







实验目标
本实验需要用c语言实现一个动态的存储分配器,也就是你自己版本的malloc,free,realloc函数。
实验步骤
tar xvf malloclab-handout.tar解压文件
我们需要修改的唯一文件是mm.c,包含如下几个需要实现的函数
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
mm_init:在调用mm_malloc,mm_realloc或mm_free之前,调用mm_init进行初始化,正确返回0。
mm_malloc:在堆区域分配指定大小的块,分配的空间,返回的指针应该是8字节对齐的
mm_free:释放指针指向的block
mm_realloc:返回指向一个大小为size的区域指针,满足以下条件:
if ptr is NULL, the call is equivalent to mm_malloc(size);
if size is equal to zero, the call is equivalent to mm_free(ptr);
if ptr is not NULL:先按照size指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来ptr所指内存区域

实验验证
mdriver.c:负责测试mm.c的正确性,空间利用率和吞吐量
-f <tracefile>: -f后添加一些trace file来测试我们实现的函数
-V:打印出诊断信息
./mdriver -V -f short1-bal.rep
编程规则
- 不能改变mm.c中函数接口
- 不能直接调用任何内存管理的库函数和系统函数malloc, calloc, free, realloc, sbrk, brk
- 不能定义任何全局或者静态复合数据结构如arrays, structs, trees,允许使用integers, floats, and pointers等简单数据类型
- 返回的指针需要8字节对齐
只要提交mm.c文件
背景知识
在实验开始之前,我想先引入有关brk和sbrk的相关知识作为铺垫,以便于更好地理解本次实验。
brk和sbrk主要的工作是实现虚拟内存到内存的映射。
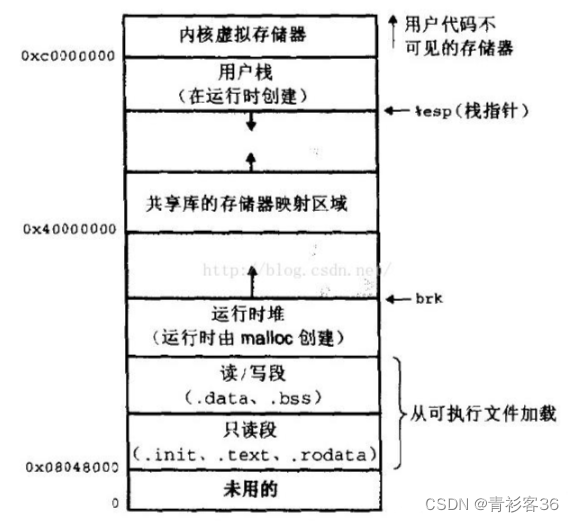
虚拟内存
(1)每个进程都有各自独立的4G 字节的虚拟地址空间(对于X86系统32位而言)。4G的进程空间分为两部分,0~3G-1 为用户空间,3G~ 4G-1 为内核空间。
(2)用户程序中使用的都是虚拟地址空间中的地址,永远无法直接访问实际物理地址。
(3)虚拟内存到物理内存的映射由操作系统动态维护。
(4)虚拟内存一方面保护了操作系统的安全,另一方面允许应用程序使用比实际物理内存更大的地址空间。
(5)用户空间中的代码不能直接访问内核空间中的代码和数据,但是可以通过系统调用进入内核态,间接地与内核交互。
(6)对内存的越权访问,或访问未建立映射的虚拟内存(野指针、不在映射表中),将会导致段错误。
(7)用户空间对应进程,进程一切换,用户空间随即变换。
- 内核空间由操作系统内核使用,不会随进程切换而变化。
- 内核空间由内核根据独立且唯一的页表init_mm.pgd 进行映射,而用户空间的页表则每个进程一份。
(8)每个进程的内存空间完全独立,因此在不同进程之间交换虚拟地址毫无意义。
(9)虚拟内存到物理内存的映射,以页(4096字节)为单位
brk和sbrk的接口
下面是brk和sbrk的声明接口(详情见brk(2) - Linux manual page)
#include <unistd.h>
int brk(void *end_data_segment);
void *sbrk(inptr_t increment);
DESCRIPTION
brk sets the end of the data segment to the value specified by
end_data_segment, when that value is reasonable, the system does have
enough memory and the process does not exceed its max data size (see
setrlimit(2)).
sbrk increments the program's data space by increment bytes. sbrk
isn't a system call, it is just a C library wrapper. Calling sbrk with
an increment of 0 can be used to find the current location of the pro-
gram break.
