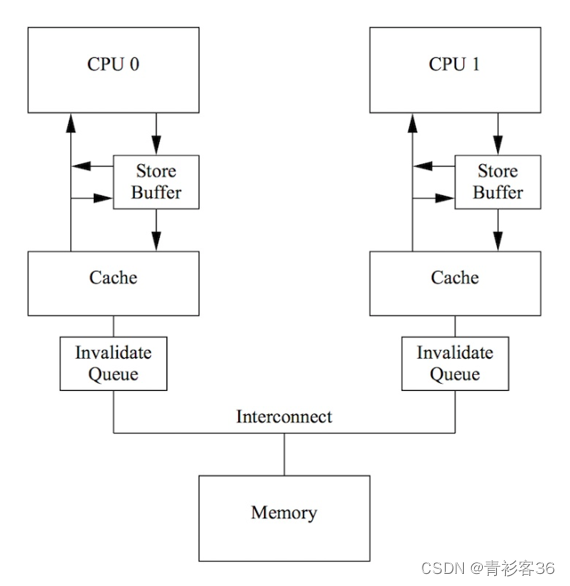
ARM64 CPU指令乱序
对于ARM64架构的CPU来说,编程就变得危险多了。除了存在数据依赖、控制依赖和地址依赖等不能被乱序执行外,其余指令间都有可能存在乱序执行。ARM64上没有依赖关系的读后读、写后写、读后写和写后读都是可以乱序执行的。ARM64架构下Store Buffer并不是FIFO的,而且还可能存在Invalidate Queue,这让并发编程变得困难重重。总之ARM64是弱内存序模型,因为精简指令集把访存指令和运算指令分开了,为了性能允许几乎所有的指令乱序,但前提是不影响程序的正确性。因此ARM64架构的指令乱序问题需要引入不同类型的barrier来保证程序的正确性。
需要特别指出的是ARM64允许指令乱序执行是出于性能的考虑,这是架构特性,不是漏洞。但是指令乱序的影响却给系统可靠性带来了风险,驱动模块、基础软件和应用软件都要做排查和设计优化。
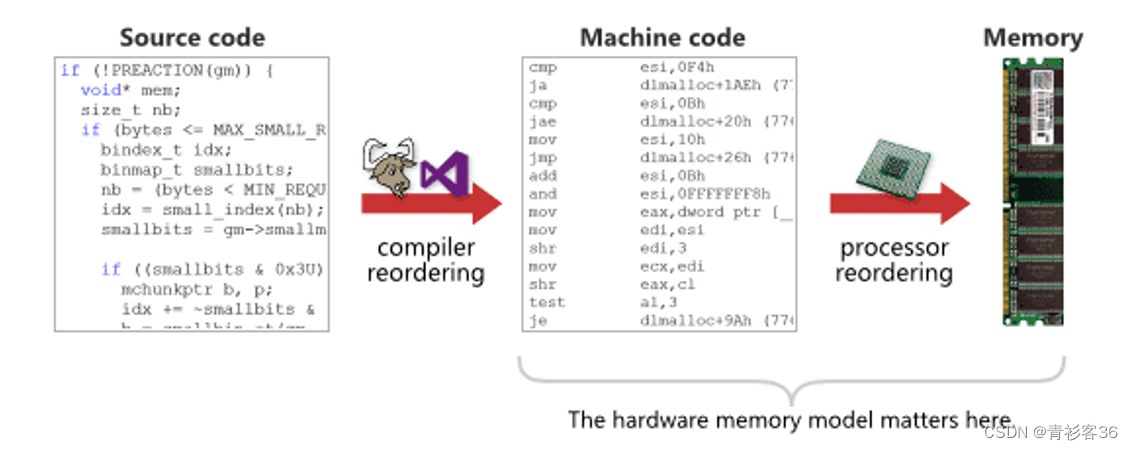
高级语言定义了逻辑关系,逻辑关系与应用程序的业务逻辑有关;编译器将内含逻辑关系的高级语言代码翻译成机器语言或汇编语言,其中就定义了数据依赖、控制依赖和地址依赖等依赖关系;ARMv8架构定义了内存模型以及实现处理这些依赖关系的机器语言指令,从而防止有依赖的指令乱序执行影响程序正确性。
显然CPU指令乱序与硬件内存模型及防止指令乱序的机器语言指令内部实现紧密相关,这些需要深入到处理器微架构深处才能一探究竟,与我们专注于Linux内核的目标不符,这里不再深入探讨它。但是我们需要清楚的一点是,CPU仅能看到机器指令或汇编指令序列中的数据依赖、控制依赖和地址依赖等依赖关系,并不能理解高级语言中定义的逻辑关系,因此CPU指令乱序执行和编译优化指令乱序都可能会破坏高级语言中定义的逻辑关系,这是我们学习指令乱序问题的原因。
编译器指令乱序问题
编译器很重要的一项工作就是优化我们的代码以提高性能。这包括在不改变程序正确性的条件下重新排列指令,也就是编译器指令乱序问题。
因为编译器不知道什么样的代码需要线程安全,所以编译器假设代码都是单线程执行的,也就是编译器对函数的可重入问题是没有感知的,因此编译器进行指令重排优化只能保证是单线程安全。因此当多线程应用程序的逻辑关系在编译器重新排序指令的时候可能影响程序正确性时,除非你显式告诉编译器,我不需要重排指令顺序,否则编译器可能会在优化指令顺序时影响程序的正确性。这一部分我们一起探究编译器编译优化相关的指令乱序问题。
编译器屏障
在阅读Linux内核源代码时,会看到额外插入的汇编指令如下,是告诉编译器不要优化指令顺序。如下代码摘自Linux内核源代码include/linux/compiler-gcc.h。
#define barrier() __asm__ __volatile__("": : :"memory")
如上代码定义的宏barrier()就是常说的编译器屏障(compiler barriers),它的主要用途就是告诉编译器不要优化重排指令顺序。为了说明这个问题我们用C语言代码及对应的ARM64汇编代码简要说明指令乱序造成的问题及编译器屏障的作用。
编译器优化造成指令乱序问题
编译器的主要工作就是将高级语言源代码翻译成机器指令,当然翻译的过程中编译器还会进行编译优化以提高代码的执行效率。编译优化主要就是在不影响程序正确性的情况下对机器指令顺序重排从而统筹调度CPU资源改善程序性能,但是对于多线程应用程序编译器并不能理解程序的并发执行逻辑,很可能会好心干坏事。为了说明编译优化指令乱序造成的问题,我们考虑下面的compiler_reordering.c文件中C语言函数function的代码。
int flag, data;
int function(void)
{
data = data + 1;
flag = 1;
}
编译时未开启编译优化
gcc -S compiler_reordering.c -o compiler_reordering.s
function:
