批量读取
import pandas as pd
from functools import reduce
import os
data1 = pd.read_csv('/Users/bella/Downloads/20210125_video_offline_userid_uniq.txt',header=None)
data2 = pd.read_csv('/Users/bella/Downloads/20210127_video_offline_userid_uniq.txt',header=None)
data3 = pd.read_csv('/Users/bella/Downloads/20210201_video_offline_userid_uniq.txt',header=None)
data4 = pd.read_csv('/Users/bella/Downloads/20210205_videooffline_userid_uniq.txt',header=None)
data5 = pd.read_csv('/Users/bella/Downloads/20210209_video_offline_userid_uniq.txt',header=None)
dfs = [data1,data2,data3,data4,data5]
offline = pd.concat(dfs,axis=0)
offline = offline.rename(columns={0:'offline_user_id'})
offline.head()
ups = pd.DataFrame(columns=['date','user_id'])
test = pd.DataFrame(columns=['date','user_id'])
dir = '/Users/bella/Downloads/20210120_20210213_video_publisher'
for info in os.listdir(dir):
test = pd.read_csv(dir+'/'+info)
test['date'] = info[:8]
ups = pd.concat([test,ups],sort=False)
韦恩图
from matplotlib_venn import venn2, venn2_circles
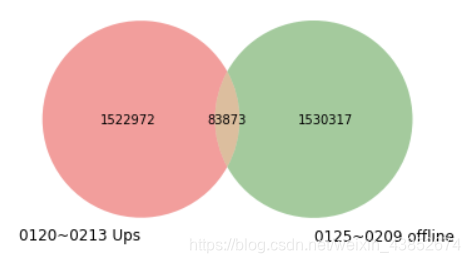
up_num = ups_all.shape[0]
offline_num = offline.shape[0]
inner = inner_df.shape[0]
venn2(subsets=(up_num,offline_num,inner), set_labels=('0120~0213 Ups', '0125~0209 offline'))























 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









