









用户文件在Ceph RADOS中存储、定位过程大概包括:用户文件切割成对象、对象映射到PG、PG分组PGP、PG映射到OSD。这些过程中,可能涉及了大量概念和变量,而其实它们大部分是通过HASH、CRUSH等算法计算出来的,初始参数可能也就只有这么几个:用户文件inode、layout、crush_map等。Ceph所有组件和客户端通过计算就能得到所有对象的Location,而且只要输入的参数信息不变,Location就不会变,另外通过PG作为中间层将对象与OSD解绑,使得对象在Ceph RADOS分布更均匀,在OSD增删时,能够保证只有尽可能少的对象发生迁移。在PG、PGP调整或OSD增删后,某些Location发生变化的对象的迁移路线,需要了解各级HASH映射的原理、步骤,更多的计算和分析才能得知。在此基础上才能分析调整PG和PGP对Ceph集群的影响做一些可靠的定性分析,进而指导我们采用更合适的策略去实现Ceph集群的扩容和数据再均衡。
1. 从用户文件到对象
从用户文件到对象的映射过程就是对用户文件进行切割的过程。CephFS会将用户文件按照一定的对象大小进行切割,得到若干对象,OSD负责对象的管理。例如,设定对象大小为4MB,则CephFS按照文件字节逻辑地址将1GB的用户文件切割成1GB/4MB=1024个对象,对象的编号obj_offset取值范围为[0,1024)。Obj_name = FileInode.obj_offset,FileInode为用户文件inode的十六进制码,obj_offset是用户文件被切割后对象的编号,代表用户文件的第几个对象。
如下图所示:

通过Striper::file_to_extents将用户文件内容映射到各对象,参数包括用户文件的布局layout,用户文件内容的字节逻辑地址偏移offset和长度len等。