adrp x0, :got:data
ldr x0, [x0, #:got_lo12:data]
ldr w0, [x0] // load data to w0
add w1, w0, 1 // w1 = w0 + 1
adrp x0, :got:data
ldr x0, [x0, #:got_lo12:data]
str w1, [x0] // data = data + 1
adrp x0, :got:flag
ldr x0, [x0, #:got_lo12:flag]
mov w1, 1 // w1 = 1
str w1, [x0] // flag = 1
nop
ret
编译时开启编译优化
gcc -O2 -S compiler_reordering.c -o compiler_reordering_O2.s
function:
adrp x1, :got:data
adrp x3, :got:flag
mov w4, 1 // w4 = 1
ldr x1, [x1, #:got_lo12:data]
ldr x3, [x3, #:got_lo12:flag]
ldr w2, [x1] // load data to w2
str w4, [x3] // flag = 1
add w2, w2, w4 // w2 = w2 + 1
str w2, [x1] // data = data + 1
ret
与上述C语言函数function中的代码比较,这段优化后的ARM64汇编代码的执行顺序是不同的。C代码中是先存储了data的值,后存储了flag的值,而优化后的ARM64汇编代码正好相反,先存储了flag,后保存了data。
这就是编译器指令乱序问题的典型范例。为什么编译器会这么做呢?对于单线程来说,data和 flag的写入顺序,编译器认为没有任何问题的。并且最终的结果data和flag的值也是正确的。
实际上这种编译器指令乱序问题在大部分情况下是没有问题的。但是在某些情况下可能会引入问题。例如我们使用的全局变量flag标记共享数据data是否就绪。另外一个线程检测到flag == 1就认为data已经就绪,而由于编译器指令乱序,实际上data的值可能还没有存入内存。
下面我们加入内存屏障,再来看看编译后产生的汇编文件。
#define barrier() __asm__ __volatile__("": : :"memory")
int flag, data;
int function(void)
{
data = data + 1;
barrier();
flag = 1;
}
function:
adrp x0, :got:data
ldr x0, [x0, #:got_lo12:data]
ldr w1, [x0] // load data to w1
add w1, w1, 1 // w1 = w1 + 1
str w1, [x0] // data = data + 1
adrp x1, :got:flag
mov w2, 1 // w2 = 1
ldr x1, [x1, #:got_lo12:flag]
str w2, [x1] // flag = 1
ret
barrier就是编译器提供的内存屏障,作用是告诉编译器内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,barrier之后的内存操作需要重新从内存加载,而不能使用之前寄存器缓存的值。可以防止编译器优化barrier前后的内存访问顺序。barrier就像是代码中的一道不可逾越的屏障,barrier前的内存读写操作不能跑到barrier后面;同样barrier后面的内存读写操作不能在barrier之前。
以上内容为中科大软件学院《高级软件工程》课后总结,感谢孟宁老师的倾心教授,老师讲的太好啦(^_^)
参考资料:《代码中的软件工程》 孟宁 编著
















 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