RETURN VALUE
On success, brk returns zero, and sbrk returns a pointer to the start
of the new area. On error, -1 is returned, and errno is set to ENOMEM.
sbrk不是系统调用,是C库函数。系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能。
Linux中的实现
在Linux系统上,程序被载入内存时,内核为用户进程地址空间建立了代码段、数据段和堆栈段,在数据段与堆栈段之间的空闲区域用于动态内存分配。
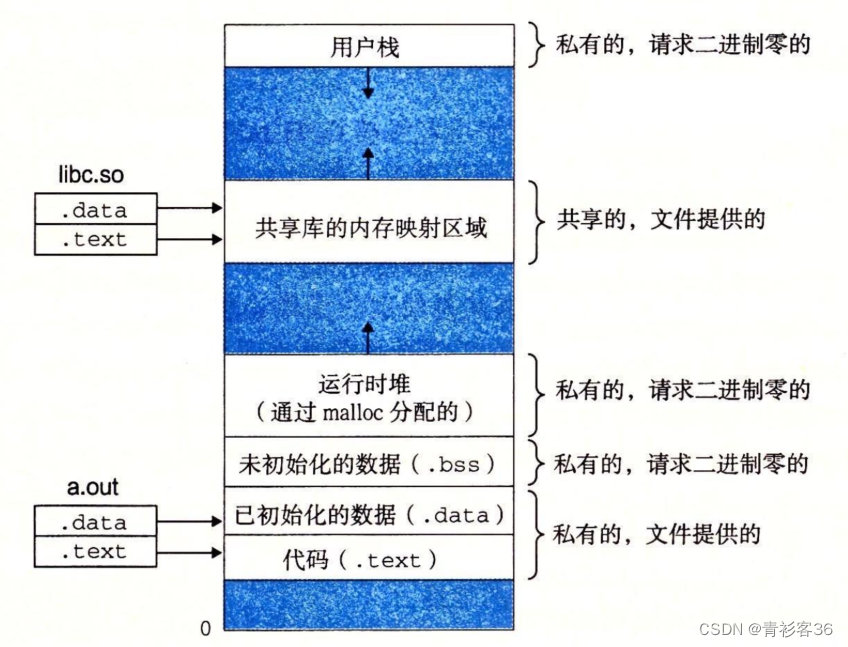
内核数据结构mm_struct中的成员变量start_code和end_code是进程代码段的起始和终止地址,start_data和end_data是进程数据段的起始和终止地址,start_stack是进程堆栈段起始地址,start_brk是进程动态内存分配起始地址(堆的起始地址),还有一个brk(堆的当前最后地址),就是动态内存分配当前的终止地址。
C语言的动态内存分配基本函数是malloc(),在Linux上的基本实现是通过内核的brk系统调用。
brk()是一个非常简单的系统调用,只是简单地改变mm_struct结构的成员变量brk的值。
mmap系统调用实现了更有用的动态内存分配功能,可以将一个磁盘文件的全部或部分内容映射到用户空间中,进程读写文件的操作变成了读写内存的操作。【在linux/mm/mmap.c文件的do_mmap_pgoff()函数,是mmap系统调用实现的核心。】
do_mmap_pgoff()的代码,只是新建了一个vm_area_struct结构,并把file结构的参数赋值给其成员变量vm_file,并没有把文件内容实际装入内存。
Linux内存管理的基本思想之一,是只有在真正访问一个地址的时候才建立这个地址的物理映射。
C语言内存分配方式
(1) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(2) 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3)从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但产生的问题也最多。
C语言跟内存申请相关的函数主要有alloca,calloc,malloc,free,realloc,sbrk等。其中,
- alloca是向栈申请内存,因此无需释放。
- malloc分配的内存是位于堆中的,并且没有初始化内存的内容,因此基本上malloc之后,调用函数memset来初始化这部分的内存空间。
- calloc在堆上分配内存,并初始化所有的字节为 0。
- realloc则对malloc申请的内存进行大小的调整。
- 申请的内存最终需要通过函数free来释放。
- sbrk则是用来增加数据段的大小。
malloc/calloc/free基本上都是C函数库实现的,跟OS无关。C函数库内部通过一定的结构来保存当前有多少可用内存。如果程序malloc的大小超出了库里所留存的空间,那么将首先调用brk系统调用来增加可用空间,然后再分配空间。free时,释放的内存并不立即返回给os,而是保留在内部结构中。可以打个比方:brk类似于批发,一次性的向OS申请大的内存,而malloc等函数则类似于零售,满足程序运行时的要求。这套机制有点类似于缓冲。使用这套机制的原因:系统调用不能支持任意大小的内存分配(有的系统调用只支持固定大小以及其倍数的内存申请,这样的话,对于小内存的分配会造成浪费;系统调用申请内存代价昂贵,涉及到用户态和核心态的转换。)
当程序运行过程中malloc了,但是没有free的话,会造成内存泄漏。一部分的内存没有被使用,但是由于没有free,因此系统认为这部分内存还在使用,造成不断的向系统申请内存,系统可用内存不断减少。但是,内存泄漏仅仅指程序在运行时,程序退出时,OS将回收所有的资源。因此,适当的重新启动一下程序,有时候还是有点作用hh~
实验内容
分配器通过显式空闲列表实现。每个分配的块结构如下:
31 ... 3| 2 1 0
--------------------------------
