






阅读笔记
创新点:
- 基于层级结构的特征降维方法
- 基于表情符号的特征极性值计算
- 基于特征极性值的位置权重计算
1. 词典的构建
- 情感词典的构建:
《学生褒贬义词典》中的正负情感词,《知网》提供的正负情感词以及搜狗实验室提供的互联网词库SogouW 合并去重 得到本文所需的情感词典MD - 极性副词词典的构建:
1.郝雷红. 现代汉语否定副词研究 中对否定副词范围界定的基础上,加入了若干否定副词
2.采用 蔺璜 程度副词的特点范围与分类 对程度副词范围的界定构建极性程度副词词典 - 表情符号词典的构建:
借助新浪微博中的表情符号构建表情符号词典,并根据表情符号表达的情感倾向性将其分为正向和负向两类。
2.词典与机器学习相结合的微博文本情感分析
-
基于层次结构的特征降维方法:
采用 χ2统计法进行特征选择,初步降低特征空间的维数,借助层次聚类算法(将向量空间分为褒义,贬义和中性三个子空间分别进行聚类,再将三个子空间聚类结果合并在一起)对特征空间进行降维,进一步降低特征空间的维数,最终达到特征降维的目的。 -
基于表情符号的特征极性值计算:

其中pN为正向表情符号的数目,nN为负向表情符号的数目,E(ti)为极性特征 ti的极性值(一个极性特征在一个文本中可能出现若干次,每次出现时,其前面的极性副词及极性副词之间的顺序都不尽相同,导致每次计算得到的极性值都有所不同每次计算得到的极性值的算术平均值作为该极性特征的最终极性值), 基于词典的中文倾向性分析报告 张成功,刘培玉,朱振方,等给出关于极性短语的计算值计算方法 -
基于极性特征性值的位置权重计算:
TF-IDF归一化公式:
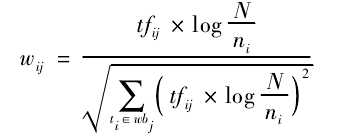
因为微博中首句、尾句对整条微博文本极性的贡献相对较大,故引入位置系数pwr:计算特征权重时,每部分赋予一定的权值 pwr,用于体现该部分的特征对微博文本的贡献程度;
简单的词频统计来计算特征项的权重,而忽略了特征项本身的极性,然而特征项本身的极性通常反映了作者的观点,故引入特征项的极性值IE(ti)·作为权重计算的一部分
最终的基于特征极性值的位置权重计算方法为:
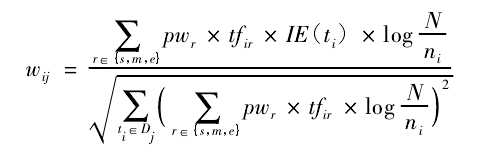
-
情感分类算法:借助SVM















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









