







MySQL常见函数
sql的函数类似于c++的函数,将一组逻辑语句封装在函数体中,只对外展示函数名,提高代码重用性
调用:select 函数名 (实参列表) [from 表];
from 表 是实参列表中的字段所在的表。
常见函数可分为:
单行函数:如concat、length、ifnull等。
分组函数:主要做统计使用,又叫做统计函数、聚合函数或组函数。
一.单行函数
又分为:
字符函数
数学函数
日期函数
其他函数
流程控制函数
字符函数
-
length():获取参数值的字节个数:
select length() from 表; -
concat():拼接字符串:
select concat(expr1,expr2,...) from 表; -
upper(), lower():改变参数的大小写:
select upper();
select lower(); -
substr(),substring():截取字符:
select substr(str,pos);select substr(str, pos, len)
select substr('abcdefg',3);
输出的是'cdefg'
select substr('abcdefg',3,2);
输出的是cd
注意:这里的索引是从1(不是0)开始的。 -
instr():返回子串第一次出现的索引,如果没有,返回0。
select instr('abcdef','cde');------------->输出为3。 -
trim():去掉前后空格或者去除前后指定字符。
select trim('a' from 'aaaaa有效字符aaaaaaa');---->输出为有效字符 -
lpad():用指定的字符实现左填充到指定的长度:
select lpad('abcde',10,'*');----->*****abcde
如果是:select lpad('abcde',5,'*')
因为'abcde'长度就为5,因此不用填充,结果为:abcde
如果是:select lpad('abcde',2,'*')
因为'abcde'长度大于2,因此要从右边删掉多余的,结果为:ab
相似的,rpad()就是实现右填充。 -
replace():替换。
比如说使用
select replace('灰太狼喜欢吃喜羊羊','懒羊羊');
就可以实现将灰太狼喜欢吃喜羊羊改为灰太狼吃懒羊羊。
数学函数
- round():四舍五入
- ceil():向上取整
- floor():向下取整
- truncate():截断
select truncate(1.69999,1);,意思是将1.69999截断保留1位小数,结果为1.6 - mod():取余
日期函数
- now():返回当前系统日期+时间。
- curdate():返回当前系统日期,不包含时间。
- curtime():返回当前系统时间,不包含日期。
如果想获得指定部分,年year(),月month()\monthname(),日day(),时hour(),分minute(),秒second()
- str_to_date():将日期格式的字符转换为指定格式的日期。
select str_to_date('3-14-2022','%m-%d-%Y');
(按照指定的格式解析日期)
%Y----四位的年份%y----两位的年份%m----月份(01,02,...,12)
%c----月份(1,2,...,12)%d----日(01,02,...)%H----小时(24小时制)
%h----小时(12小时制)%i----分钟(00,01,...)%s----秒(00,01,...) - date_format():将日期转化为字符。
其他函数
- version()
- database()
- user()
流程控制函数
-
if函数:类似于if else的效果。
select if(epr1,p1,p2);如果epr1成立,则返回p1,否则返回p2。 -
case函数:
case函数既可以和select语句一块用,也可以单独作为语句使用。
与select连用时:
2.1.类似于 switch case的效果case 要判断的字段或表达式 when 常量1 then 要显示的值1或语句1; when 常量2 then 要显示的值2或语句2; ... else 要显示的值n或语句n; end2.2类似于多重if的效果
case when 条件1 then 要显示的值1或语句1 when 条件2 then 要显示的值2或语句2 ... else 要显示的值n或语句n end查询员工工资情况,如果工资>20000,显示A级别,如果工资>15000,显示B级别,否则显示C。
select salary case when salary>20000 then 'A' when salary>15000 then 'B' else 'C' end as 工资级别 from employees;不与select连用的情况后期会慢慢总结。。。
二.分组函数
用作统计使用。
分类:
sum求和、avg平均值、max最大值、min最小值、count计算个数。
- 简单实用
select sum(scores) from 成绩;
select max(scores) from 成绩;
select min(scores) from 成绩;
select avg(scores) from 成绩;
他们亦可以一块使用:
select sum(scores) as 总分, max(scores) as 最高分, min(scores) as 最低分 from 成绩; - 参数支持哪些类型
2.1 sum、avg一般处理数值型,max、min、count可处理任何类型的值
2.2 sum、avg、max、min、count都忽略null值
2.3 可以和distinct搭配实现去重的运算。
2.4 注意,和分组函数一同查询的字段要求是group by后的字段。
#分组查询
select 分组函数,列(要求出现在group by的后边) from 表 [where 筛选条件] [group by 分组的列表] [order by...];
分组查询中的筛选条件分为两类:
1.分组前筛选—数据源是原始表—筛选在group by之前—关键字是where
2.分组后筛选—数据源是分组后的结果—筛选放在group by之后—关键字是having
分组函数作条件肯定是放在having子句中。
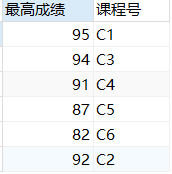
案例:在学习成绩表中,查找出每门课程的最高成绩以及对应课程的课程号:
select max(成绩) as 最高成绩,课程号 from 学习 group by 课程号;
结果:
having:对分组后的数据进行条件筛选
假如我们要统计选课人数大于2的课程的课程号,需要分两步:
1.查看每门课程的选课人数。
2.从中选出人数大于2的选课人数。
分析问题后我们可能会写出这样的语句:
select 课程号,count(*) as 人数 from 学习 where count(*)>2 group by 课程号;
这样运行之后我们发现结果报错:invalid use of group function。
报错原因就是:
where是对数据库分组前的数据进行条件筛选,where处理的对象是每一行的数据
因此,我们引入一个新的关键字:having
having是对分组后的数据进行条件筛选,处理的对象是每一组数据
则代码可以改为:
select 课程号,count(*) as 人数 from 学习 group by 课程号 having count(学号)>2;
按表达式或函数分组
案例:按学生姓名的长度分组,查询每一组的学生人数,筛选学生个数>3的又哪些:
select length(姓名) as len,count(*) as 人数 from 学生 group by length(姓名) having count(*)>3;
按多个字段分组
把多个字段都放在group by后边,用逗号隔开,没有顺序要求。
添加排序
在整个查询语句中后边加上 order by语句。















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