| 00 ... size (29 bits) | 0 0 a/f| header
| content ... |
| content ... |
| 00 ... size (29 bits) | 0 0 a/f| footer其中高29位表示size,后三位表示是否被分配。
每个空闲块结构都是这样的
31 ... 3| 2 1 0
--------------------------------
| 00 ... size (29 bits) | 0 0 a/f | header
| succ_addr (successor) | succ_addr
| pred_addr (predecessor) | pred_addr
| 00 ... size (29 bits) | 0 0 a/f | footer
--------------------------------注:prev和succ是反着的,因为这样head可以省下一个WSIZE ,也就是说,这个循环链表只是 head.next->...->tail.next->head。所以head.prev 是不需要的,因此4个字节就够了。
/*
* mm.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "memlib.h"
#include "mm.h"
/*
* If NEXT_FIT defined use next fit search, else use first fit search
*/
#define BEST_FIT
/* Team structure */
team_t team = {
/* Team name */
"SA22225284",
/* First member's full name */
"majingnan",
/* First member's email address */
"majingnan36@163.com",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""};
/* 基本常量和宏 */
#define WSIZE 4 /* 字长(字节)*/
#define DSIZE 8 /* 双字大小(字节) */
#define CHUNKSIZE (1 << 12) /* 扩展堆大小(字节) */
#define OVERHEAD 8 /* 头和尾的开销 (bytes) */
#define MAX(x, y) ((x) > (y) ? (x) : (y))
/* 将一个size和分配的位打包成一个字 */
#define PACK(size, alloc) ((size) | (alloc))
/* 在地址 p 读写一个字 */
#define GET(p) (*(size_t *)(p))
#define PUT(p, val) (*(size_t *)(p) = (val))
/* 从地址 p 读取size 分配的字段 */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* 给定块指针 bp,计算其header和footer的地址 */
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* 给定块指针 bp,计算下一个和上一个块的地址 */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
/* 指向第一个块的指针 */
static char *heap_listp; // 堆头
/* 内部辅助function的函数原型 */
static void *extend_heap(size_t words);
static void place(void *bp, size_t asize);
static void *find_fit(size_t asize);
static void *coalesce(void *bp);
/*
这样初始化是为了保证这个链表 有头节点和尾节点,这样我们在删除的时候,就不需要特殊处理。
tail 取 8个字节,是因为我的 prev 放在了后4个字节,tail 需要 prev,所以取8个字节。
head 取4个字节是因为我觉得没有必要维护 head.prev , 也就是说我这个循环链表只是 head.next->...->tail.next->head.
