







XPath,全称XML Path Language ,即XML路径语言,它是一门在XML文档中查找信息的语言,。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath常用规则
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
示例://title[@lang="eng"]
他代表选择所有名称为title,同时属性ang的值为eng的节点
实例引入
通过实例来感受一下使用XPath来对网页进行解析的过程
首先导入lxml的etree模块,然后声明一段HTML文本,调用HTML类进行初始化,这样就可以创建一个XPath解析对象。文本中也能标签有的没有闭合,或者不够完整,可使用tostring()方法就可输出修正后的HTML代码,但是结果返回的是bytes类型,需要使用decode()方法将其转成str类型


在上边的运行中,可以看到个别标签被补全,还添加了html,body节点
除此之外,还可以直接读取文本文件进行解析,使用etree.parse


可以看到,这次输出的结果中会多一个doctype的声明,不过对解析没有影响,
表示回车符
使用XPath选取所有的节点


上边所写到的*,代表匹配所有的节点,可以看到节点中返回形式是一个列表,每个元素都是Element类型,后面跟了节点的名称
获取指定的节点,获取所有的li节点,直接在//下写上节点名称即可


获取子节点使用 / 和子孙节点使用 //


查找父节点,使用.. 查找属性值使用@,或者是使用parent::*获取父节点


属性匹配,可以使用@进行属性匹配

因为这文本中,class="item-0"的li节点有两个,所以输出结果为两个

文本获取,使用text()方法获取节点中的文本
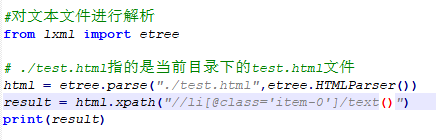

通过上边的输出结果可以看到,我们获取到的内容为换行符,这是因为text()前面使用的是/,表示的是子节点,但是li的子节点中是a节点,没有内容,内容都在a节点里面,所以这里匹配到的结果是被修正后的li节点内部的换行符。可以使用如下方式进行匹配:


属性获取

属性多值匹配


如果想要匹配到内容,可使用如下:


多属性值的匹配

按序查找
有时候,我们再选择的时候某些属性可能同时匹配了多个节点,但是只想要其中的某个节点,如果第二个节点或者最后一个节点
这时候可以利用中括号传入索引的方法获取特定次序的节点,示例如下:


获取所有祖先节点


















 3938
3938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