对象大小是否可配置?
文件布局可以控制如何把文件内容映射到各Ceph RADOS对象,可以使用虚拟扩展属性或xattrs来读、写某一个文件的布局。布局字段包括object_size,但只能在文件size为0的情况下,才能重新配置。
# 通过以下命令读取布局字段:
getfattr -n ceph.file.layout.object_size file
# 通过以下命令修改布局字段:
setfattr -n ceph.file.layout.object_size -v 10485760 file2. 从对象到OSD
从对象到OSD的过程包括:对象名hash、对象到PG、PG分组PGP、PG到OSD等主要过程。这里将以某个cephfs用户文件为例阐述详细的映射过程。
2.1. 创建文件
-
创建一个文件
touch /mnt/cephfs/file002-
查看文件ino
ls -i /mnt/cephfs/file002
1099511876737 /mnt/cephfs/file002-
Ino进制转换
printf "%x\n" 1099511876737
1000003cc81-
查看pool信息
ceph osd pool ls detail
pool 5 'cephfs_data' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1024 pgp_num 1024 last_change 142 flags hashpspool stripe_width 0 expected_num_objects 16986931 application cephfs
pool 7 'cephfs_meta' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1024 pgp_num 1024 last_change 142 flags hashpspool stripe_width 0 expected_num_objects 169869 application cephfs一个pool有pool_id、pool_name、副本数、pg_num、pgp_num等主要信息参数。pg_num和pgp_num调整分析也是本文的主要内容。从pool的详细查询结果可知,5号pool的名字为cephfs_data,采用2副本策略,pg和pgp都为1024。
2.2. 查找零号对象
通过命令可以找到/mnt/cephfs/file002的零号对象存储在哪个OSD上。
ceph osd map cephfs_data 1000003cc81.00000000
osdmap e213 pool 'cephfs_data' (5) object '1000003cc81.00000000' -> pg 5.b184543c (5.3c) -> up ([4,10], p4) acting ([4,10], p4)从以上结果可知,零号对象1000003cc81.00000000存储在pg 5.3c,对应的OSD SET是 [4,10],OSD SET为2副本,pg 5.3c的主副本存储在osd.4中,次副本存储在osd.10中。
2.3. 对象名HASH
pg 5.b184543c是如何组成的?
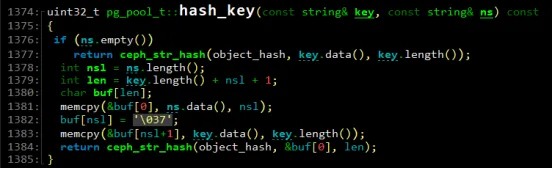
以‘.’为分割符,可以分成两部分5和0xb184543c。5取自pool ‘cephfs_data’的pool_id,而0xb184543是obj_name ‘1000003cc81.00000000’的HASH hex值。
在源码中,HASH函数ceph_str_hash_rjinkins,根据obj_name计算出一个随机值。对于同样的对象名,计算出来的结果永远都是相同的。而对象名字构成中,用户文件inode号保证了不同文件之间的对象名字不同,而obj_offset确保了同一用户文件中不同对象的名字不同。
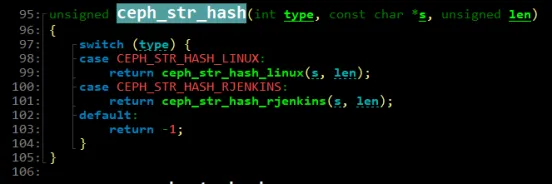
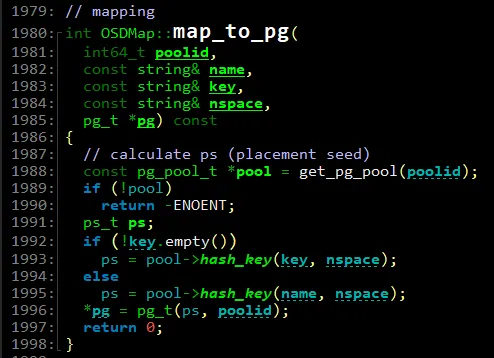
2.4. 从对象到PG
从“pg 5.b184543c (5.3c)”可知,使用的是5号pool,object 1000003cc81.00000000的HASH hex为“0xb184543c”,本文用obj_hash表示,也称为对象的placement seed,此值会被保存在代表pg的类pg_t的对象中,这里简称为pg_seed。
那pg 5.3c为什么只取了object hash hex码的后2两位呢?
是因为5号pool的pg总数为1024个,1024对应0x400,则mask = 0x400 - 1 =0x3ff,因此只需要取0x3ff & b184543c = 0x3c,这样就完成了从对象到PG的映射。最终,一个pg可以表示为pool_id.(mask & obj_hash),一个pool中pg的编号取值范围为[0,mask]。
2.5. PG分组PGP
众所周知,Ceph官方建议一个pool的pg_num = pgp_num,而且为2的幂次方。而说白了,PG分组PGP就是将众多PG分成各个PGP组。在二者相等的情况下,一个PGP中就只有一个PG。
但如果PGP小于PG呢?根据抽屉原理,肯定存在某些PGP分配到了2个或2个以上的PG。这种情况是否存在呢?答案是肯定的,该状态可能只是个中间态,在用户采用了小步调多次调整策略实施PG和PGP的调整,来配合集群OSD添加,最终pg_num会等于pgp_num。
例如,Ceph集群通过增加OSD数量达到扩容的目的,扩容后每个OSD平均承担的PG数量将会小于Ceph官方建议的100~200个,因为在这个取值范围内,集群数据分布均衡度与OSD负载都是比较合适的。因此,扩容后需要相应的调大pg_num和pgp_num,二者的调整是两个独立的顺序操作,因此会存在二者不相等的中间状态。另外,为了保证集群的稳定性,通常是小步调多次的调整pg_num和pgp_num,经过多轮的调整后达到整体调整目标。
这里可能会有一个疑问是,处于相同或不同PGP中的各PG,会有什么联系呢?
答案是,同一个pool中处于相同PGP中的各个PG会被映射到相同的OSD SET,而处于不同PGP中的各个PG一般会被映射到不同的OSD SET,但也不能完全排除被映射到相同OSD SET的可能性,这块的内容涉及到了ceph引以为傲的CRUSH算法,由于本文重点不在此,后期将有专门的文章做介绍。
下图中,ceph_state_mod通过PG的pg_seed与pgp_num_mask按位&,将各PG映射到PGP。
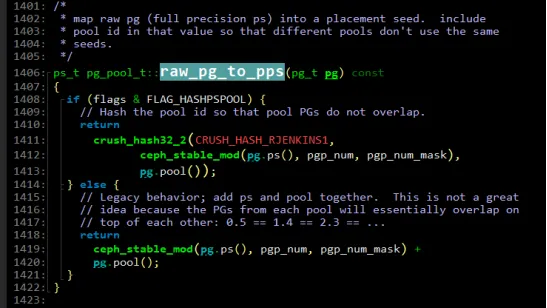