所以head.prev 是不需要的,因此4个字节就够了。
*/
static unsigned int list;
static long long t;
static void *head = &list;
static void *tail = &t;
#define PREV(bp) ((char *)(bp) + WSIZE) // prev 在第二个位置
#define SUCC(bp) ((char *)(bp)) // succ 在第一个位置,即bp的地方
#define GETP(p) (*(char **)p)
#define GET_PREV(bp) (GETP(PREV(bp)))
#define GET_SUCC(bp) (GETP(SUCC(bp)))
#define PUTP(p, val) (*(char **)(p) = (char *)(val))
// 在pos前面插入node
#define insert_before(pos, node) \
{ \
GET_SUCC(GET_PREV(pos)) = (char *)node; /* pos.PREV -> node*/ \
GET_PREV(node) = GET_PREV(pos); /*pos.PREV<-node*/ \
GET_PREV(pos) = (char *)node; /*node<-pos*/ \
GET_SUCC(node) = (char *)pos; /*node->pos*/ \
}
// 从空闲链表中删除pos
#define del(pos) \
{ \
GET_SUCC(GET_PREV(pos)) = GET_SUCC(pos); /*PREV -> NEXT*/ \
GET_PREV(GET_SUCC(pos)) = GET_PREV(pos); /*PREV<-NEXT*/ \
}
// 将bp插入到空闲链表中
#define insertFreeList(bp) \
{ \
char *p = GET_SUCC(head); \
insert_before((p), bp); \
}
#define freeNode(bp) del(bp);
int mm_init(void)
{
GET_SUCC(head) = tail; // 建立链表
GET_PREV(tail) = head;
// 使用 mem_sbrk() 函数获取一块大小为 4 * WSIZE 的空闲空间,并将指针 heap_listp 指向该空间的起始地址。
// 其中 WSIZE 是字(word)的大小,它是对齐的基本单位。
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1)
return -1;
// 在获取到空间之后,代码进行了一些堆的初始化工作。
// 初始化过程需要对齐,因此在堆首部分配2*WSIZE字节的对齐填充,然后将指针heap_listp向右移动DSIZE位,以便让它指向排除对齐填充的内存块的开头。
// 接着,把 prologue 块和 epilogue 块插入到头部和尾部,用于标识整个堆的状态。
PUT(heap_listp, 0); /* alignment padding */
PUT(heap_listp + (1 * WSIZE), PACK(OVERHEAD, 1)); /* prologue header */
PUT(heap_listp + (2 * WSIZE), PACK(OVERHEAD, 1)); /* prologue footer */
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); /* epilogue header */
heap_listp += (2 * WSIZE);
// 一开始会分配64字节的堆空间,用于存储我们的数据。
// 这样,一开始,一个只包含头尾块的堆会被建立,之后其他的空闲块会不断的被分配或者释放到堆中。返回值0表示初始化成功,-1表示失败。
// 经过不断地测试发现64有最高的效率,可以达到90分(best_fit)
if (extend_heap((1 << 6) / DSIZE) == NULL) // 将字节大小转化为doubleword的个数
return -1;
return 0;
}
// malloc, 分配size大小的字节空间,成功返回首地址否则返回NULL
void *mm_malloc(size_t size)
{
// 程序的入口参数size是待申请的内存大小。
// 首先程序根据需要申请的大小size计算出需要分配的块的大小asize。
// 如果size不足以填充一个头部和脚部,则asize根据对齐规则计算得到。
size_t asize; /* adjusted block size */
size_t extendsize; /* amount to extend heap if no fit */
char *bp;
if (size <= 0)
return NULL;
if (size <= DSIZE) // 对齐
asize = DSIZE + OVERHEAD;
else
asize = DSIZE * ((size + (OVERHEAD) + (DSIZE - 1)) / DSIZE);
// 接下来,程序在空闲链表free_listp中查找足够大的空闲块。
// 如果找到了合适的空闲块bp,则将该块分配给请求,并调用place函数将剩余的空间插入到空闲链表中。
// 如果没有找到合适的空闲块,则需要通过调用extend_heap函数来扩展堆,并将扩展的块分配给请求。
if ((bp = find_fit(asize)) == NULL)
{
// 在空闲链表中寻找足够大的块, 找不着则扩大
// MAX(asize, CHUNKSIZE)表示需要扩展的块的大小为asize和CHUNKSIZE中的较大值,CHUNKSIZE为申请新的堆内存块的大小。
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / DSIZE)) == NULL)
return NULL;
}
// place函数根据块的大小将块分为两个部分:一个用于存储请求的数据,另一个部分作为剩余空间插入到空闲链表中。
place(bp, asize);
return bp;
}
// 释放bp所占的内存
void mm_free(void *bp)
{
// 函数首先判断传入的指针是否为空指针,若是则直接返回,不做任何操作。
if (!bp)
return;
// 获取块的大小size,通过HDRP宏获取该块的头部指针,使用PUT和PACK宏将头部和脚部标记为未分配。
size_t size = GET_SIZE(HDRP(bp));
// PUT和PACK宏分别用于在内存中存储和读取数据
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
// coalesce函数用于将释放的空间与相邻的的未分配空间合并。若相邻的空间处于空闲状态,则可以合并成为一个较大的空闲块,放入到空闲链表中进行维护。
coalesce(bp);
}
// 这个函数是将ptr 指向的已分配块, 从oldSize 减小为 newSize
// 它将已经分配的块的剩余空间划分成一个新的空闲块,并更新分配块的大小。
// 该函数主要用于空间分配时,如果总分配空间比当前块的大小大,将当前块切割,剩下的空间分配给其他块。
// 执行内存分配,并更新原分配的块的标志位,并将未使用的空间分割成为一个新的空闲块。
inline static void place_alloc(void *ptr, size_t oldSize, size_t newSize)
{
// 参数ptr指向分配块的起始地址,oldSize为原分配块的大小,newSize为新分配块的大小。
// 利用HDRP和FTRP宏获取ptr指向块的头部和脚部,将它们的标志位设置为已分配的状态,即第0位为1。
PUT(HDRP(ptr), PACK(newSize, 1));
PUT(FTRP(ptr), PACK(newSize, 1));
// 通过NEXT_BLKP宏获取ptr指向块的下一个块的地址,并将该地址赋值给newFreeBlock变量。
// 然后,将newFreeBlock的头部和脚部标记为未分配,即第0位为0,剩余位为oldSize - newSize
void *newFreeBlock = NEXT_BLKP(ptr);
PUT(HDRP(newFreeBlock), PACK(oldSize - newSize, 0));
PUT(FTRP(newFreeBlock), PACK(oldSize - newSize, 0));
// 最后,调用coalesce函数对newFreeBlock进行合并操作
coalesce(newFreeBlock);
}
// 重新扩大大小为newSize
void *mm_realloc(void *ptr, size_t newSize)
{
// 首先,如果newSize为0,则释放ptr指向的块,并返回NULL
if (newSize == 0)
{
mm_free(ptr);
return NULL;
}
// 如果ptr为NULL,则直接调用mm_malloc函数分配新的内存空间。
if (ptr == NULL)
return mm_malloc(newSize);
// 先将newSize对齐
// 如果newSize小于等于DSIZE(16字节),则将其增加为DSIZE+OVERHEAD的大小;
if (newSize <= DSIZE) // 对齐
newSize = DSIZE + OVERHEAD;
else // 否则,将其舍入为DSIZE的倍数加上OVERHEAD大小。
newSize = DSIZE * ((newSize + (OVERHEAD) + (DSIZE - 1)) / DSIZE);
// 获取指针ptr指向的块的大小oldSize,如果oldSize与newSize相等,直接返回ptr指向的块
void *newp;
size_t oldSize = GET_SIZE(HDRP(ptr));
if (oldSize == newSize)