2.6. 从PG到OSD
Ceph数据存储策略有副本和EC两种,本文基于副本策略。用户可以选择2副本、3副本等,副本越多空间利用率就越低,而可靠性就越高,因此需要用户在空间利用率与可靠性二者之间做平衡。多副本情况下,PG到OSD的映射其实是PG到OSD SET的映射,OSD SET的成员个数为副本数,而首成员为主副本,其他成员为次副本,客户端的读写由主副本负责,这块内容涉及到了ceph集群的读写流程,这里不做太详细的介绍,后期文章再做分析。
下图中,_pg_to_raw_osds完成PG到OSD SET的映射,首先调用了pool.raw_pg_tp_pps完成了PG到PGP的分组,会得到分组唯一标识的placement ps即pps。然后,通过crush->find_rule找到pool的ruleno。最后,调用crush->do_rule基于ruleno和pps完成PG到OSD SET的映射。
虽然,两个PG的ps可能不同,但pps可能相同,那映射到的OSD SET就会相同,可以说它们选择了相同的OSD SET来存储数据,也就是说同一个OSD上会承担多个PG,每个OSD上平均承担的PG越多,在非常大量的对象情况下,每个OSD上存储的数据就越均衡。每个OSD上承担的PG越多,OSD管理PG的压力就越大,因此官方对每个OSD平均承担的PG数的合理取值范围为100~200。
CRUSH算法是ceph非常非常引以为傲的的特色,通过它,ceph中的每个组件或客户端都能自己计算出对象到OSD SET的映射,并不需要提供映射表查询的中心节点,从而避免了中心节点的瓶颈问题。本文重点不在CRUSH算法,此处不做详细阐述分析,后期会有单独文章做介绍。
3. 对象文件的命名规则
这里需要说明一下,本文中涉及的对象文件名字与对象名字不同,尽管二者就是同一个对象。对象文件名字指的是对象在linux xfs文件系统中的文件名字。
当前,OSD的两个主要类型为Filestore和Bluestore,本文基于Filestore。Filestore类型的OSD一般利用linux本地文件系统xfs存储和管理对象文件,用户文件被切割成对象文件后,一个对象就对应xfs的一个文件,一个xfs文件通过文件路径Path和文件名FileName定位,举例如下:
/var/lib/ceph/osd/ceph-4/current/5.3c_head/DIR_C/DIR_3/DIR_4/1000003cc81.00000000__head_B184543C__5
该对象文件的Path = “/var/lib/ceph/osd/ceph-4/current/5.3c_head/DIR_C/DIR_3/DIR_4/”,FileName = “1000003cc81.00000000__head_B184543C__5”。
Path也包含了许多含义,ceph-4代表了osd.4,5.3c代表了5号pool中0x3c的pg,这些信息与前面章节一致。而DIR_C、DIR_3和DIR_4是pg dir split的结果,目的是为了保证每个目录中文件数不要过多,xfs某个目录特别大时,对于执行目录的ls等操作不利,而且过大的目录在被读进内存时,会消耗过多的内存,对该目录进行flush时也会花费更多的时间,当然还有其他缺点存在。
不难发现,将“_”作为分隔符,可以将FileName分割成若干部分,1000003cc81.00000000是对象名字,B184543C为对象名字的HASH hex值即pg的ps,5就是pool cephfs_data的号。对象文件名字结构如下所示:
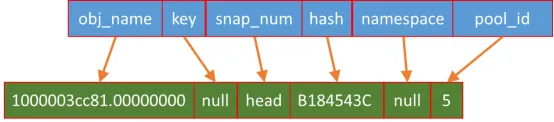
很多组成部分在文章前面已经做了介绍,这里只做以下补充:
-
key和hash不能同时指定,而且常见的是hash;
-
snap_num为head,代表普通对象,否则为snapshot对象。可以给rbd image创建snapshot,这时候底层对象就有snapshot信息了;
-
namespace可以认为是对pool空间的进一步划分,在逻辑上隔离各个用户。一个pool可以划分多个namespace,这些namespace中的对象都使用该pool。尤其应用在ceph rgw服务中。
到此为止,我们已经对用户文件是如何在Ceph中存储的过程有了大概的了解。该过程可以概括为:用户文件切割成对象、对象映射到PG、PG映射到OSD。这个过程中,可能涉及了大量概念和变量,而其实它们大部分是通过HASH、CRUSH等算法计算出来的,初始参数可能也就只有这么几个:用户文件inode、layout、crush_map等,通过计算就能得到所有对象的Location,而且只要输入的参数信息不变,Location就不变,另外通过PG作为中间层将对象与OSD解绑,而且使得对象在ceph RADOS中均匀分布。但本人觉得这也有一点点的小缺点,就是在PG、PGP调整或OSD增删后,某些Location发生变化的对象迁移路线并不是那么直接和直观,需要了解各级HASH映射的原理、步骤,更多的计算和分析才能得知。
4. PG调整的影响
为了简化问题,抓住重点,假设对象的分布如下:

根据文章前面的内容,表格中所有代号都能找到定义和计算方法,这里做一个简单的总结:
-
obj_hash = hash(obj_name);
-
pg_seed = obj_hash;
-
pgId = pg_seed & pg_mask;
-
pgpId = pg_seed & pgp_mask;
4.1. PG非幂次方调整
将pg_num由2调整为3,pgp_num依然为2。调整后,对象的分布如下:
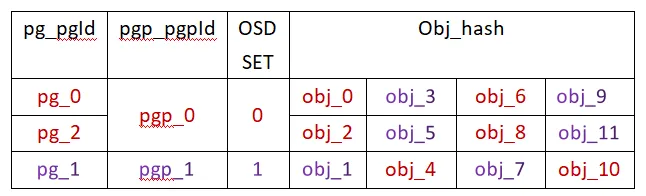
从表中可知:
-
pg_2分担了原属于pg_0的obj_2和obj_8,pg_2与pg_0对应同一个OSD SET,因此obj_2和obj_8只是OSD内部的迁移;
-
pg_2分担了原属于pg_1的obj_5和obj_11,pg_2与pg_1对应不同的OSD SET,obj_5和obj_11涉及到了OSD之间的迁移,不同OSD之间就会有网络通信开销;
-
pg_0分担了原属于pg_1的obj_3和obj_9,也会涉及网络通信开销;
-
pg_1分担了原属于pg_0的obj_4和obj_10,也会涉及网络通信开销。
总之,共涉及OSD内部迁移2次,共涉及OSD之间迁移6次。我们将OSD内部迁移率定义为inter_mig_ratio,将OSD之间迁移率定义为ext_mig_ratio,则计算结果为:
![]()
由于OSD内部迁移,只是将一个对象文件从源目录mv到目的目录,由于源目录与目的目录共享同一个OSD的根目录,因此mv操作只涉及xfs文件系统元数据的更新,不涉及对象文件数据的读取和写入,可以称OSD内部迁移为轻迁移;
而OSD之间迁移,源OSD需要读取对象文件数据,网络通信发送到目的OSD,目的OSD再创建该对象文件,目的OSD写入对象文件数据,源OSD删除该对象文件,称OSD之间迁移为重迁移。
我们将OSD内部一次对象迁移的工作量定义为1,将OSD之间一次对象迁移的工作量定义为4,则总的工作量为:
![]()
因此,inter_mig_ratio反应了轻迁移率,而ext_mig_ratio反应了重迁移率,尽量减少重迁移,降低重迁移率,将重迁移变成轻迁移,最终减少数据迁移对ceph集群整体稳定性和性能的影响。
4.2. PG幂次方调整
将pg_num由2调整为4,pgp_num依然为2。调整后,对象的分布如下:
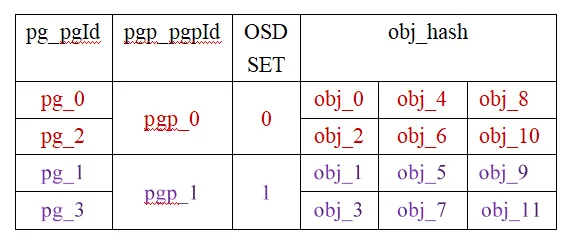
从表中可知:
-
pg_2分担了原属于pg_0的obj_2、obj_6和obj_10,pg_2与pg_0对应同一个OSD SET,因此obj_2、obj_6和obj_10只是OSD内部的迁移;
-
pg_3分担了原属于pg_1的obj_3、obj_7和obj_11,pg_3与pg_1对应同一个OSD SET,因此obj_3、obj_7和obj_11也只是OSD内部的迁移。
总之,共涉及OSD内部迁移6次。
![]()
4.3. PG非幂次与幂次调整对比
| inter_mig_ratio | ext_mig_ratio | work_load | |
| 非幂次(2->3) | 16.67% | 50% | 2.17 |
| 幂次(2->4) | 50% | 0% | 0.5 |
由上表可知,本文中PG非幂次调整引入的工作量远远高于幂次调整引入的工作量,因此建议PG调整最好选择幂次调整,尽量减少PG调整引入的工作量,降低PG调整对ceph集群稳定性和性能的负面影响。
比如,PG由2调整到16,当然可以选择直接调整到目标16,PG调整一步到位。也可以选择小步调多次调整,推荐这样的调整步调2->4->8->16。一步到位的调整策略与小步调多次调整策略各有优缺点,前者实现PG调整一次到位,但单次调整就引入大量的OSD内部迁移,虽然没有OSD之间迁移;后者将单次引入的大量OSD内部迁移分散到了多次调整里,因此单次小步调调整引入的OSD内部迁移相对较少,降低了PG调整对ceph集群稳定性和性能的负面影响,但是由于后者分成多次调整达到最终目标,相对前者会引入额外的中间态OSD内部迁移,因此后者总的OSD内部迁移量会高于前者。因为实践证明,后者的优点大于缺点,因此推荐采用PG小步调多次调整策略。
5. PGP调整的影响
为了简化问题,抓住重点,假设OSD SET只有0和1,对象的分布如下:

5.1. PGP非幂次方调整
将pgp_num由2调整为3,pg_num依然为4。调整后,对象的分布如下:

从表中可知:
-
pgp_2分担了原属于pgp_0的pg_2,而pgp_2使用OSD SET 0,而pg_2原本就使用OSD SET 0,因此这一变动不会有任何数据迁移;
-
pgp_0分担了原属于pgp_1的pg_3,而pg_3对应的OSD SET由1号变成了0号,因此pg_3的所有对象将由OSD SET 0迁移到OSD SET 1,涉及到了OSD之间的迁移,不同OSD之间就会有网络通信开销。
总之,共涉及OSD内部迁移0次,涉及OSD之间迁移6次。则inter_mig_ratio、ext_mig_ratio和work_load为:
![]()
因此,inter_mig_ratio代表了轻迁移率,而ext_mig_ratio代表了重迁移率,尽量减少重迁移,降低重迁移率,将重迁移变成轻迁移,最终减少数据迁移对ceph集群整体稳定性和性能的影响。
5.2. PGP幂次方调整
将pgp_num由2调整为3,pg_num依然为4。调整后,对象的分布如下:

总之,共涉及OSD内部迁移0次,涉及OSD之间迁移0次。则inter_mig_ratio、ext_mig_ratio和work_load为:
通过以上表格发现,虽然pg_2和pg_3对应的pgp有变化,但对应的OSD SET未发生变化,因此该调整,不会发生任何的数据迁移。
![]()
5.3. PGP非幂次与幂次调整对比
PGP调整章节的分析内容仅限于ceph集群OSD SET组合情况未变话,而实际情况导致OSD SET组合情况变更的条件包括:副本策略变化、OSD增减、故障域变更等等。
| inter_mig_ratio | ext_mig_ratio | work_load | |
| 非幂次(2->3) | 0% | 25% | 1 |
| 幂次(2->4) | 0% | 0% | 0 |
由上表可知,PGP幂次调整优于非幂次调整。
6. 疑问和思考
用户文件的对象切割,对象名字的组成部分,对象到PG的映射过程,PG与PGP的关系,PG到OSD的映射过程,最后介绍了PG和PGP幂次和非幂次调整策略对ceph集群稳定性和性能的负面影响分析,但PG和PGP调整最终目标是好的,是为了配合ceph集群OSD扩容,是为了ceph集群数据分布的更均衡和合理,只是在选择PG和PGP调整策略时要有所选择,而并不是盲目的去实施。














 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