return ptr;
// 如果oldSize大于等于newSize, 缩减,并且缩减之后能多出空闲块,就分割
else if (oldSize >= newSize)
{
// 如果缩减之后分配块仍然大于最小块的大小(即DSIZE+OVERHEAD),则使用place_alloc函数将原来的块重新分配,并返回ptr。
if (oldSize >= newSize + (DSIZE + OVERHEAD))
place_alloc(ptr, oldSize, newSize);
// 如果剩余的内存大小足够重新形成一个大小为newSize的分配块,那么只需要将原先块的大小改变为newSize并分割成为一个新的空闲块,即可满足需要。
return ptr;
}
// 如果以上两个情况都不满足,意味着需要将ptr所指向块的大小扩大到newSize
// 如果ptr所指向的块后面紧跟着一个未分配的块,则考虑将两个块合并并进行分配。
if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))))
{
// 首先获取当前块和下一个块的大小
size_t trySize = GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr)));
// 如果合并后的大小大于等于newSize,则将两个块合并,并通过调用place_alloc函数将新块切割为大小为newSize
if (trySize - newSize >= 0)
{
/* 合并:空闲链表中的free块并设置新块的头尾 */
freeNode(NEXT_BLKP(ptr));
PUT(HDRP(ptr), PACK(trySize, 1));
PUT(FTRP(ptr), PACK(trySize, 1));
if (trySize - newSize >= DSIZE + OVERHEAD)
place_alloc(ptr, trySize, newSize);
return ptr;
}
}
// 如果两个块的合并无法满足需求,只能重新分配一个大小为newSize的新块。
// 调用mm_malloc函数尝试分配一块新的内存,并使用memcpy函数将原来的内存中的数据拷贝到新的内存中。
if ((newp = mm_malloc(newSize)) == NULL)
{
printf("ERROR: mm_malloc failed in mm_realloc\n");
exit(1);
}
memcpy(newp, ptr, oldSize);
// 最后,释放原来的内存,并返回新分配的内存的首地址。
mm_free(ptr);
return newp;
}
// 扩大
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* 分配doubleword以保持对齐方式 最小size是 16字节 即 2 * DSIZE*/
size = (words % 2) ? (words + 1) * DSIZE : words * DSIZE;
// 使用 mem_sbrk 函数,把空闲空间分配给调用者。如果这一步失败了,则函数返回 NULL,表示空间不足。
if ((bp = mem_sbrk(size)) == (void *)-1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
// 初始化空闲块的头和尾,并为堆中的结尾块设置一个新的头。头和尾的大小为8字节,然后把头和尾填入块中的相应位置。
PUT(HDRP(bp), PACK(size, 0)); /* free block header */
PUT(FTRP(bp), PACK(size, 0)); /* free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* new epilogue header */
// 将新分配的块与上一个空闲块合并。返回指向新空闲块的指针。
return coalesce(bp);
}
// 分割出空闲块bp中 大小为asize空间, bp 变为分配块
static void place(void *bp, size_t asize)
{
// 获取空闲块的大小 csize
size_t csize = GET_SIZE(HDRP(bp));
// 调用 freeNode 函数从空闲列表中删除相应的空闲块。因为该空闲块将被分配给用户,所以不再是空闲块
freeNode(bp);
// 检查如果将分配的块放置在该空闲块中,是否会留下一个足够大的空闲块,以便将其添加到空闲列表中。
// 这个检查是用来避免碎片的产生,碎片产生时会浪费内存空间。
// 如果所剩空间大于等于所需的最小空间(即用户请求的大小与头和尾的总大小再加上 OVERHEAD),则将空间分配给用户,并将剩余的空间放回空闲列表。
// 分配的空间大小由 asize 指定。
if ((csize - asize) >= (DSIZE + OVERHEAD))
{
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
insertFreeList(bp); // 加入新的空闲块
}
else // 如果剩余的空间不足以成为一个新的空闲块,则直接将整个空闲块分配给用户, 将空闲块标记为已分配。
{
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
static void *find_first_fit(size_t size);
static void *find_best_fit(size_t size);
static inline void *find_fit(size_t asize)
{
void *bp = find_best_fit(asize);
return bp;
}
// 首次适配
static void *find_first_fit(size_t size)
{
for (void *bp = GET_SUCC(head); bp != tail; bp = GET_SUCC(bp))
{
if (GET_SIZE(HDRP(bp)) >= size)
{
return bp;
}
}
return NULL;
}
// 最佳适配 size 是用户请求的大小
static void *find_best_fit(size_t size)
{
size_t size_gap = 1 << 30;
void *best_addr = NULL, *temp;
// 遍历空闲链表,对于每个块,计算块大小与请求大小之间的差距 size_gap。
for (void *bp = GET_SUCC(head); bp != tail; bp = GET_SUCC(bp))
{
temp = HDRP(bp); // 使用 HDRP 宏来获取当前块的头部指针
// 如果 size_gap 小于先前观察到的最小差距,则更新最佳地址 best_addr 和最小差距 size_gap。
if (GET_SIZE(temp) - size < size_gap)
{
size_gap = GET_SIZE(temp) - size;
best_addr = bp;
// 如果找到一个大小与请求大小相等的块,则直接返回该地址。
if (GET_SIZE(temp) == size)
return best_addr; // 相等就是最佳,可直接返回
}
}
return best_addr;
}
// 这个函数负责加入 新出来的空闲块到显式空闲链表并且合并相邻的空闲块
static void *coalesce(void *bp)
{
// 程序的入口参数bp是待合并的空闲块的指针。首先程序获取了与bp相邻的前后两个块的状态,以及bp块的大小。
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
// 接下来,通过四种情况来讨论相邻的块的状态
size_t size = GET_SIZE(HDRP(bp));
// prev_alloc和next_alloc均为1(即当前块前后均已分配)。
// 此时不需要合并相邻的块,只需要将bp块插入空闲链表。
if (prev_alloc && next_alloc)
{
insertFreeList(bp);
}
// prev_alloc为1,next_alloc为0(即当前块的后面是一个未分配的块)。
// 此时需要将当前块和后面的块合并,然后将合并后的块放入空闲链表中。
// 合并后块的大小,应当为它们本身的大小以及中间的header和footer的大小之和。
else if (prev_alloc && !next_alloc)
{
freeNode(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
insertFreeList(bp);
}
// prev_alloc为0,next_alloc为1(即当前块的前面是一个未分配的块)。
// 此时需要将前面的块和当前块合并,然后返回合并后的块的指针。
// 合并后块的大小,应当为它们本身的大小以及中间的header和footer的大小之和。
else if (!prev_alloc && next_alloc)
{
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
// prev_alloc为0,next_alloc为0(即当前块的前后均未分配)。
// 此时需要将前后两块和当前块合并,然后返回合并后的块的指针。
// 合并后块的大小,应当为它们本身的大小以及中间的header和footer的大小之和。
else
{
freeNode(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
实验结果

笔者才疏学浅,本次实验参考了许多其他博客,笔者对这些博主表示感谢,感谢各位的精彩分享,让我受益良多,谢谢!
参考链接:















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











